 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Skill-augmented Agentic Framework and Benchmark for Multi-Video Understanding
Mar 16, 2026Multimodal Large Language Models have achieved strong performance in single-video understanding, yet their ability to reason across multiple videos remains limited. Existing approaches typically concatenate multiple videos into a single input and perform direct inference, which introduces training-inference mismatch, information loss from frame compression, and a lack of explicit cross-video coordination. Meanwhile, current multi-video benchmarks primarily emphasize event-level comparison, leaving identity-level matching, fine-grained discrimination, and structured multi-step reasoning underexplored. To address these gaps, we introduce MVX-Bench, a Multi-Video Cross-Dimension Benchmark that reformulates 11 classical computer vision tasks into a unified multi-video question-answering framework, comprising 1,442 questions over 4,255 videos from diverse real-world datasets. We further propose SAMA, a Skill-Augmented Agentic Framework for Multi-Video Understanding, which integrates visual tools, task-specific skills, and a conflict-aware verification mechanism to enable iterative and structured reasoning. Experimental results show that SAMA outperforms strong open-source baselines and GPT on MVX-Bench, and ablations validate the effectiveness of skill design and conflict resolution.
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
Event Extraction in Large Language Model
Dec 22, 2025Large language models (LLMs) and multimodal LLMs are changing event extraction (EE): prompting and generation can often produce structured outputs in zero shot or few shot settings. Yet LLM based pipelines face deployment gaps, including hallucinations under weak constraints, fragile temporal and causal linking over long contexts and across documents, and limited long horizon knowledge management within a bounded context window. We argue that EE should be viewed as a system component that provides a cognitive scaffold for LLM centered solutions. Event schemas and slot constraints create interfaces for grounding and verification; event centric structures act as controlled intermediate representations for stepwise reasoning; event links support relation aware retrieval with graph based RAG; and event stores offer updatable episodic and agent memory beyond the context window. This survey covers EE in text and multimodal settings, organizing tasks and taxonomy, tracing method evolution from rule based and neural models to instruction driven and generative frameworks, and summarizing formulations, decoding strategies, architectures, representations, datasets, and evaluation. We also review cross lingual, low resource, and domain specific settings, and highlight open challenges and future directions for reliable event centric systems. Finally, we outline open challenges and future directions that are central to the LLM era, aiming to evolve EE from static extraction into a structurally reliable, agent ready perception and memory layer for open world systems.
FIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025



Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.
Speech Recognition on TV Series with Video-guided Post-Correction
Jun 08, 2025


Automatic Speech Recognition (ASR) has achieved remarkable success with deep learning, driving advancements in conversational artificial intelligence, media transcription, and assistive technologies. However, ASR systems still struggle in complex environments such as TV series, where overlapping speech, domain-specific terminology, and long-range contextual dependencies pose significant challenges to transcription accuracy. Existing multimodal approaches fail to correct ASR outputs with the rich temporal and contextual information available in video. To address this limitation, we propose a novel multimodal post-correction framework that refines ASR transcriptions by leveraging contextual cues extracted from video. Our framework consists of two stages: ASR Generation and Video-based Post-Correction, where the first stage produces the initial transcript and the second stage corrects errors using Video-based Contextual Information Extraction and Context-aware ASR Correction. We employ the Video-Large Multimodal Model (VLMM) to extract key contextual information using tailored prompts, which is then integrated with a Large Language Model (LLM) to refine the ASR output. We evaluate our method on a multimodal benchmark for TV series ASR and demonstrate its effectiveness in improving ASR performance by leveraging video-based context to enhance transcription accuracy in complex multimedia environments.
A Comprehensive Analysis for Visual Object Hallucination in Large Vision-Language Models
May 04, 2025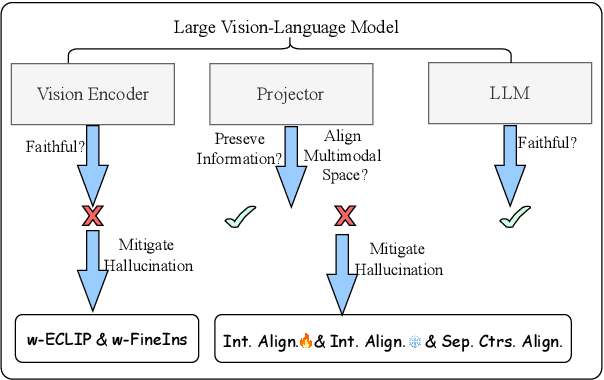
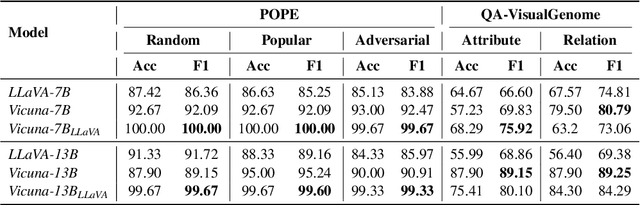

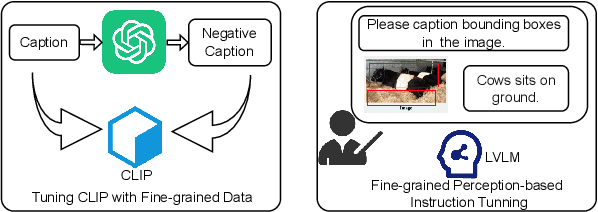
Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in multimodal tasks, but visual object hallucination remains a persistent issue. It refers to scenarios where models generate inaccurate visual object-related information based on the query input, potentially leading to misinformation and concerns about safety and reliability. Previous works focus on the evaluation and mitigation of visual hallucinations, but the underlying causes have not been comprehensively investigated. In this paper, we analyze each component of LLaVA-like LVLMs -- the large language model, the vision backbone, and the projector -- to identify potential sources of error and their impact. Based on our observations, we propose methods to mitigate hallucination for each problematic component. Additionally, we developed two hallucination benchmarks: QA-VisualGenome, which emphasizes attribute and relation hallucinations, and QA-FB15k, which focuses on cognition-based hallucinations.
Learning to Generate Research Idea with Dynamic Control
Dec 19, 2024The rapid advancements in large language models (LLMs) have demonstrated their potential to accelerate scientific discovery, particularly in automating the process of research ideation. LLM-based systems have shown promise in generating hypotheses and research ideas. However, current approaches predominantly rely on prompting-based pre-trained models, limiting their ability to optimize generated content effectively. Moreover, they also lack the capability to deal with the complex interdependence and inherent restrictions among novelty, feasibility, and effectiveness, which remains challenging due to the inherent trade-offs among these dimensions, such as the innovation-feasibility conflict. To address these limitations, we for the first time propose fine-tuning LLMs to be better idea proposers and introduce a novel framework that employs a two-stage approach combining Supervised Fine-Tuning (SFT) and controllable Reinforcement Learning (RL). In the SFT stage, the model learns foundational patterns from pairs of research papers and follow-up ideas. In the RL stage, multi-dimensional reward modeling, guided by fine-grained feedback, evaluates and optimizes the generated ideas across key metrics. Dimensional controllers enable dynamic adjustment of generation, while a sentence-level decoder ensures context-aware emphasis during inference. Our framework provides a balanced approach to research ideation, achieving high-quality outcomes by dynamically navigating the trade-offs among novelty, feasibility, and effectiveness.
Defeasible Visual Entailment: Benchmark, Evaluator, and Reward-Driven Optimization
Dec 19, 2024We introduce a new task called Defeasible Visual Entailment (DVE), where the goal is to allow the modification of the entailment relationship between an image premise and a text hypothesis based on an additional update. While this concept is well-established in Natural Language Inference, it remains unexplored in visual entailment. At a high level, DVE enables models to refine their initial interpretations, leading to improved accuracy and reliability in various applications such as detecting misleading information in images, enhancing visual question answering, and refining decision-making processes in autonomous systems. Existing metrics do not adequately capture the change in the entailment relationship brought by updates. To address this, we propose a novel inference-aware evaluator designed to capture changes in entailment strength induced by updates, using pairwise contrastive learning and categorical information learning. Additionally, we introduce a reward-driven update optimization method to further enhance the quality of updates generated by multimodal models. Experimental results demonstrate the effectiveness of our proposed evaluator and optimization method.
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Sep 24, 2024



Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?
Sep 12, 2024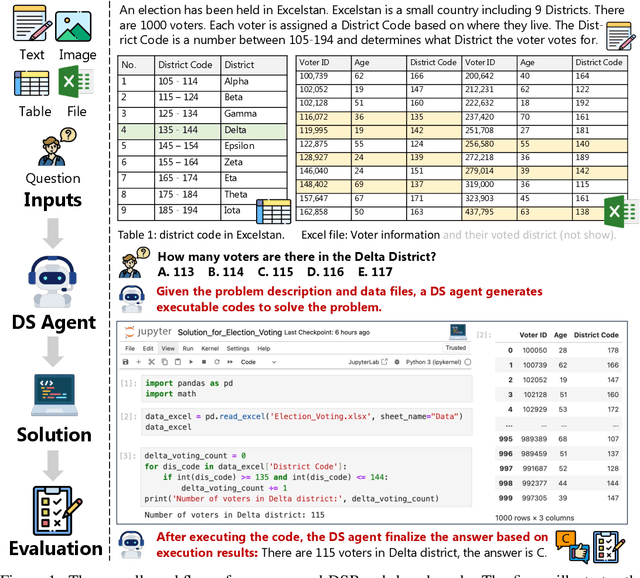
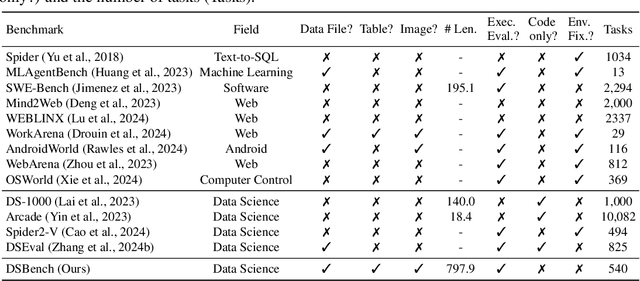
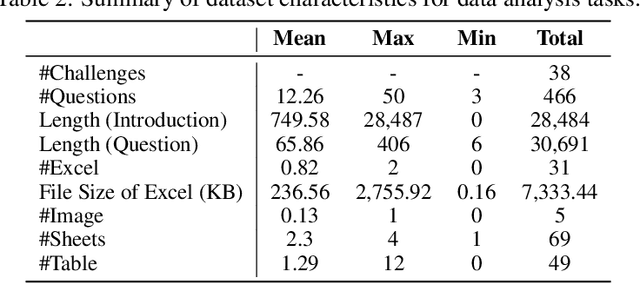
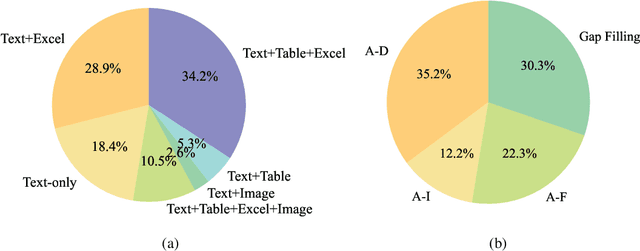
Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers. Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings. To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks. Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.