 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
Conan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence
Oct 23, 2025Video reasoning, which requires multi-step deduction across frames, remains a major challenge for multimodal large language models (MLLMs). While reinforcement learning (RL)-based methods enhance reasoning capabilities, they often rely on text-only chains that yield ungrounded or hallucinated conclusions. Conversely, frame-retrieval approaches introduce visual grounding but still struggle with inaccurate evidence localization. To address these challenges, we present Conan, a framework for evidence-grounded multi-step video reasoning. Conan identifies contextual and evidence frames, reasons over cross-frame clues, and adaptively decides when to conclude or explore further. To achieve this, we (1) construct Conan-91K, a large-scale dataset of automatically generated reasoning traces that includes frame identification, evidence reasoning, and action decision, and (2) design a multi-stage progressive cold-start strategy combined with an Identification-Reasoning-Action (AIR) RLVR training framework to jointly enhance multi-step visual reasoning. Extensive experiments on six multi-step reasoning benchmarks demonstrate that Conan surpasses the baseline Qwen2.5-VL-7B-Instruct by an average of over 10% in accuracy, achieving state-of-the-art performance. Furthermore, Conan generalizes effectively to long-video understanding tasks, validating its strong scalability and robustness.
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
Apr 24, 2025The rapid growth of online video platforms, particularly live streaming services, has created an urgent need for real-time video understanding systems. These systems must process continuous video streams and respond to user queries instantaneously, presenting unique challenges for current Video Large Language Models (VideoLLMs). While existing VideoLLMs excel at processing complete videos, they face significant limitations in streaming scenarios due to their inability to handle dense, redundant frames efficiently. We introduce TimeChat-Online, a novel online VideoLLM that revolutionizes real-time video interaction. At its core lies our innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos. Drawing inspiration from human visual perception's Change Blindness phenomenon, DTD preserves meaningful temporal changes while filtering out static, redundant content between frames. Remarkably, our experiments demonstrate that DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on StreamingBench, revealing that over 80% of visual content in streaming videos is naturally redundant without requiring language guidance. To enable seamless real-time interaction, we present TimeChat-Online-139K, a comprehensive streaming video dataset featuring diverse interaction patterns including backward-tracing, current-perception, and future-responding scenarios. TimeChat-Online's unique Proactive Response capability, naturally achieved through continuous monitoring of video scene transitions via DTD, sets it apart from conventional approaches. Our extensive evaluation demonstrates TimeChat-Online's superior performance on streaming benchmarks (StreamingBench and OvOBench) and maintaining competitive results on long-form video tasks such as Video-MME and MLVU.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Spatial-R1: Enhancing MLLMs in Video Spatial Reasoning
Apr 02, 2025Enhancing the spatial reasoning capabilities of Multi-modal Large Language Models (MLLMs) for video understanding is crucial yet challenging. We present Spatial-R1, a targeted approach involving two key contributions: the curation of SR, a new video spatial reasoning dataset from ScanNet with automatically generated QA pairs across seven task types, and the application of Task-Specific Group Relative Policy Optimization (GRPO) for fine-tuning. By training the Qwen2.5-VL-7B-Instruct model on SR using GRPO, Spatial-R1 significantly advances performance on the VSI-Bench benchmark, achieving a 7.4\% gain over the baseline and outperforming strong contemporary models. This work validates the effectiveness of specialized data curation and optimization techniques for improving complex spatial reasoning in video MLLMs.
Generative Frame Sampler for Long Video Understanding
Mar 12, 2025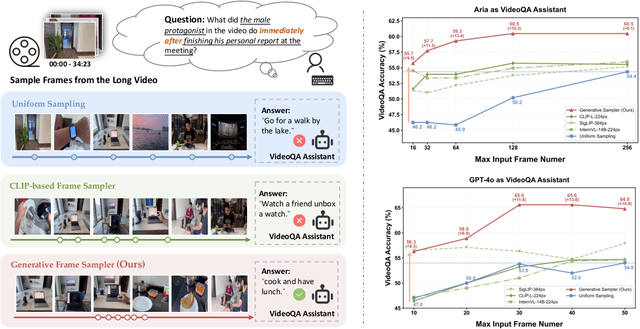
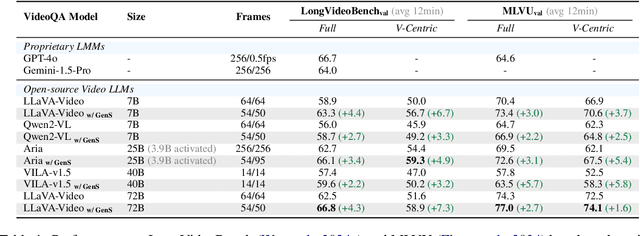
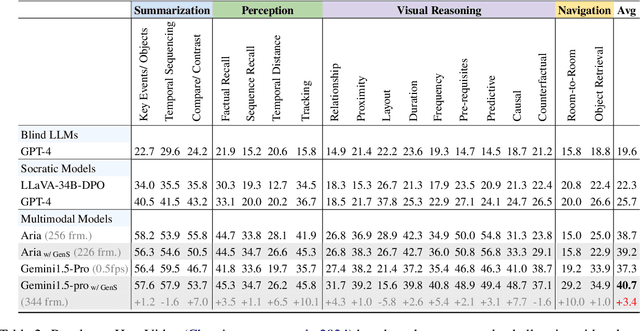

Despite recent advances in Video Large Language Models (VideoLLMs), effectively understanding long-form videos remains a significant challenge. Perceiving lengthy videos containing thousands of frames poses substantial computational burden. To mitigate this issue, this paper introduces Generative Frame Sampler (GenS), a plug-and-play module integrated with VideoLLMs to facilitate efficient lengthy video perception. Built upon a lightweight VideoLLM, GenS leverages its inherent vision-language capabilities to identify question-relevant frames. To facilitate effective retrieval, we construct GenS-Video-150K, a large-scale video instruction dataset with dense frame relevance annotations. Extensive experiments demonstrate that GenS consistently boosts the performance of various VideoLLMs, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini). When equipped with GenS, open-source VideoLLMs achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 (+4.3) on LongVideoBench and 77.0 (+2.7) on MLVU, while Aria obtains 39.2 on HourVideo surpassing the Gemini-1.5-pro by 1.9 points. We will release all datasets and models at https://generative-sampler.github.io.
PunchBench: Benchmarking MLLMs in Multimodal Punchline Comprehension
Dec 16, 2024



Multimodal punchlines, which involve humor or sarcasm conveyed in image-caption pairs, are a popular way of communication on online multimedia platforms. With the rapid development of multimodal large language models (MLLMs), it is essential to assess their ability to effectively comprehend these punchlines. However, existing benchmarks on punchline comprehension suffer from three major limitations: 1) language shortcuts that allow models to solely rely on text, 2) lack of question diversity, and 3) narrow focus on a specific domain of multimodal content (e.g., cartoon). To address these limitations, we introduce a multimodal \textbf{Punch}line comprehension \textbf{Bench}mark, named \textbf{PunchBench}, which is tailored for accurate and comprehensive evaluation of punchline comprehension. To enhance the evaluation accuracy, we generate synonymous and antonymous captions by modifying original captions, which mitigates the impact of shortcuts in the captions. To provide a comprehensive evaluation, PunchBench incorporates diverse question formats and image-captions from various domains. On this basis, we conduct extensive evaluations and reveal a significant gap between state-of-the-art MLLMs and humans in punchline comprehension. To improve punchline comprehension, we propose Simple-to-Complex Chain-of-Question (SC-CoQ) strategy, enabling the models to incrementally address complicated questions by first mastering simple ones. SC-CoQ effectively enhances the performance of various MLLMs on PunchBench, surpassing in-context learning and chain-of-thought.
Sentiment-enhanced Graph-based Sarcasm Explanation in Dialogue
Feb 06, 2024



Sarcasm Explanation in Dialogue (SED) is a new yet challenging task, which aims to generate a natural language explanation for the given sarcastic dialogue that involves multiple modalities (i.e., utterance, video, and audio). Although existing studies have achieved great success based on the generative pretrained language model BART, they overlook exploiting the sentiments residing in the utterance, video and audio, which are vital clues for sarcasm explanation. In fact, it is non-trivial to incorporate sentiments for boosting SED performance, due to three main challenges: 1) diverse effects of utterance tokens on sentiments; 2) gap between video-audio sentiment signals and the embedding space of BART; and 3) various relations among utterances, utterance sentiments, and video-audio sentiments. To tackle these challenges, we propose a novel sEntiment-enhanceD Graph-based multimodal sarcasm Explanation framework, named EDGE. In particular, we first propose a lexicon-guided utterance sentiment inference module, where a heuristic utterance sentiment refinement strategy is devised. We then develop a module named Joint Cross Attention-based Sentiment Inference (JCA-SI) by extending the multimodal sentiment analysis model JCA to derive the joint sentiment label for each video-audio clip. Thereafter, we devise a context-sentiment graph to comprehensively model the semantic relations among the utterances, utterance sentiments, and video-audio sentiments, to facilitate sarcasm explanation generation. Extensive experiments on the publicly released dataset WITS verify the superiority of our model over cutting-edge methods.