 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Hybrid Beamforming for Multi-Cell mmWave Massive MIMO: A Primitive Kronecker Decomposition Approach
May 15, 2025To circumvent the high path loss of mmWave propagation and reduce the hardware cost of massive multiple-input multiple-output antenna systems, full-dimensional hybrid beamforming is critical in 5G and beyond wireless communications. Concerning an uplink multi-cell system with a large-scale uniform planar antenna array, this paper designs an efficient hybrid beamformer using primitive Kronecker decomposition and dynamic factor allocation, where the analog beamformer applies to null the inter-cell interference and simultaneously enhances the desired signals. In contrast, the digital beamformer mitigates the intra-cell interference using the minimum mean square error (MMSE) criterion. Then, due to the low accuracy of phase shifters inherent in the analog beamformer, a low-complexity hybrid beamformer is developed to slow its adjustment speed. Next, an optimality analysis from a subspace perspective is performed, and a sufficient condition for optimal antenna configuration is established. Finally, simulation results demonstrate that the achievable sum rate of the proposed beamformer approaches that of the optimal pure digital MMSE scheme, yet with much lower computational complexity and hardware cost.
Plug-In Diffusion Model for Embedding Denoising in Recommendation System
Jan 29, 2024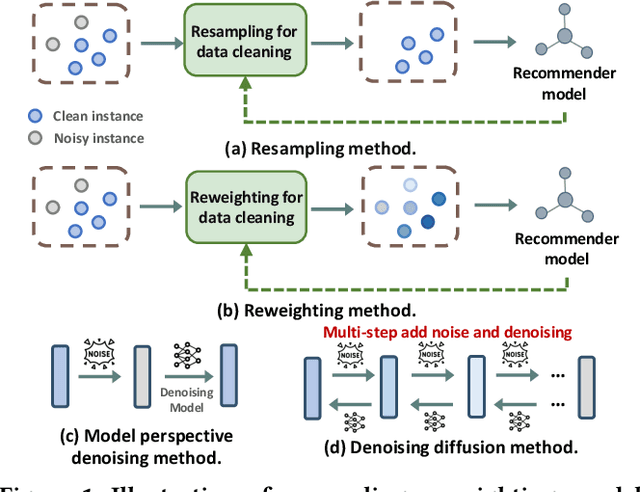

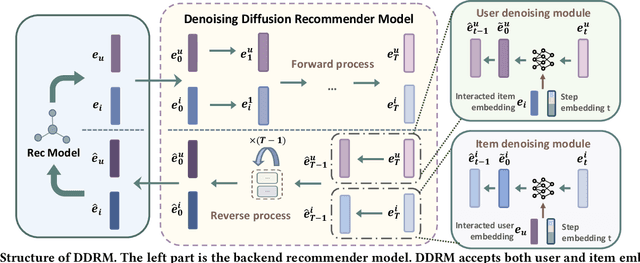
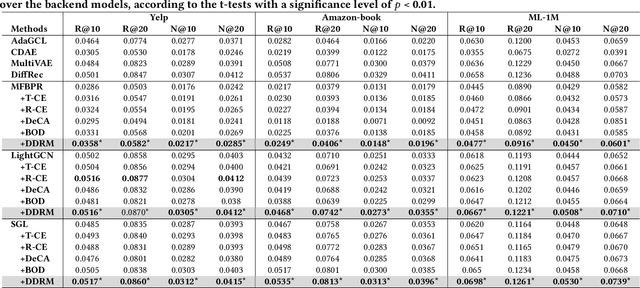
In the realm of recommender systems, handling noisy implicit feedback is a prevalent challenge. While most research efforts focus on mitigating noise through data cleaning methods like resampling and reweighting, these approaches often rely on heuristic assumptions. Alternatively, model perspective denoising strategies actively incorporate noise into user-item interactions, aiming to bolster the model's inherent denoising capabilities. Nonetheless, this type of denoising method presents substantial challenges to the capacity of the recommender model to accurately identify and represent noise patterns. To overcome these hurdles, we introduce a plug-in diffusion model for embedding denoising in recommendation system, which employs a multi-step denoising approach based on diffusion models to foster robust representation learning of embeddings. Our model operates by introducing controlled Gaussian noise into user and item embeddings derived from various recommender systems during the forward phase. Subsequently, it iteratively eliminates this noise in the reverse denoising phase, thereby augmenting the embeddings' resilience to noisy feedback. The primary challenge in this process is determining direction and an optimal starting point for the denoising process. To address this, we incorporate a specialized denoising module that utilizes collaborative data as a guide for the denoising process. Furthermore, during the inference phase, we employ the average of item embeddings previously favored by users as the starting point to facilitate ideal item generation. Our thorough evaluations across three datasets and in conjunction with three classic backend models confirm its superior performance.
General Debiasing for Multimodal Sentiment Analysis
Aug 07, 2023



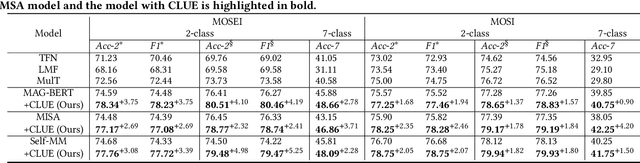
Existing work on Multimodal Sentiment Analysis (MSA) utilizes multimodal information for prediction yet unavoidably suffers from fitting the spurious correlations between multimodal features and sentiment labels. For example, if most videos with a blue background have positive labels in a dataset, the model will rely on such correlations for prediction, while "blue background" is not a sentiment-related feature. To address this problem, we define a general debiasing MSA task, which aims to enhance the Out-Of-Distribution (OOD) generalization ability of MSA models by reducing their reliance on spurious correlations. To this end, we propose a general debiasing framework based on Inverse Probability Weighting (IPW), which adaptively assigns small weights to the samples with larger bias (i.e., the severer spurious correlations). The key to this debiasing framework is to estimate the bias of each sample, which is achieved by two steps: 1) disentangling the robust features and biased features in each modality, and 2) utilizing the biased features to estimate the bias. Finally, we employ IPW to reduce the effects of large-biased samples, facilitating robust feature learning for sentiment prediction. To examine the model's generalization ability, we keep the original testing sets on two benchmarks and additionally construct multiple unimodal and multimodal OOD testing sets. The empirical results demonstrate the superior generalization ability of our proposed framework. We have released the code and data to facilitate the reproduction https://github.com/Teng-Sun/GEAR.
Counterfactual Reasoning for Out-of-distribution Multimodal Sentiment Analysis
Jul 24, 2022
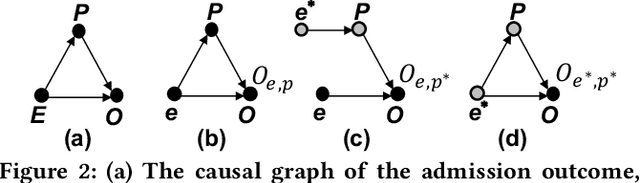
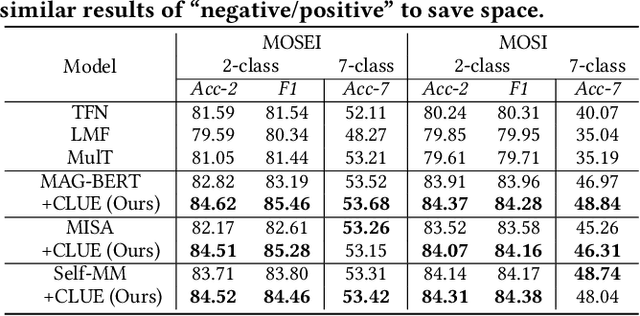
Existing studies on multimodal sentiment analysis heavily rely on textual modality and unavoidably induce the spurious correlations between textual words and sentiment labels. This greatly hinders the model generalization ability. To address this problem, we define the task of out-of-distribution (OOD) multimodal sentiment analysis. This task aims to estimate and mitigate the bad effect of textual modality for strong OOD generalization. To this end, we embrace causal inference, which inspects the causal relationships via a causal graph. From the graph, we find that the spurious correlations are attributed to the direct effect of textual modality on the model prediction while the indirect one is more reliable by considering multimodal semantics. Inspired by this, we devise a model-agnostic counterfactual framework for multimodal sentiment analysis, which captures the direct effect of textual modality via an extra text model and estimates the indirect one by a multimodal model. During the inference, we first estimate the direct effect by the counterfactual inference, and then subtract it from the total effect of all modalities to obtain the indirect effect for reliable prediction. Extensive experiments show the superior effectiveness and generalization ability of our proposed framework.