 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Location-Robust Respiratory Waveform Monitoring with Single-Antenna WiFi
Apr 22, 2026In recent years, WiFi sensing has been recognized as a promising technology to bring respiratory monitoring into everyday homes, thanks to its contactless nature and ubiquitous availability. However, existing WiFi-based respiratory monitoring systems still fall short of deployment-oriented performance: they suffer from restrained hardware scalability, limited accuracy, and are highly sensitive to user location. To overcome these limitations and push WiFi sensing towards clinically meaningful precision, we propose RespirFi, a novel system that robustly delivers high-fidelity respiratory waveforms with WiFi Channel State Information (CSI), thereby enabling accurate estimation of key physiological biomarkers. At the core of RespirFi is a theoretical human reflection model, through which we perform an in-depth characterization of how CSI variations are shaped by both subcarrier frequency and spatial user location. Guided by these insights, we develop a location-robust waveform construction method that adaptively selects high quality subcarriers and aligns their waveform trends, ensuring accurate waveform recovery. Furthermore, we propose a breathing phase identification method that leverages inter-subcarrier CSI differences to reliably distinguish inhalation from exhalation. We implement RespirFi over commodity WiFi devices, and extensive experiments demonstrate that it outperforms state-of-the-art approaches across a wide range of clinically relevant respiratory metrics.
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
MobiDiary: Autoregressive Action Captioning with Wearable Devices and Wireless Signals
Jan 13, 2026Human Activity Recognition (HAR) in smart homes is critical for health monitoring and assistive living. While vision-based systems are common, they face privacy concerns and environmental limitations (e.g., occlusion). In this work, we present MobiDiary, a framework that generates natural language descriptions of daily activities directly from heterogeneous physical signals (specifically IMU and Wi-Fi). Unlike conventional approaches that restrict outputs to pre-defined labels, MobiDiary produces expressive, human-readable summaries. To bridge the semantic gap between continuous, noisy physical signals and discrete linguistic descriptions, we propose a unified sensor encoder. Instead of relying on modality-specific engineering, we exploit the shared inductive biases of motion-induced signals--where both inertial and wireless data reflect underlying kinematic dynamics. Specifically, our encoder utilizes a patch-based mechanism to capture local temporal correlations and integrates heterogeneous placement embedding to unify spatial contexts across different sensors. These unified signal tokens are then fed into a Transformer-based decoder, which employs an autoregressive mechanism to generate coherent action descriptions word-by-word. We comprehensively evaluate our approach on multiple public benchmarks (XRF V2, UWash, and WiFiTAD). Experimental results demonstrate that MobiDiary effectively generalizes across modalities, achieving state-of-the-art performance on captioning metrics (e.g., BLEU@4, CIDEr, RMC) and outperforming specialized baselines in continuous action understanding.
Invisible Walls: Privacy-Preserving ISAC Empowered by Reconfigurable Intelligent Surfaces
Jan 08, 2026The environmental and target-related information inherently carried in wireless signals, such as channel state information (CSI), has brought increasing attention to integrated sensing and communication (ISAC). However, it also raises pressing concerns about privacy leakage through eavesdropping. While existing efforts have attempted to mitigate this issue, they either fail to account for the needs of legitimate communication and sensing users or rely on hardware with high complexity and cost. To overcome these limitations, we propose PrivISAC, a plug-and-play, low-cost solution that leverages RIS to protect user privacy while preserving ISAC performance. At the core of PrivISAC is a novel strategy in which each RIS row is assigned two distinct beamforming vectors, from which we deliberately construct a limited set of RIS configurations. During operation, exactly one configuration is randomly activated at each time slot to introduce additional perturbations, effectively masking sensitive sensing information from unauthorized eavesdroppers. To jointly ensure privacy protection and communication performance, we design the two vectors such that their responses remain nearly identical in the communication direction, thereby preserving stable, high-throughput transmission, while exhibiting pronounced differences in the sensing direction, which introduces sufficient perturbations to thwart eavesdroppers. Additionally, to enable legitimate sensing under such randomized configurations, we introduce a time-domain masking and demasking method that allows the authorized receiver to associate each CSI sample with its underlying configuration and eliminate configuration-induced discrepancies, thereby recovering valid CSI. We implement PrivISAC on commodity wireless devices and experiment results show that PrivISAC provides strong privacy protection while preserving high-quality legitimate ISAC.
DeepGuard: Defending Deep Joint Source-Channel Coding Against Eavesdropping at Physical-Layer
Dec 21, 2025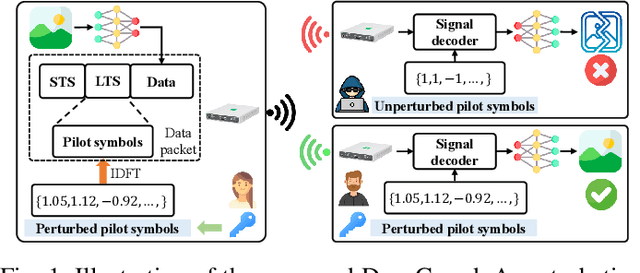
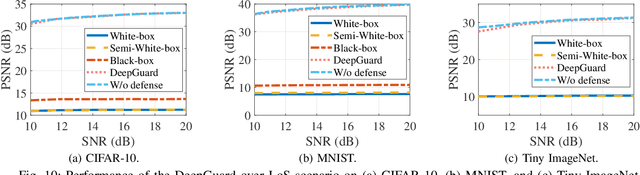
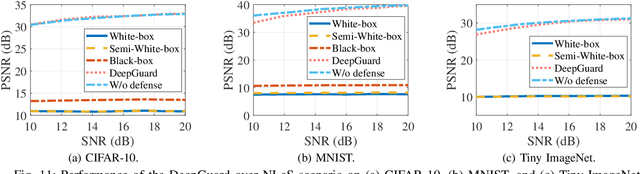

Deep joint source-channel coding (DeepJSCC) has emerged as a promising paradigm for efficient and robust information transmission. However, its intrinsic characteristics also pose new security challenges, notably an increased vulnerability to eavesdropping attacks. Existing studies on defending against eavesdropping attacks in DeepJSCC, while demonstrating certain effectiveness, often incur considerable computational overhead or introduce performance trade-offs that may adversely affect legitimate users. In this paper, we present DeepGuard, to the best of our knowledge, the first physical-layer defense framework for DeepJSCC against eavesdropping attacks, validated through over-the-air experiments using software-defined radios (SDRs). Considering that existing eavesdropping attacks against DeepJSCC are limited to simulation under ideal channels, we take a step further by identifying and implementing four representative types of attacks under various configurations in orthogonal frequency-division multiplexing systems. These attacks are evaluated over-the-air under diverse scenarios, allowing us to comprehensively characterize the real-world threat landscape. To mitigate these threats, DeepGuard introduces a novel preamble perturbation mechanism that modifies the preamble shared only between legitimate transceivers. To realize it, we first conduct a theoretical analysis of the perturbation's impact on the signals intercepted by the eavesdropper. Building upon this, we develop an end-to-end perturbation optimization algorithm that significantly degrades eavesdropping performance while preserving reliable communication for legitimate users. We prototype DeepGuard using SDRs and conduct extensive over-the-air experiments in practical scenarios. Extensive experiments demonstrate that DeepGuard effectively mitigates eavesdropping threats.
Meta-SimGNN: Adaptive and Robust WiFi Localization Across Dynamic Configurations and Diverse Scenarios
Nov 18, 2025To promote the practicality of deep learning-based localization, existing studies aim to address the issue of scenario dependence through meta-learning. However, these studies primarily focus on variations in environmental layouts while overlooking the impact of changes in device configurations, such as bandwidth, the number of access points (APs), and the number of antennas used. Unlike environmental changes, variations in device configurations affect the dimensionality of channel state information (CSI), thereby compromising neural network usability. To address this issue, we propose Meta-SimGNN, a novel WiFi localization system that integrates graph neural networks with meta-learning to improve localization generalization and robustness. First, we introduce a fine-grained CSI graph construction scheme, where each AP is treated as a graph node, allowing for adaptability to changes in the number of APs. To structure the features of each node, we propose an amplitude-phase fusion method and a feature extraction method. The former utilizes both amplitude and phase to construct CSI images, enhancing data reliability, while the latter extracts dimension-consistent features to address variations in bandwidth and the number of antennas. Second, a similarity-guided meta-learning strategy is developed to enhance adaptability in diverse scenarios. The initial model parameters for the fine-tuning stage are determined by comparing the similarity between the new scenario and historical scenarios, facilitating rapid adaptation of the model to the new localization scenario. Extensive experimental results over commodity WiFi devices in different scenarios show that Meta-SimGNN outperforms the baseline methods in terms of localization generalization and accuracy.
Sensing Framework Design and Performance Optimization with Action Detection for ISCC
May 05, 2025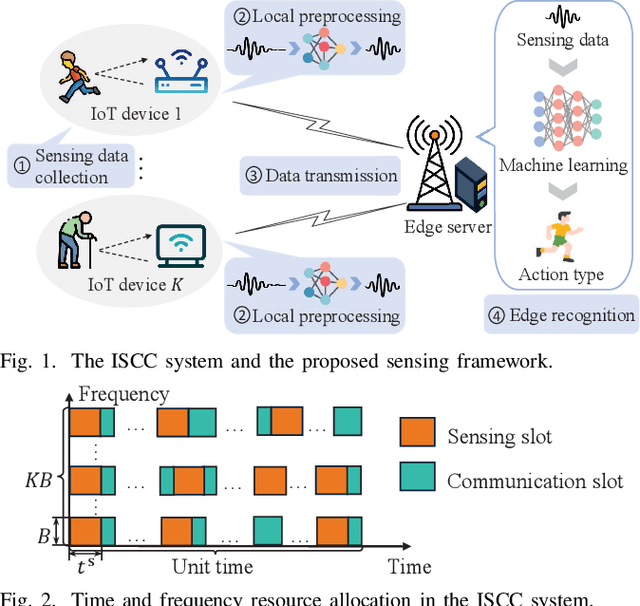
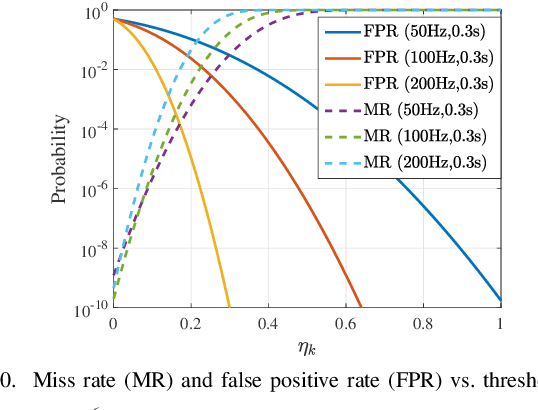
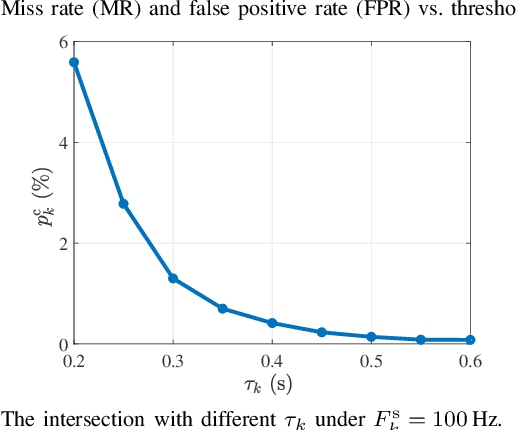
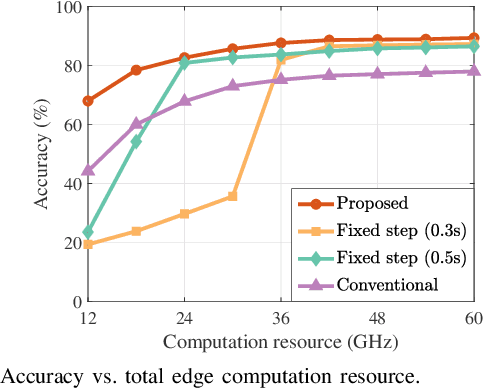
Integrated sensing, communication, and computation (ISCC) has been regarded as a prospective technology for the next-generation wireless network, supporting humancentric intelligent applications. However, the delay sensitivity of these computation-intensive applications, especially in a multidevice ISCC system with limited resources, highlights the urgent need for efficient sensing task execution frameworks. To address this, we propose a resource-efficient sensing framework in this paper. Different from existing solutions, it features a novel action detection module deployed at each device to detect the onset of an action. Only time windows filled with signals of interest are offloaded to the edge server and processed by the edge recognition module, thus reducing overhead. Furthermore, we quantitatively analyze the sensing performance of the proposed sensing framework and formulate a sensing accuracy maximization problem under power, delay, and resource limitations for the multi-device ISCC system. By decomposing it into two subproblems, we develop an alternating direction method of multipliers (ADMM)-based distributed algorithm. It alternatively solves a sensing accuracy maximization subproblem at each device and employs a closed-form computation resource allocation strategy at the edge server till convergence. Finally, a real-world test is conducted using commodity wireless devices to validate the sensing performance analysis. Extensive test results demonstrate that our proposal achieves higher sensing accuracy under the limited resource compared to two baselines.
AdaptMI: Adaptive Skill-based In-context Math Instruction for Small Language Models
Apr 30, 2025In-context learning (ICL) allows a language model to improve its problem-solving capability when provided with suitable information in context. Since the choice of in-context information can be determined based on the problem itself, in-context learning is analogous to human learning from teachers in a classroom. Recent works (Didolkar et al., 2024a; 2024b) show that ICL performance can be improved by leveraging a frontier large language model's (LLM) ability to predict required skills to solve a problem, popularly referred to as an LLM's metacognition, and using the recommended skills to construct necessary in-context examples. While this skill-based strategy boosts ICL performance in larger models, its gains on small language models (SLMs) have been minimal, highlighting a performance gap in ICL capabilities. We investigate this gap and show that skill-based prompting can hurt SLM performance on easy questions by introducing unnecessary information, akin to cognitive overload. To address this, we introduce AdaptMI, an adaptive approach to selecting skill-based in-context Math Instructions for SLMs. Inspired by cognitive load theory from human pedagogy, our method only introduces skill-based examples when the model performs poorly. We further propose AdaptMI+, which adds examples targeted to the specific skills missing from the model's responses. On 5-shot evaluations across popular math benchmarks and five SLMs (1B--7B; Qwen, Llama), AdaptMI+ improves accuracy by up to 6% over naive skill-based strategies.
EmoAgent: Assessing and Safeguarding Human-AI Interaction for Mental Health Safety
Apr 13, 2025The rise of LLM-driven AI characters raises safety concerns, particularly for vulnerable human users with psychological disorders. To address these risks, we propose EmoAgent, a multi-agent AI framework designed to evaluate and mitigate mental health hazards in human-AI interactions. EmoAgent comprises two components: EmoEval simulates virtual users, including those portraying mentally vulnerable individuals, to assess mental health changes before and after interactions with AI characters. It uses clinically proven psychological and psychiatric assessment tools (PHQ-9, PDI, PANSS) to evaluate mental risks induced by LLM. EmoGuard serves as an intermediary, monitoring users' mental status, predicting potential harm, and providing corrective feedback to mitigate risks. Experiments conducted in popular character-based chatbots show that emotionally engaging dialogues can lead to psychological deterioration in vulnerable users, with mental state deterioration in more than 34.4% of the simulations. EmoGuard significantly reduces these deterioration rates, underscoring its role in ensuring safer AI-human interactions. Our code is available at: https://github.com/1akaman/EmoAgent
Graph Neural Network for Location- and Orientation-Assisted mmWave Beam Alignment
Mar 10, 2025In massive multi-input multi-output (MIMO) systems, the main bottlenecks of location- and orientation-assisted beam alignment using deep neural networks (DNNs) are large training overhead and significant performance degradation. This paper proposes a graph neural network (GNN)-based beam selection approach that reduces the training overhead and improves the alignment accuracy, by capitalizing on the strong expressive ability and few trainable parameters of GNN. The channels of beams are correlated according to the beam direction. Therefore, we establish a graph according to the angular correlation between beams and use GNN to capture the channel correlation between adjacent beams, which helps accelerate the learning process and enhance the beam alignment performance. Compared to existing DNN-based algorithms, the proposed method requires only 20\% of the dataset size to achieve equivalent accuracy and improves the Top-1 accuracy by 10\% when using the same dataset.