 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded Deep Unfolding for Joint Beamforming and Scheduling in Multi-Cell MIMO Networks
Jun 03, 2026This paper investigates the joint resource block group (RBG) scheduling and beamforming optimization problem for weighted sum-rate (WSR) maximization in multi-cell multiple-input multiple-output (MIMO) downlink networks. While the Fast Fractional Programming (FastFP) framework provides a reliable model-driven solution, it suffers from conservative continuous beamforming updates and prohibitive computational overhead during the discrete RBG matching phase. To address these bottlenecks, we propose a joint deep unfolding framework comprising two core modules: P-Net and K-Net. For continuous beamforming, P-Net learns an adaptive relaxation factor along the analytical FastFP update direction. By strictly constraining this factor within an ascent-preserving interval, P-Net accelerates the optimization trajectory while rigorously retaining monotonic improvement and stationary-point convergence guarantees. For discrete RBG scheduling, K-Net learns a long-horizon priority policy that guides a low-complexity greedy assignment, effectively preserving the assignment quality while bypassing the high complexity of Hungarian matching. Both networks leverage analytical algorithmic priors and utilize recurrent parameter sharing, enabling flexible inference beyond the training horizon. Extensive simulations demonstrate that the proposed joint framework achieves higher WSR and faster execution times than conventional model-driven baselines, while generalizing robustly across unseen network scales, antenna configurations, and channel conditions without retraining.
OmniISR: A Unified Framework for Centralized and Federated Learning via Intermediate Supervision and Regularization
May 19, 2026The global deployment of edge intelligence operates across heterogeneous legal frameworks. While some regions permit centralized learning (CL) via cloud data aggregation, others enforce strict data localization, necessitating federated learning (FL). This operational dichotomy introduces two incompatible optimization regimes (i.e., unbiased global gradients yet coupled with internal covariate shift in CL versus biased, drift-prone local updates in FL), resulting in that any naive integration of the two lacks rigorous theoretical guarantees. To fill this gap, we propose OmniISR, a unified framework that fuses pure CL, pure FL, and hybrid CL-FL training modes via equipping intermediate supervision and regularization (ISR) signals at multiple hidden layers. Specifically, we propose (i) to use mutual-information (MI) as intermediate supervision to align shifting internal covariate in CL and client-drifting representations in FL, and (ii) to adopt negative-entropy (NE) as intermediate regularizer to penalize overconfident prediction, preserve representational uncertainty, and avoid device-specific collapse. On the theory side, we derive (i) a unified, ISR-agnostic, and non-asymptotic O(1/sqrt(T)) convergence bound that shows the introduced ISR does not violate standard SGD convergence, (ii) a federated drift-bound that quantifies the ISR-reduced client drift, (iii) a gradient-alignment guarantee that ensures non-conflicting CL and FL updates under mild bias, and (iv) an explicit escape-time bound that indicates that CL-FL hybrid mixing enlarges effective stochasticity and accelerates escape from strict saddles. Extensive experiments demonstrate that OmniISR consistently improves model performance in both centralized and federated paradigms, reduces the CL-FL gap by 22.60%, and yields 37/48 paired metric wins across multiple FL algorithms.
Sense Smarter, Think Better: Edge Perception for Next-Generation Networks
May 18, 2026Edge perception has emerged as a foundational capability for future wireless networks, enabling the network edge to proactively sense, interpret, and interact with the physical environment in a task-oriented and resource-aware manner. This survey provides a comprehensive and structured overview of edge perception. We first review representative sensing modalities and edge artificial intelligence (AI) techniques as the fundamental building blocks. We then examine their synergistic interactions. We systematically analyze how edge AI enhances sensing capabilities, encompassing both in-band and out-of-band modalities, as well as multi-modal sensor data fusion. Moreover, we discuss the role of task-driven sensing in facilitating edge AI, including integrated sensing-communication-computation designs, and active perception frameworks that dynamically adapt sensing strategies for downstream applications. Finally, we identify key challenges and open issues. By consolidating fragmented research across sensing, communication, and edge AI, this survey provides forward-looking insights for the design and implementation of edge perception systems for sixth-generation (6G) networks.
Bridging Large-Model Reasoning and Real-Time Control via Agentic Fast-Slow Planning
Apr 02, 2026Large foundation models enable powerful reasoning for autonomous systems, but mapping semantic intent to reliable real-time control remains challenging. Existing approaches either (i) let Large Language Models (LLMs) generate trajectories directly - brittle, hard to verify, and latency-prone - or (ii) adjust Model Predictive Control (MPC) objectives online - mixing slow deliberation with fast control and blurring interfaces. We propose Agentic Fast-Slow Planning, a hierarchical framework that decouples perception, reasoning, planning, and control across natural timescales. The framework contains two bridges. Perception2Decision compresses scenes into ego-centric topologies using an on-vehicle Vision-Language Model (VLM) detector, then maps them to symbolic driving directives in the cloud with an LLM decision maker - reducing bandwidth and delay while preserving interpretability. Decision2Trajectory converts directives into executable paths: Semantic-Guided A* embeds language-derived soft costs into classical search to bias solutions toward feasible trajectories, while an Agentic Refinement Module adapts planner hyperparameters using feedback and memory. Finally, MPC tracks the trajectories in real time, with optional cloud-guided references for difficult cases. Experiments in CARLA show that Agentic Fast-Slow Planning improves robustness under perturbations, reducing lateral deviation by up to 45% and completion time by over 12% compared to pure MPC and an A*-guided MPC baseline. Code is available at https://github.com/cjychenjiayi/icra2026_AFSP.
DK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks
Nov 13, 2025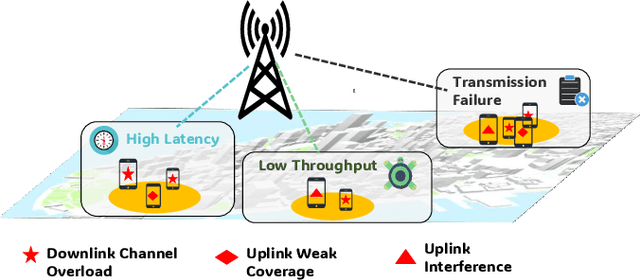
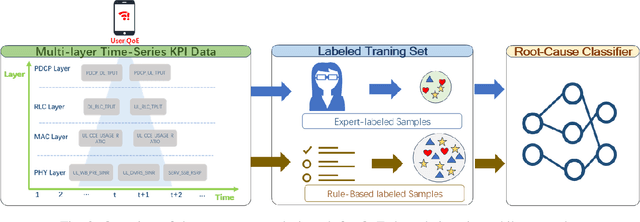
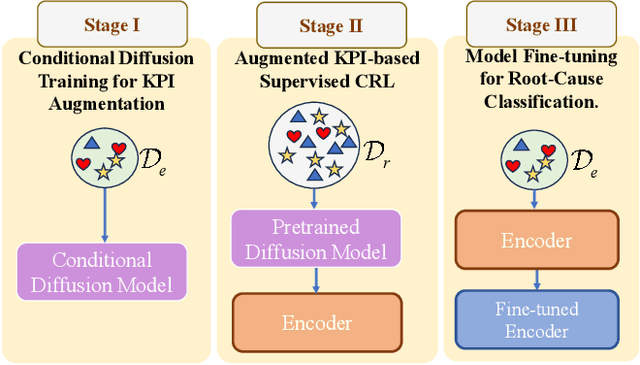
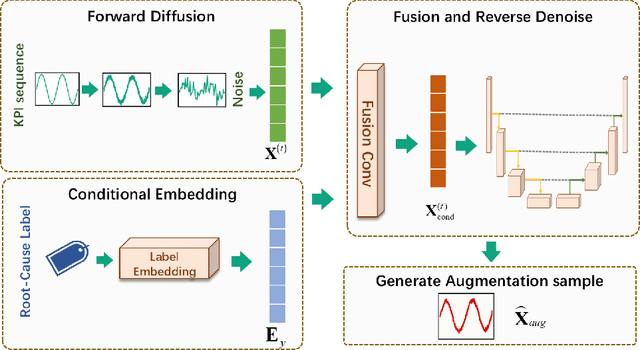
Diagnosing the root causes of Quality of Experience (QoE) degradations in operational mobile networks is challenging due to complex cross-layer interactions among kernel performance indicators (KPIs) and the scarcity of reliable expert annotations. Although rule-based heuristics can generate labels at scale, they are noisy and coarse-grained, limiting the accuracy of purely data-driven approaches. To address this, we propose DK-Root, a joint data-and-knowledge-driven framework that unifies scalable weak supervision with precise expert guidance for robust root-cause analysis. DK-Root first pretrains an encoder via contrastive representation learning using abundant rule-based labels while explicitly denoising their noise through a supervised contrastive objective. To supply task-faithful data augmentation, we introduce a class-conditional diffusion model that generates KPIs sequences preserving root-cause semantics, and by controlling reverse diffusion steps, it produces weak and strong augmentations that improve intra-class compactness and inter-class separability. Finally, the encoder and the lightweight classifier are jointly fine-tuned with scarce expert-verified labels to sharpen decision boundaries. Extensive experiments on a real-world, operator-grade dataset demonstrate state-of-the-art accuracy, with DK-Root surpassing traditional ML and recent semi-supervised time-series methods. Ablations confirm the necessity of the conditional diffusion augmentation and the pretrain-finetune design, validating both representation quality and classification gains.
STM3: Mixture of Multiscale Mamba for Long-Term Spatio-Temporal Time-Series Prediction
Aug 17, 2025Recently, spatio-temporal time-series prediction has developed rapidly, yet existing deep learning methods struggle with learning complex long-term spatio-temporal dependencies efficiently. The long-term spatio-temporal dependency learning brings two new challenges: 1) The long-term temporal sequence includes multiscale information naturally which is hard to extract efficiently; 2) The multiscale temporal information from different nodes is highly correlated and hard to model. To address these challenges, we propose an efficient \textit{\textbf{S}patio-\textbf{T}emporal \textbf{M}ultiscale \textbf{M}amba} (STM2) that includes a multiscale Mamba architecture to capture the multiscale information efficiently and simultaneously, and an adaptive graph causal convolution network to learn the complex multiscale spatio-temporal dependency. STM2 includes hierarchical information aggregation for different-scale information that guarantees their distinguishability. To capture diverse temporal dynamics across all spatial nodes more efficiently, we further propose an enhanced version termed \textit{\textbf{S}patio-\textbf{T}emporal \textbf{M}ixture of \textbf{M}ultiscale \textbf{M}amba} (STM3) that employs a special Mixture-of-Experts architecture, including a more stable routing strategy and a causal contrastive learning strategy to enhance the scale distinguishability. We prove that STM3 has much better routing smoothness and guarantees the pattern disentanglement for each expert successfully. Extensive experiments on real-world benchmarks demonstrate STM2/STM3's superior performance, achieving state-of-the-art results in long-term spatio-temporal time-series prediction.
Rethinking Multi-User Communication in Semantic Domain: Enhanced OMDMA by Shuffle-Based Orthogonalization and Diffusion Denoising
Jul 28, 2025



Inter-user interference remains a critical bottleneck in wireless communication systems, particularly in the emerging paradigm of semantic communication (SemCom). Compared to traditional systems, inter-user interference in SemCom severely degrades key semantic information, often causing worse performance than Gaussian noise under the same power level. To address this challenge, inspired by the recently proposed concept of Orthogonal Model Division Multiple Access (OMDMA) that leverages semantic orthogonality rooted in the personalized joint source and channel (JSCC) models to distinguish users, we propose a novel, scalable framework that eliminates the need for user-specific JSCC models as did in original OMDMA. Our key innovation lies in shuffle-based orthogonalization, where randomly permuting the positions of JSCC feature vectors transforms inter-user interference into Gaussian-like noise. By assigning each user a unique shuffling pattern, the interference is treated as channel noise, enabling effective mitigation using diffusion models (DMs). This approach not only simplifies system design by requiring a single universal JSCC model but also enhances privacy, as shuffling patterns act as implicit private keys. Additionally, we extend the framework to scenarios involving semantically correlated data. By grouping users based on semantic similarity, a cooperative beamforming strategy is introduced to exploit redundancy in correlated data, further improving system performance. Extensive simulations demonstrate that the proposed method outperforms state-of-the-art multi-user SemCom frameworks, achieving superior semantic fidelity, robustness to interference, and scalability-all without requiring additional training overhead.
Low-Complexity Hybrid Beamforming for Multi-Cell mmWave Massive MIMO: A Primitive Kronecker Decomposition Approach
May 15, 2025To circumvent the high path loss of mmWave propagation and reduce the hardware cost of massive multiple-input multiple-output antenna systems, full-dimensional hybrid beamforming is critical in 5G and beyond wireless communications. Concerning an uplink multi-cell system with a large-scale uniform planar antenna array, this paper designs an efficient hybrid beamformer using primitive Kronecker decomposition and dynamic factor allocation, where the analog beamformer applies to null the inter-cell interference and simultaneously enhances the desired signals. In contrast, the digital beamformer mitigates the intra-cell interference using the minimum mean square error (MMSE) criterion. Then, due to the low accuracy of phase shifters inherent in the analog beamformer, a low-complexity hybrid beamformer is developed to slow its adjustment speed. Next, an optimality analysis from a subspace perspective is performed, and a sufficient condition for optimal antenna configuration is established. Finally, simulation results demonstrate that the achievable sum rate of the proposed beamformer approaches that of the optimal pure digital MMSE scheme, yet with much lower computational complexity and hardware cost.
FedEMA: Federated Exponential Moving Averaging with Negative Entropy Regularizer in Autonomous Driving
May 01, 2025Street Scene Semantic Understanding (denoted as S3U) is a crucial but complex task for autonomous driving (AD) vehicles. Their inference models typically face poor generalization due to domain-shift. Federated Learning (FL) has emerged as a promising paradigm for enhancing the generalization of AD models through privacy-preserving distributed learning. However, these FL AD models face significant temporal catastrophic forgetting when deployed in dynamically evolving environments, where continuous adaptation causes abrupt erosion of historical knowledge. This paper proposes Federated Exponential Moving Average (FedEMA), a novel framework that addresses this challenge through two integral innovations: (I) Server-side model's historical fitting capability preservation via fusing current FL round's aggregation model and a proposed previous FL round's exponential moving average (EMA) model; (II) Vehicle-side negative entropy regularization to prevent FL models' possible overfitting to EMA-introduced temporal patterns. Above two strategies empower FedEMA a dual-objective optimization that balances model generalization and adaptability. In addition, we conduct theoretical convergence analysis for the proposed FedEMA. Extensive experiments both on Cityscapes dataset and Camvid dataset demonstrate FedEMA's superiority over existing approaches, showing 7.12% higher mean Intersection-over-Union (mIoU).
iMacSR: Intermediate Multi-Access Supervision and Regularization in Training Autonomous Driving Models
May 01, 2025Deep Learning (DL)-based street scene semantic understanding has become a cornerstone of autonomous driving (AD). DL model performance heavily relies on network depth. Specifically, deeper DL architectures yield better segmentation performance. However, as models grow deeper, traditional one-point supervision at the final layer struggles to optimize intermediate feature representations, leading to subpar training outcomes. To address this, we propose an intermediate Multi-access Supervision and Regularization (iMacSR) strategy. The proposed iMacSR introduces two novel components: (I) mutual information between latent features and ground truth as intermediate supervision loss ensures robust feature alignment at multiple network depths; and (II) negative entropy regularization on hidden features discourages overconfident predictions and mitigates overfitting. These intermediate terms are combined into the original final-layer training loss to form a unified optimization objective, enabling comprehensive optimization across the network hierarchy. The proposed iMacSR provides a robust framework for training deep AD architectures, advancing the performance of perception systems in real-world driving scenarios. In addition, we conduct theoretical convergence analysis for the proposed iMacSR. Extensive experiments on AD benchmarks (i.e., Cityscapes, CamVid, and SynthiaSF datasets) demonstrate that iMacSR outperforms conventional final-layer single-point supervision method up to 9.19% in mean Intersection over Union (mIoU).