 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Towards Pixel-Level VLM Perception via Simple Points Prediction
Jan 27, 2026We present SimpleSeg, a strikingly simple yet highly effective approach to endow Multimodal Large Language Models (MLLMs) with native pixel-level perception. Our method reframes segmentation as a simple sequence generation problem: the model directly predicts sequences of points (textual coordinates) delineating object boundaries, entirely within its language space. To achieve high fidelity, we introduce a two-stage SF$\to$RL training pipeline, where Reinforcement Learning with an IoU-based reward refines the point sequences to accurately match ground-truth contours. We find that the standard MLLM architecture possesses a strong, inherent capacity for low-level perception that can be unlocked without any specialized architecture. On segmentation benchmarks, SimpleSeg achieves performance that is comparable to, and often surpasses, methods relying on complex, task-specific designs. This work lays out that precise spatial understanding can emerge from simple point prediction, challenging the prevailing need for auxiliary components and paving the way for more unified and capable VLMs. Homepage: https://simpleseg.github.io/
Affinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
StableMotion: Repurposing Diffusion-Based Image Priors for Motion Estimation
May 10, 2025



We present StableMotion, a novel framework leverages knowledge (geometry and content priors) from pretrained large-scale image diffusion models to perform motion estimation, solving single-image-based image rectification tasks such as Stitched Image Rectangling (SIR) and Rolling Shutter Correction (RSC). Specifically, StableMotion framework takes text-to-image Stable Diffusion (SD) models as backbone and repurposes it into an image-to-motion estimator. To mitigate inconsistent output produced by diffusion models, we propose Adaptive Ensemble Strategy (AES) that consolidates multiple outputs into a cohesive, high-fidelity result. Additionally, we present the concept of Sampling Steps Disaster (SSD), the counterintuitive scenario where increasing the number of sampling steps can lead to poorer outcomes, which enables our framework to achieve one-step inference. StableMotion is verified on two image rectification tasks and delivers state-of-the-art performance in both, as well as showing strong generalizability. Supported by SSD, StableMotion offers a speedup of 200 times compared to previous diffusion model-based methods.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
TimeLoc: A Unified End-to-End Framework for Precise Timestamp Localization in Long Videos
Mar 09, 2025
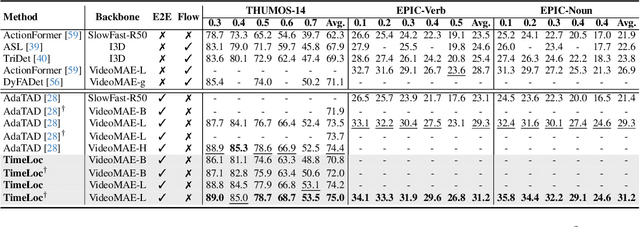
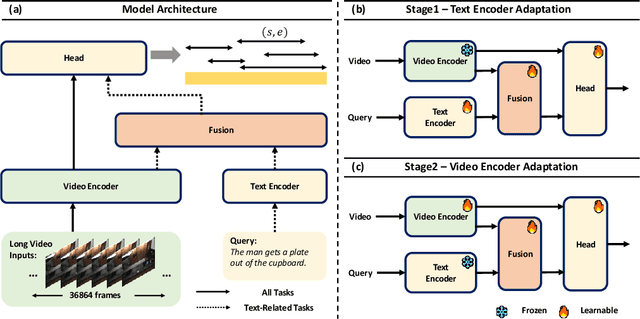
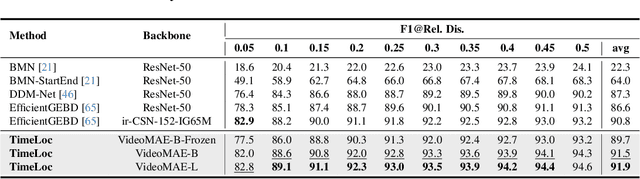
Temporal localization in untrimmed videos, which aims to identify specific timestamps, is crucial for video understanding but remains challenging. This task encompasses several subtasks, including temporal action localization, temporal video grounding, moment retrieval, and generic event boundary detection. Existing methods in each subfield are typically designed for specific tasks and lack generalizability across domains. In this paper, we propose TimeLoc, a unified end-to-end framework for timestamp localization that can handle multiple tasks. First, our approach employs a simple yet effective one-stage localization model that supports text queries as input and multiple actions as output. Second, we jointly train the video encoder and localization model in an end-to-end manner. To efficiently process long videos, we introduce temporal chunking, enabling the handling of videos with over 30k frames. Third, we find that fine-tuning pre-trained text encoders with a multi-stage training strategy further enhances text-conditioned localization. TimeLoc achieves state-of-the-art results across multiple benchmarks: +1.3% and +1.9% mAP over previous best methods on THUMOS14 and EPIC-Kitchens-100, +1.1% on Kinetics-GEBD, +2.94% mAP on QVHighlights, and significant improvements in temporal video grounding (+11.5% on TACoS and +6.7% on Charades-STA under R1@0.5). Our code and checkpoints will be released at https://github.com/sming256/TimeLoc.
Harnessing Temporal Causality for Advanced Temporal Action Detection
Jul 26, 2024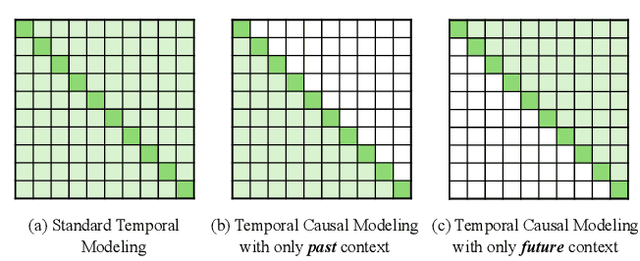

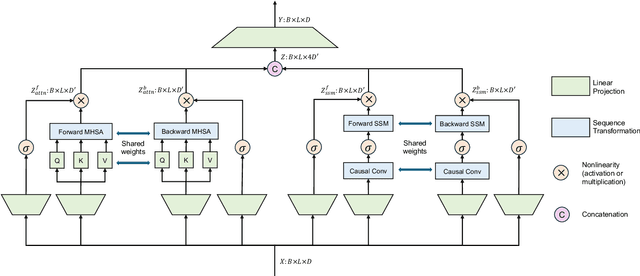

As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.