 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Reasoning for Out-of-distribution Multimodal Sentiment Analysis
Jul 24, 2022
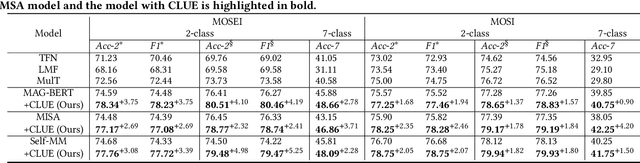
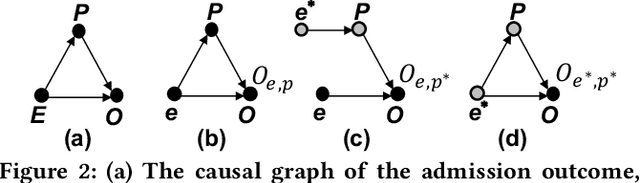
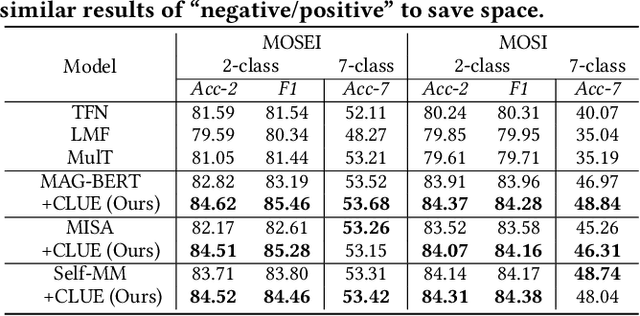
Existing studies on multimodal sentiment analysis heavily rely on textual modality and unavoidably induce the spurious correlations between textual words and sentiment labels. This greatly hinders the model generalization ability. To address this problem, we define the task of out-of-distribution (OOD) multimodal sentiment analysis. This task aims to estimate and mitigate the bad effect of textual modality for strong OOD generalization. To this end, we embrace causal inference, which inspects the causal relationships via a causal graph. From the graph, we find that the spurious correlations are attributed to the direct effect of textual modality on the model prediction while the indirect one is more reliable by considering multimodal semantics. Inspired by this, we devise a model-agnostic counterfactual framework for multimodal sentiment analysis, which captures the direct effect of textual modality via an extra text model and estimates the indirect one by a multimodal model. During the inference, we first estimate the direct effect by the counterfactual inference, and then subtract it from the total effect of all modalities to obtain the indirect effect for reliable prediction. Extensive experiments show the superior effectiveness and generalization ability of our proposed framework.
Seeing Around Obstacles with Terahertz Waves
May 10, 2022
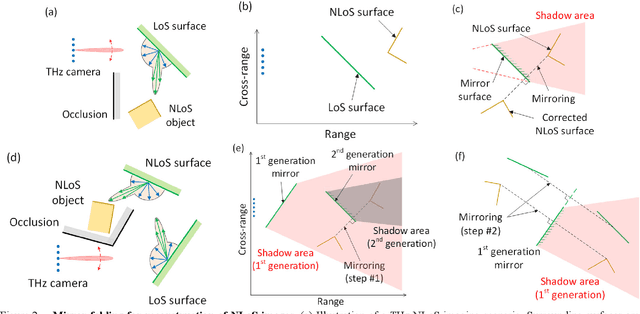


Traditional imaging systems, such as the eye or cameras, image scenes that lie in the direct line-of-sight (LoS). Most objects are opaque in the optical and infrared regimes and can limit dramatically the field of view (FoV). Current approaches to see around occlusions exploit the multireflection propagation of signals from neighboring surfaces either in the microwave or the optical bands. Using lower frequency signals anatomical information is limited and images suffer from clutter while optical systems encounter diffuse scattering from most surfaces and suffer from path loss, thus limiting the imaging distance. In this work, we show that terahertz (THz) waves can be used to extend visibility to non-line-of-sight (NLoS) while combining the advantages of both spectra. The material properties and roughness of most building surfaces allow for a unique combination of both diffuse and strong specular scattering. As a result, most building surfaces behave as lossy mirrors that enable propagation paths between a THz camera and the NLoS scenes. We propose a mirror folding algorithm that tracks the multireflection propagation of THz waves to 1) correct the image from cluttering and 2) see around occlusions without a priori knowledge of the scene geometry and material properties. To validate the feasibility of the proposed NLoS imaging approach, we carried out a numerical analysis and developed two THz imaging systems to demonstrate real-world NLoS imaging experiments in sub-THz bands (270-300 GHz). The results show the capability of THz radar imaging systems to recover both the geometry and pose of LoS and NLoS objects with centimeter-scale resolution in various multipath propagation scenarios. THz NLoS imaging can operate in low visibility conditions (e.g., night, strong ambient light, smoke) and uses computationally inexpensive image reconstruction algorithms.
Hierarchical Deep Residual Reasoning for Temporal Moment Localization
Oct 31, 2021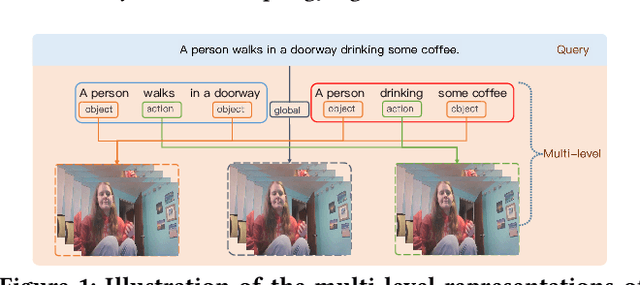
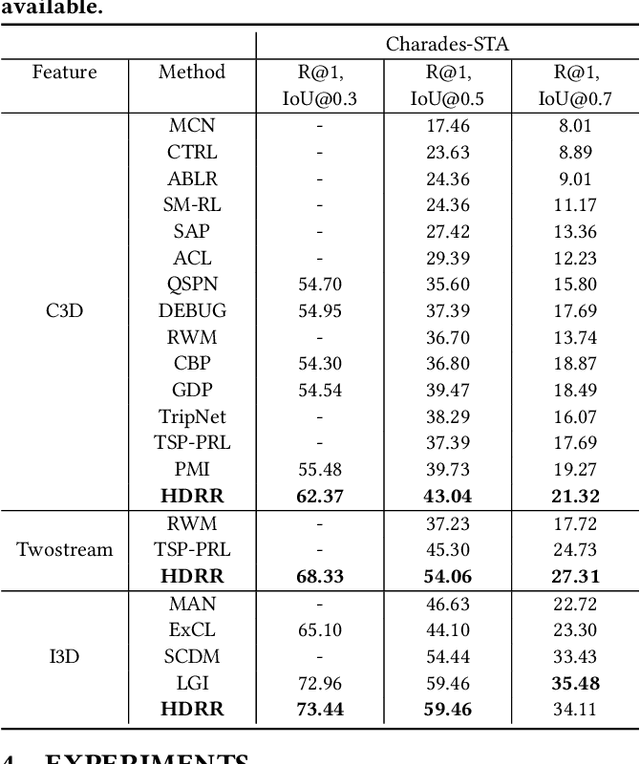
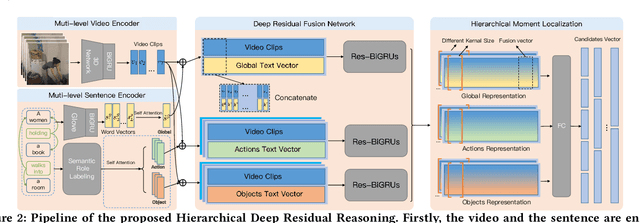
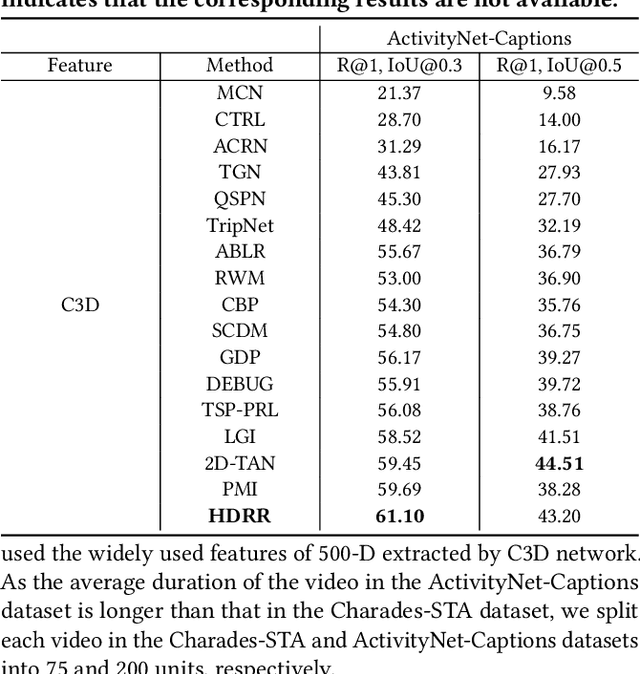
Temporal Moment Localization (TML) in untrimmed videos is a challenging task in the field of multimedia, which aims at localizing the start and end points of the activity in the video, described by a sentence query. Existing methods mainly focus on mining the correlation between video and sentence representations or investigating the fusion manner of the two modalities. These works mainly understand the video and sentence coarsely, ignoring the fact that a sentence can be understood from various semantics, and the dominant words affecting the moment localization in the semantics are the action and object reference. Toward this end, we propose a Hierarchical Deep Residual Reasoning (HDRR) model, which decomposes the video and sentence into multi-level representations with different semantics to achieve a finer-grained localization. Furthermore, considering that videos with different resolution and sentences with different length have different difficulty in understanding, we design the simple yet effective Res-BiGRUs for feature fusion, which is able to grasp the useful information in a self-adapting manner. Extensive experiments conducted on Charades-STA and ActivityNet-Captions datasets demonstrate the superiority of our HDRR model compared with other state-of-the-art methods.