 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Efficiency of Low Earth Orbit Satellite Constellations
Nov 29, 2024



This paper investigates the maximum downlink spectral efficiency of low earth orbit (LEO) constellations. Spectral efficiency, in this context, refers to the sum rate of the entire network per unit spectrum per unit area on the earth's surface. For practicality all links employ single-user codebooks and treat interference as noise. To estimate the maximum achievable spectral efficiency, we propose and analyze a regular configuration, which deploys satellites and ground terminals in hexagonal lattices. Additionally, for wideband networks with arbitrary satellite configurations, we introduce a subband allocation algorithm aimed at maximizing the overall spectral efficiency. Simulation results indicate that the regular configuration is more efficient than random configurations. As the number of randomly placed satellites increases within an area, the subband allocation algorithm achieves a spectral efficiency that approaches the spectral efficiency achieved by the regular configuration. Further improvements are demonstrated by reconfiguring associations so that nearby transmitters avoid pointing to the same area.
Reducing Satellite Interference to Radio Telescopes Using Beacons
Dec 20, 2023



This paper proposes the transmission of beacon signals to alert potential interferers of an ongoing or impending passive sensing measurement. We focus on the interference from Low-Earth Orbiting (LEO) satellites to a radio-telescope. We compare the beacon approach with two versions of Radio Quiet Zones (RQZs): fixed quiet zones on the ground and in the sky, and dynamic quiet zones that vary across satellites. The beacon-assisted approach can potentially exploit channel reciprocity, which accounts for short-term channel variations between the satellite and radio telescope. System considerations associated with beacon design and potential schemes for beacon transmission are discussed. The probability of excessive Radio Frequency Interference (RFI) at the radio telescope (outage probability) and the fraction of active links in the satellite network are used as performance metrics. Numerical simulations compare the performance of the approaches considered, and show that the beacon approach enables more active satellite links relative to quiet zones for a given outage probability.
RadYOLOLet: Radar Detection and Parameter Estimation Using YOLO and WaveLet
Sep 21, 2023



Detection of radar signals without assistance from the radar transmitter is a crucial requirement for emerging and future shared-spectrum wireless networks like Citizens Broadband Radio Service (CBRS). In this paper, we propose a supervised deep learning-based spectrum sensing approach called RadYOLOLet that can detect low-power radar signals in the presence of interference and estimate the radar signal parameters. The core of RadYOLOLet is two different convolutional neural networks (CNN), RadYOLO and Wavelet-CNN, that are trained independently. RadYOLO operates on spectrograms and provides most of the capabilities of RadYOLOLet. However, it suffers from low radar detection accuracy in the low signal-to-noise ratio (SNR) regime. We develop Wavelet-CNN specifically to deal with this limitation of RadYOLO. Wavelet-CNN operates on continuous Wavelet transform of the captured signals, and we use it only when RadYOLO fails to detect any radar signal. We thoroughly evaluate RadYOLOLet using different experiments corresponding to different types of interference signals. Based on our evaluations, we find that RadYOLOLet can achieve 100% radar detection accuracy for our considered radar types up to 16 dB SNR, which cannot be guaranteed by other comparable methods. RadYOLOLet can also function accurately under interference up to 16 dB SINR.
ProSpire: Proactive Spatial Prediction of Radio Environment Using Deep Learning
Aug 20, 2023Spatial prediction of the radio propagation environment of a transmitter can assist and improve various aspects of wireless networks. The majority of research in this domain can be categorized as 'reactive' spatial prediction, where the predictions are made based on a small set of measurements from an active transmitter whose radio environment is to be predicted. Emerging spectrum-sharing paradigms would benefit from 'proactive' spatial prediction of the radio environment, where the spatial predictions must be done for a transmitter for which no measurement has been collected. This paper proposes a novel, supervised deep learning-based framework, ProSpire, that enables spectrum sharing by leveraging the idea of proactive spatial prediction. We carefully address several challenges in ProSpire, such as designing a framework that conveniently collects training data for learning, performing the predictions in a fast manner, enabling operations without an area map, and ensuring that the predictions do not lead to undesired interference. ProSpire relies on the crowdsourcing of transmitters and receivers during their normal operations to address some of the aforementioned challenges. The core component of ProSpire is a deep learning-based image-to-image translation method, which we call RSSu-net. We generate several diverse datasets using ray tracing software and numerically evaluate ProSpire. Our evaluations show that RSSu-net performs reasonably well in terms of signal strength prediction, 5 dB mean absolute error, which is comparable to the average error of other relevant methods. Importantly, due to the merits of RSSu-net, ProSpire creates proactive boundaries around transmitters such that they can be activated with 97% probability of not causing interference. In this regard, the performance of RSSu-net is 19% better than that of other comparable methods.
A New Distributed Method for Training Generative Adversarial Networks
Jul 19, 2021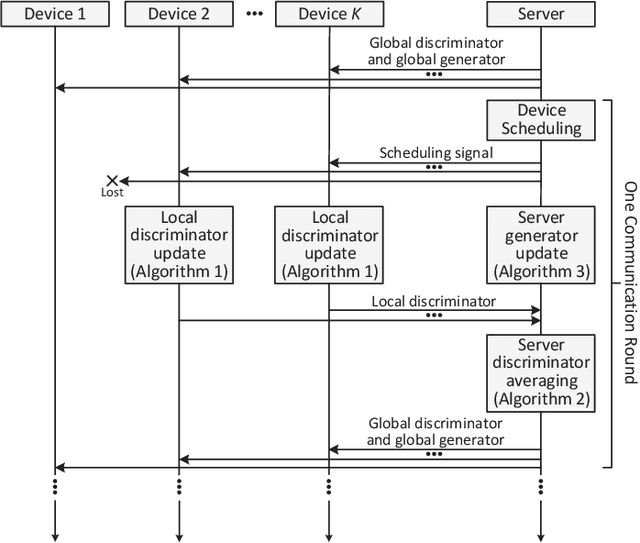
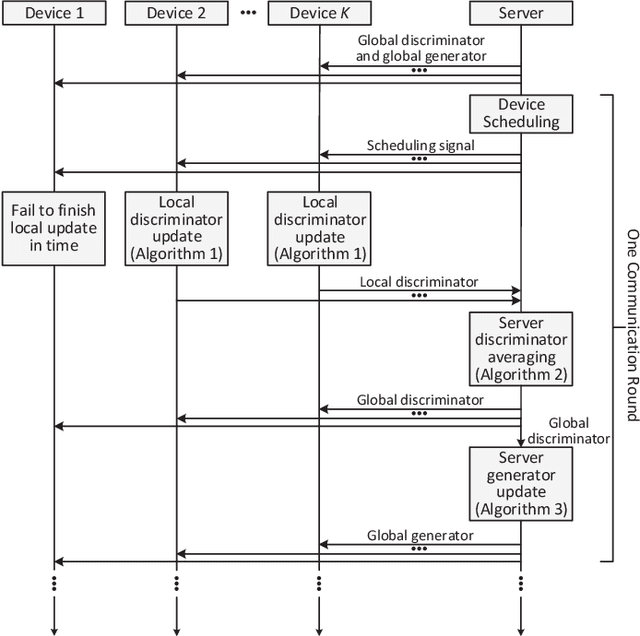
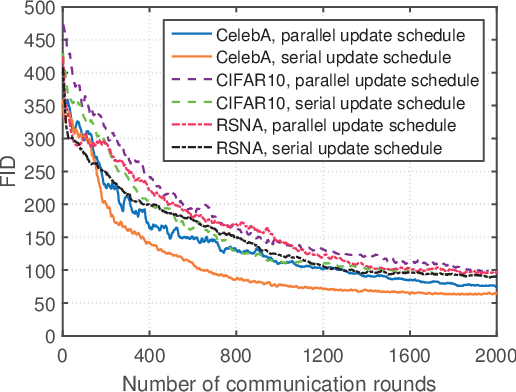

Generative adversarial networks (GANs) are emerging machine learning models for generating synthesized data similar to real data by jointly training a generator and a discriminator. In many applications, data and computational resources are distributed over many devices, so centralized computation with all data in one location is infeasible due to privacy and/or communication constraints. This paper proposes a new framework for training GANs in a distributed fashion: Each device computes a local discriminator using local data; a single server aggregates their results and computes a global GAN. Specifically, in each iteration, the server sends the global GAN to the devices, which then update their local discriminators; the devices send their results to the server, which then computes their average as the global discriminator and updates the global generator accordingly. Two different update schedules are designed with different levels of parallelism between the devices and the server. Numerical results obtained using three popular datasets demonstrate that the proposed framework can outperform a state-of-the-art framework in terms of convergence speed.
Deep Reinforcement Learning for Joint Spectrum and Power Allocation in Cellular Networks
Dec 19, 2020

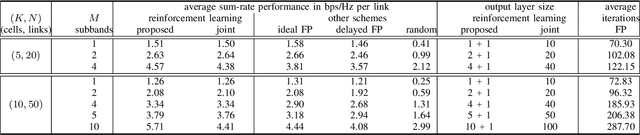
A wireless network operator typically divides the radio spectrum it possesses into a number of subbands. In a cellular network those subbands are then reused in many cells. To mitigate co-channel interference, a joint spectrum and power allocation problem is often formulated to maximize a sum-rate objective. The best known algorithms for solving such problems generally require instantaneous global channel state information and a centralized optimizer. In fact those algorithms have not been implemented in practice in large networks with time-varying subbands. Deep reinforcement learning algorithms are promising tools for solving complex resource management problems. A major challenge here is that spectrum allocation involves discrete subband selection, whereas power allocation involves continuous variables. In this paper, a learning framework is proposed to optimize both discrete and continuous decision variables. Specifically, two separate deep reinforcement learning algorithms are designed to be executed and trained simultaneously to maximize a joint objective. Simulation results show that the proposed scheme outperforms both the state-of-the-art fractional programming algorithm and a previous solution based on deep reinforcement learning.
Deep Actor-Critic Learning for Distributed Power Control in Wireless Mobile Networks
Sep 14, 2020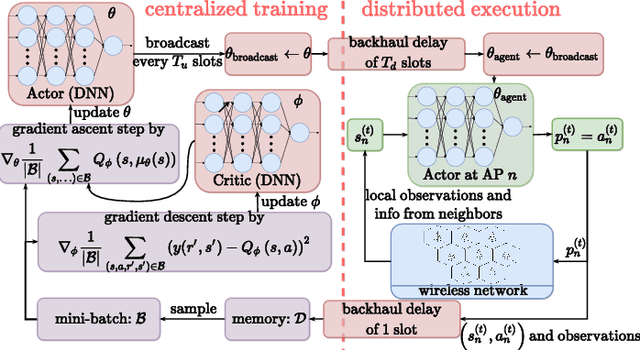
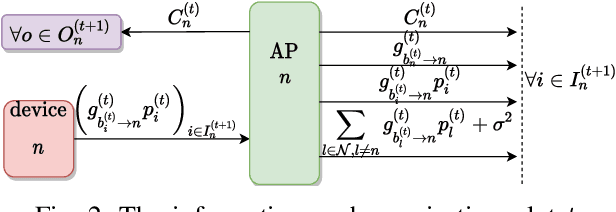
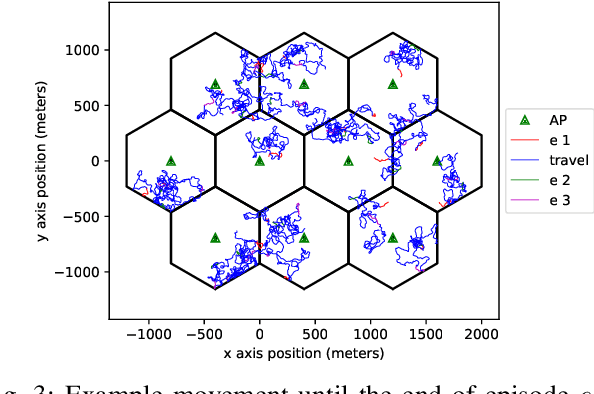
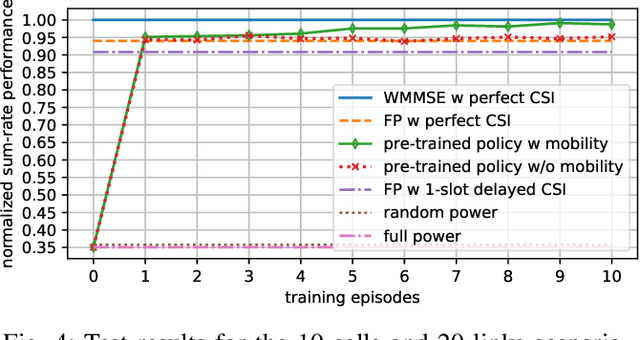
Deep reinforcement learning offers a model-free alternative to supervised deep learning and classical optimization for solving the transmit power control problem in wireless networks. The multi-agent deep reinforcement learning approach considers each transmitter as an individual learning agent that determines its transmit power level by observing the local wireless environment. Following a certain policy, these agents learn to collaboratively maximize a global objective, e.g., a sum-rate utility function. This multi-agent scheme is easily scalable and practically applicable to large-scale cellular networks. In this work, we present a distributively executed continuous power control algorithm with the help of deep actor-critic learning, and more specifically, by adapting deep deterministic policy gradient. Furthermore, we integrate the proposed power control algorithm to a time-slotted system where devices are mobile and channel conditions change rapidly. We demonstrate the functionality of the proposed algorithm using simulation results.
Scheduling in Cellular Federated Edge Learning with Importance and Channel Awareness
Apr 01, 2020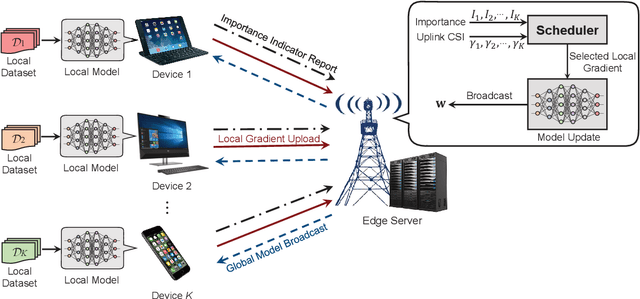

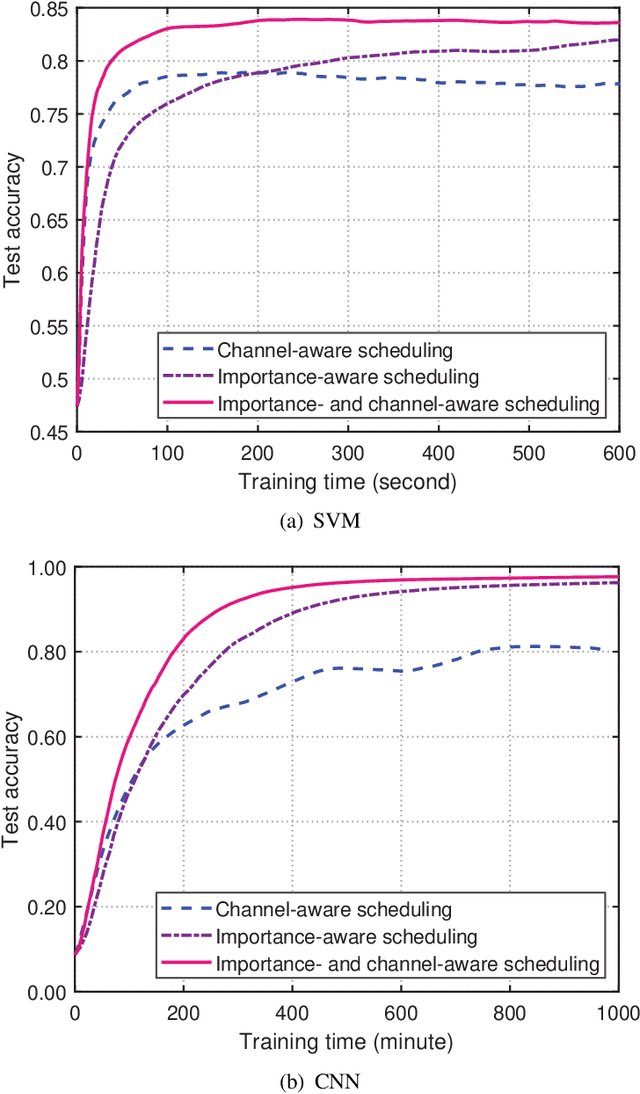
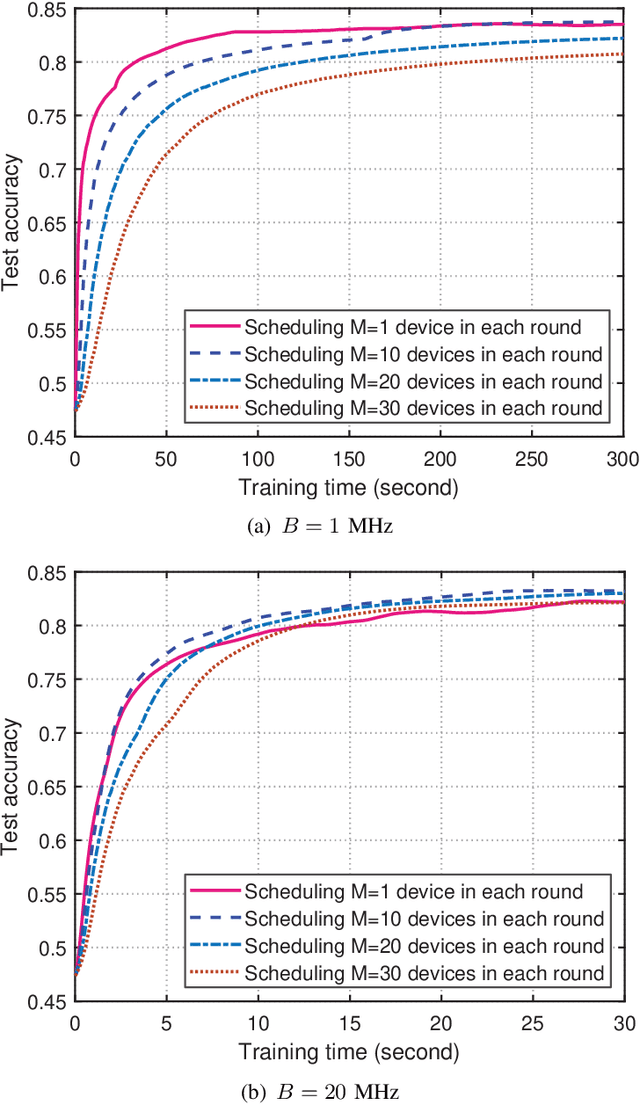
In cellular federated edge learning (FEEL), multiple edge devices holding local data jointly train a learning algorithm by communicating learning updates with an access point without exchanging their data samples. With limited communication resources, it is beneficial to schedule the most informative local learning update. In this paper, a novel scheduling policy is proposed to exploit both diversity in multiuser channels and diversity in the importance of the edge devices' learning updates. First, a new probabilistic scheduling framework is developed to yield unbiased update aggregation in FEEL. The importance of a local learning update is measured by gradient divergence. If one edge device is scheduled in each communication round, the scheduling policy is derived in closed form to achieve the optimal trade-off between channel quality and update importance. The probabilistic scheduling framework is then extended to allow scheduling multiple edge devices in each communication round. Numerical results obtained using popular models and learning datasets demonstrate that the proposed scheduling policy can achieve faster model convergence and higher learning accuracy than conventional scheduling policies that only exploit a single type of diversity.
Deep Reinforcement Learning for Distributed Dynamic Power Allocation in Wireless Networks
Aug 01, 2018

This work demonstrates the potential of deep reinforcement learning techniques for transmit power control in emerging and future wireless networks. Various techniques have been proposed in the literature to find near-optimal power allocations, often by solving a challenging optimization problem. Most of these algorithms are not scalable to large networks in real-world scenarios because of their computational complexity and instantaneous cross-cell channel state information (CSI) requirement. In this paper, a model-free distributed dynamic power allocation scheme is developed based on deep reinforcement learning. Each transmitter collects CSI and quality of service (QoS) information from several neighbors and adapts its own transmit power accordingly. The objective is to maximize a weighted sum-rate utility function, which can be particularized to achieve maximum sum-rate or proportionally fair scheduling (with weights that are changing over time). Both random variations and delays in the CSI are inherently addressed using deep Q-learning. For a typical network architecture, the proposed algorithm is shown to achieve near-optimal power allocation in real time based on delayed CSI measurements available to the agents. This work indicates that deep reinforcement learning based radio resource management can be very fast and deliver highly competitive performance, especially in practical scenarios where the system model is inaccurate and CSI delay is non-negligible.