 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Precision Conjugate Gradient Method for Massive MIMO Detection
Apr 14, 2025The implementation of the conjugate gradient (CG) method for massive MIMO detection is computationally challenging, especially for a large number of users and correlated channels. In this paper, we propose a low computational complexity CG detection from a finite-precision perspective. First, we develop a finite-precision CG (FP-CG) detection to mitigate the computational bottleneck of each CG iteration and provide the attainable accuracy, convergence, and computational complexity analysis to reveal the impact of finite-precision arithmetic. A practical heuristic is presented to select suitable precisions. Then, to further reduce the number of iterations, we propose a joint finite-precision and block-Jacobi preconditioned CG (FP-BJ-CG) detection. The corresponding performance analysis is also provided. Finally, simulation results validate the theoretical insights and demonstrate the superiority of the proposed detection.
Federated Dropout: Convergence Analysis and Resource Allocation
Dec 31, 2024



Federated Dropout is an efficient technique to overcome both communication and computation bottlenecks for deploying federated learning at the network edge. In each training round, an edge device only needs to update and transmit a sub-model, which is generated by the typical method of dropout in deep learning, and thus effectively reduces the per-round latency. \textcolor{blue}{However, the theoretical convergence analysis for Federated Dropout is still lacking in the literature, particularly regarding the quantitative influence of dropout rate on convergence}. To address this issue, by using the Taylor expansion method, we mathematically show that the gradient variance increases with a scaling factor of $\gamma/(1-\gamma)$, with $\gamma \in [0, \theta)$ denoting the dropout rate and $\theta$ being the maximum dropout rate ensuring the loss function reduction. Based on the above approximation, we provide the convergence analysis for Federated Dropout. Specifically, it is shown that a larger dropout rate of each device leads to a slower convergence rate. This provides a theoretical foundation for reducing the convergence latency by making a tradeoff between the per-round latency and the overall rounds till convergence. Moreover, a low-complexity algorithm is proposed to jointly optimize the dropout rate and the bandwidth allocation for minimizing the loss function in all rounds under a given per-round latency and limited network resources. Finally, numerical results are provided to verify the effectiveness of the proposed algorithm.
Structured IB: Improving Information Bottleneck with Structured Feature Learning
Dec 11, 2024The Information Bottleneck (IB) principle has emerged as a promising approach for enhancing the generalization, robustness, and interpretability of deep neural networks, demonstrating efficacy across image segmentation, document clustering, and semantic communication. Among IB implementations, the IB Lagrangian method, employing Lagrangian multipliers, is widely adopted. While numerous methods for the optimizations of IB Lagrangian based on variational bounds and neural estimators are feasible, their performance is highly dependent on the quality of their design, which is inherently prone to errors. To address this limitation, we introduce Structured IB, a framework for investigating potential structured features. By incorporating auxiliary encoders to extract missing informative features, we generate more informative representations. Our experiments demonstrate superior prediction accuracy and task-relevant information preservation compared to the original IB Lagrangian method, even with reduced network size.
A Survey on Integrated Sensing, Communication, and Computation
Aug 15, 2024



The forthcoming generation of wireless technology, 6G, promises a revolutionary leap beyond traditional data-centric services. It aims to usher in an era of ubiquitous intelligent services, where everything is interconnected and intelligent. This vision requires the seamless integration of three fundamental modules: Sensing for information acquisition, communication for information sharing, and computation for information processing and decision-making. These modules are intricately linked, especially in complex tasks such as edge learning and inference. However, the performance of these modules is interdependent, creating a resource competition for time, energy, and bandwidth. Existing techniques like integrated communication and computation (ICC), integrated sensing and computation (ISC), and integrated sensing and communication (ISAC) have made partial strides in addressing this challenge, but they fall short of meeting the extreme performance requirements. To overcome these limitations, it is essential to develop new techniques that comprehensively integrate sensing, communication, and computation. This integrated approach, known as Integrated Sensing, Communication, and Computation (ISCC), offers a systematic perspective for enhancing task performance. This paper begins with a comprehensive survey of historic and related techniques such as ICC, ISC, and ISAC, highlighting their strengths and limitations. It then explores the state-of-the-art signal designs for ISCC, along with network resource management strategies specifically tailored for ISCC. Furthermore, this paper discusses the exciting research opportunities that lie ahead for implementing ISCC in future advanced networks. By embracing ISCC, we can unlock the full potential of intelligent connectivity, paving the way for groundbreaking applications and services.
Collaborative Edge AI Inference over Cloud-RAN
Apr 09, 2024In this paper, a cloud radio access network (Cloud-RAN) based collaborative edge AI inference architecture is proposed. Specifically, geographically distributed devices capture real-time noise-corrupted sensory data samples and extract the noisy local feature vectors, which are then aggregated at each remote radio head (RRH) to suppress sensing noise. To realize efficient uplink feature aggregation, we allow each RRH receives local feature vectors from all devices over the same resource blocks simultaneously by leveraging an over-the-air computation (AirComp) technique. Thereafter, these aggregated feature vectors are quantized and transmitted to a central processor (CP) for further aggregation and downstream inference tasks. Our aim in this work is to maximize the inference accuracy via a surrogate accuracy metric called discriminant gain, which measures the discernibility of different classes in the feature space. The key challenges lie on simultaneously suppressing the coupled sensing noise, AirComp distortion caused by hostile wireless channels, and the quantization error resulting from the limited capacity of fronthaul links. To address these challenges, this work proposes a joint transmit precoding, receive beamforming, and quantization error control scheme to enhance the inference accuracy. Extensive numerical experiments demonstrate the effectiveness and superiority of our proposed optimization algorithm compared to various baselines.
Low-Rank Gradient Compression with Error Feedback for MIMO Wireless Federated Learning
Jan 15, 2024This paper presents a novel approach to enhance the communication efficiency of federated learning (FL) in multiple input and multiple output (MIMO) wireless systems. The proposed method centers on a low-rank matrix factorization strategy for local gradient compression based on alternating least squares, along with over-the-air computation and error feedback. The proposed protocol, termed over-the-air low-rank compression (Ota-LC), is demonstrated to have lower computation cost and lower communication overhead as compared to existing benchmarks while guaranteeing the same inference performance. As an example, when targeting a test accuracy of 80% on the Cifar-10 dataset, Ota-LC achieves a reduction in total communication costs of at least 30% when contrasted with benchmark schemes, while also reducing the computational complexity order by a factor equal to the sum of the dimension of the gradients.
Integrated Sensing-Communication-Computation for Edge Artificial Intelligence
Jun 01, 2023Edge artificial intelligence (AI) has been a promising solution towards 6G to empower a series of advanced techniques such as digital twin, holographic projection, semantic communications, and auto-driving, for achieving intelligence of everything. The performance of edge AI tasks, including edge learning and edge AI inference, depends on the quality of three highly coupled processes, i.e., sensing for data acquisition, computation for information extraction, and communication for information transmission. However, these three modules need to compete for network resources for enhancing their own quality-of-services. To this end, integrated sensing-communication-computation (ISCC) is of paramount significance for improving resource utilization as well as achieving the customized goals of edge AI tasks. By investigating the interplay among the three modules, this article presents various kinds of ISCC schemes for federated edge learning tasks and edge AI inference tasks in both application and physical layers.
Task-Oriented Over-the-Air Computation for Multi-Device Edge AI
Nov 02, 2022Departing from the classic paradigm of data-centric designs, the 6G networks for supporting edge AI features task-oriented techniques that focus on effective and efficient execution of AI task. Targeting end-to-end system performance, such techniques are sophisticated as they aim to seamlessly integrate sensing (data acquisition), communication (data transmission), and computation (data processing). Aligned with the paradigm shift, a task-oriented over-the-air computation (AirComp) scheme is proposed in this paper for multi-device split-inference system. In the considered system, local feature vectors, which are extracted from the real-time noisy sensory data on devices, are aggregated over-the-air by exploiting the waveform superposition in a multiuser channel. Then the aggregated features as received at a server are fed into an inference model with the result used for decision making or control of actuators. To design inference-oriented AirComp, the transmit precoders at edge devices and receive beamforming at edge server are jointly optimized to rein in the aggregation error and maximize the inference accuracy. The problem is made tractable by measuring the inference accuracy using a surrogate metric called discriminant gain, which measures the discernibility of two object classes in the application of object/event classification. It is discovered that the conventional AirComp beamforming design for minimizing the mean square error in generic AirComp with respect to the noiseless case may not lead to the optimal classification accuracy. The reason is due to the overlooking of the fact that feature dimensions have different sensitivity towards aggregation errors and are thus of different importance levels for classification. This issue is addressed in this work via a new task-oriented AirComp scheme designed by directly maximizing the derived discriminant gain.
Task-Oriented Sensing, Computation, and Communication Integration for Multi-Device Edge AI
Jul 03, 2022

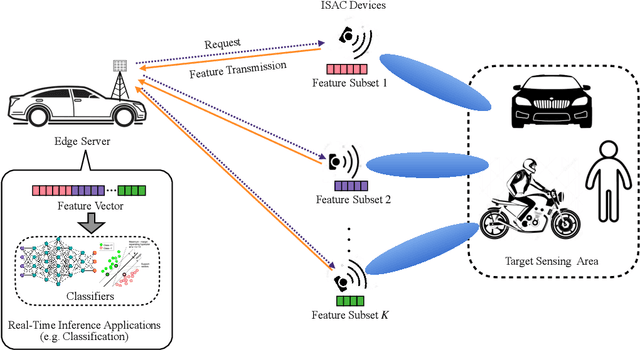

This paper studies a new multi-device edge artificial-intelligent (AI) system, which jointly exploits the AI model split inference and integrated sensing and communication (ISAC) to enable low-latency intelligent services at the network edge. In this system, multiple ISAC devices perform radar sensing to obtain multi-view data, and then offload the quantized version of extracted features to a centralized edge server, which conducts model inference based on the cascaded feature vectors. Under this setup and by considering classification tasks, we measure the inference accuracy by adopting an approximate but tractable metric, namely discriminant gain, which is defined as the distance of two classes in the Euclidean feature space under normalized covariance. To maximize the discriminant gain, we first quantify the influence of the sensing, computation, and communication processes on it with a derived closed-form expression. Then, an end-to-end task-oriented resource management approach is developed by integrating the three processes into a joint design. This integrated sensing, computation, and communication (ISCC) design approach, however, leads to a challenging non-convex optimization problem, due to the complicated form of discriminant gain and the device heterogeneity in terms of channel gain, quantization level, and generated feature subsets. Remarkably, the considered non-convex problem can be optimally solved based on the sum-of-ratios method. This gives the optimal ISCC scheme, that jointly determines the transmit power and time allocation at multiple devices for sensing and communication, as well as their quantization bits allocation for computation distortion control. By using human motions recognition as a concrete AI inference task, extensive experiments are conducted to verify the performance of our derived optimal ISCC scheme.
What is Semantic Communication? A View on Conveying Meaning in the Era of Machine Intelligence
Oct 01, 2021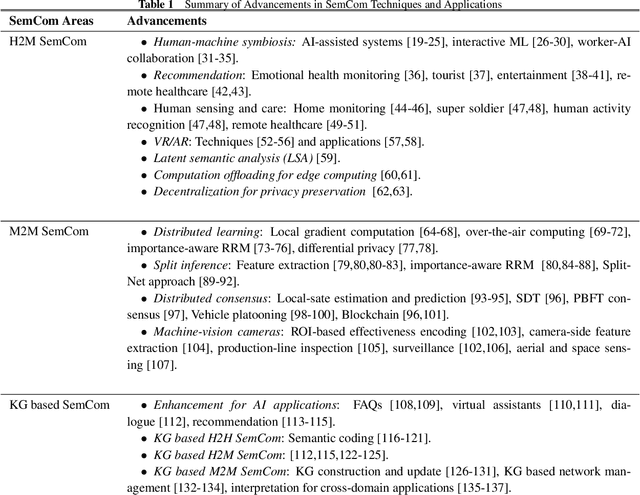


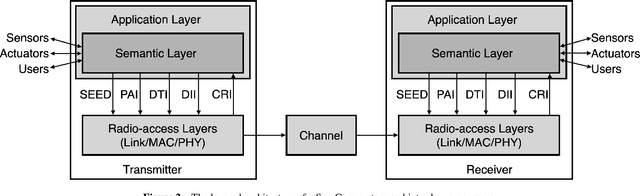
In 1940s, Claude Shannon developed the information theory focusing on quantifying the maximum data rate that can be supported by a communication channel. Guided by this, the main theme of wireless system design up until 5G was the data rate maximization. In his theory, the semantic aspect and meaning of messages were treated as largely irrelevant to communication. The classic theory started to reveal its limitations in the modern era of machine intelligence, consisting of the synergy between IoT and AI. By broadening the scope of the classic framework, in this article we present a view of semantic communication (SemCom) and conveying meaning through the communication systems. We address three communication modalities, human-to-human (H2H), human-to-machine (H2M), and machine-to-machine (M2M) communications. The latter two, the main theme of the article, represent the paradigm shift in communication and computing. H2M SemCom refers to semantic techniques for conveying meanings understandable by both humans and machines so that they can interact. M2M SemCom refers to effectiveness techniques for efficiently connecting machines such that they can effectively execute a specific computation task in a wireless network. The first part of the article introduces SemCom principles including encoding, system architecture, and layer-coupling and end-to-end design approaches. The second part focuses on specific techniques for application areas of H2M (human and AI symbiosis, recommendation, etc.) and M2M SemCom (distributed learning, split inference, etc.) Finally, we discuss the knowledge graphs approach for designing SemCom systems. We believe that this comprehensive introduction will provide a useful guide into the emerging area of SemCom that is expected to play an important role in 6G featuring connected intelligence and integrated sensing, computing, communication, and control.