 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Real-World Parking Slot Detection with Large-Scale Dataset and Semi-Supervised Baseline
Sep 16, 2025As automatic parking systems evolve, the accurate detection of parking slots has become increasingly critical. This study focuses on parking slot detection using surround-view cameras, which offer a comprehensive bird's-eye view of the parking environment. However, the current datasets are limited in scale, and the scenes they contain are seldom disrupted by real-world noise (e.g., light, occlusion, etc.). Moreover, manual data annotation is prone to errors and omissions due to the complexity of real-world conditions, significantly increasing the cost of annotating large-scale datasets. To address these issues, we first construct a large-scale parking slot detection dataset (named CRPS-D), which includes various lighting distributions, diverse weather conditions, and challenging parking slot variants. Compared with existing datasets, the proposed dataset boasts the largest data scale and consists of a higher density of parking slots, particularly featuring more slanted parking slots. Additionally, we develop a semi-supervised baseline for parking slot detection, termed SS-PSD, to further improve performance by exploiting unlabeled data. To our knowledge, this is the first semi-supervised approach in parking slot detection, which is built on the teacher-student model with confidence-guided mask consistency and adaptive feature perturbation. Experimental results demonstrate the superiority of SS-PSD over the existing state-of-the-art (SoTA) solutions on both the proposed dataset and the existing dataset. Particularly, the more unlabeled data there is, the more significant the gains brought by our semi-supervised scheme. The relevant source codes and the dataset have been made publicly available at https://github.com/zzh362/CRPS-D.
From Editor to Dense Geometry Estimator
Sep 04, 2025
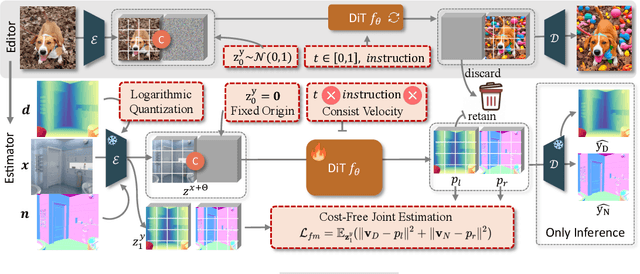


Leveraging visual priors from pre-trained text-to-image (T2I) generative models has shown success in dense prediction. However, dense prediction is inherently an image-to-image task, suggesting that image editing models, rather than T2I generative models, may be a more suitable foundation for fine-tuning. Motivated by this, we conduct a systematic analysis of the fine-tuning behaviors of both editors and generators for dense geometry estimation. Our findings show that editing models possess inherent structural priors, which enable them to converge more stably by ``refining" their innate features, and ultimately achieve higher performance than their generative counterparts. Based on these findings, we introduce \textbf{FE2E}, a framework that pioneeringly adapts an advanced editing model based on Diffusion Transformer (DiT) architecture for dense geometry prediction. Specifically, to tailor the editor for this deterministic task, we reformulate the editor's original flow matching loss into the ``consistent velocity" training objective. And we use logarithmic quantization to resolve the precision conflict between the editor's native BFloat16 format and the high precision demand of our tasks. Additionally, we leverage the DiT's global attention for a cost-free joint estimation of depth and normals in a single forward pass, enabling their supervisory signals to mutually enhance each other. Without scaling up the training data, FE2E achieves impressive performance improvements in zero-shot monocular depth and normal estimation across multiple datasets. Notably, it achieves over 35\% performance gains on the ETH3D dataset and outperforms the DepthAnything series, which is trained on 100$\times$ data. The project page can be accessed \href{https://amap-ml.github.io/FE2E/}{here}.
StableMotion: Repurposing Diffusion-Based Image Priors for Motion Estimation
May 10, 2025



We present StableMotion, a novel framework leverages knowledge (geometry and content priors) from pretrained large-scale image diffusion models to perform motion estimation, solving single-image-based image rectification tasks such as Stitched Image Rectangling (SIR) and Rolling Shutter Correction (RSC). Specifically, StableMotion framework takes text-to-image Stable Diffusion (SD) models as backbone and repurposes it into an image-to-motion estimator. To mitigate inconsistent output produced by diffusion models, we propose Adaptive Ensemble Strategy (AES) that consolidates multiple outputs into a cohesive, high-fidelity result. Additionally, we present the concept of Sampling Steps Disaster (SSD), the counterintuitive scenario where increasing the number of sampling steps can lead to poorer outcomes, which enables our framework to achieve one-step inference. StableMotion is verified on two image rectification tasks and delivers state-of-the-art performance in both, as well as showing strong generalizability. Supported by SSD, StableMotion offers a speedup of 200 times compared to previous diffusion model-based methods.
StabStitch++: Unsupervised Online Video Stitching with Spatiotemporal Bidirectional Warps
May 08, 2025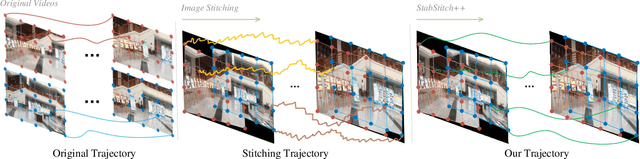
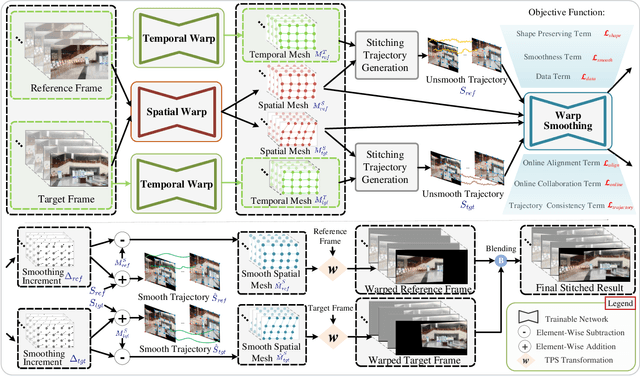
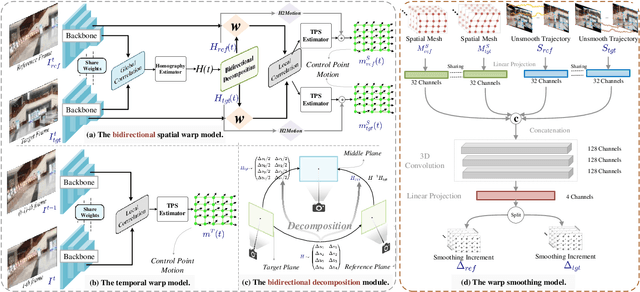
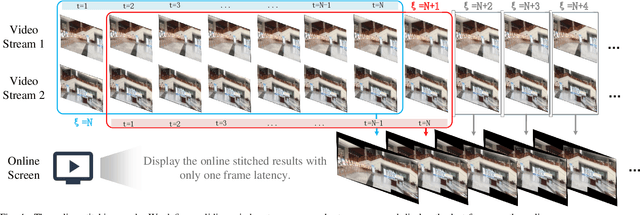
We retarget video stitching to an emerging issue, named warping shake, which unveils the temporal content shakes induced by sequentially unsmooth warps when extending image stitching to video stitching. Even if the input videos are stable, the stitched video can inevitably cause undesired warping shakes and affect the visual experience. To address this issue, we propose StabStitch++, a novel video stitching framework to realize spatial stitching and temporal stabilization with unsupervised learning simultaneously. First, different from existing learning-based image stitching solutions that typically warp one image to align with another, we suppose a virtual midplane between original image planes and project them onto it. Concretely, we design a differentiable bidirectional decomposition module to disentangle the homography transformation and incorporate it into our spatial warp, evenly spreading alignment burdens and projective distortions across two views. Then, inspired by camera paths in video stabilization, we derive the mathematical expression of stitching trajectories in video stitching by elaborately integrating spatial and temporal warps. Finally, a warp smoothing model is presented to produce stable stitched videos with a hybrid loss to simultaneously encourage content alignment, trajectory smoothness, and online collaboration. Compared with StabStitch that sacrifices alignment for stabilization, StabStitch++ makes no compromise and optimizes both of them simultaneously, especially in the online mode. To establish an evaluation benchmark and train the learning framework, we build a video stitching dataset with a rich diversity in camera motions and scenes. Experiments exhibit that StabStitch++ surpasses current solutions in stitching performance, robustness, and efficiency, offering compelling advancements in this field by building a real-time online video stitching system.
You Need a Transition Plane: Bridging Continuous Panoramic 3D Reconstruction with Perspective Gaussian Splatting
Apr 12, 2025Recently, reconstructing scenes from a single panoramic image using advanced 3D Gaussian Splatting (3DGS) techniques has attracted growing interest. Panoramic images offer a 360$\times$ 180 field of view (FoV), capturing the entire scene in a single shot. However, panoramic images introduce severe distortion, making it challenging to render 3D Gaussians into 2D distorted equirectangular space directly. Converting equirectangular images to cubemap projections partially alleviates this problem but introduces new challenges, such as projection distortion and discontinuities across cube-face boundaries. To address these limitations, we present a novel framework, named TPGS, to bridge continuous panoramic 3D scene reconstruction with perspective Gaussian splatting. Firstly, we introduce a Transition Plane between adjacent cube faces to enable smoother transitions in splatting directions and mitigate optimization ambiguity in the boundary region. Moreover, an intra-to-inter face optimization strategy is proposed to enhance local details and restore visual consistency across cube-face boundaries. Specifically, we optimize 3D Gaussians within individual cube faces and then fine-tune them in the stitched panoramic space. Additionally, we introduce a spherical sampling technique to eliminate visible stitching seams. Extensive experiments on indoor and outdoor, egocentric, and roaming benchmark datasets demonstrate that our approach outperforms existing state-of-the-art methods. Code and models will be available at https://github.com/zhijieshen-bjtu/TPGS.
Beyond Wide-Angle Images: Unsupervised Video Portrait Correction via Spatiotemporal Diffusion Adaptation
Apr 01, 2025Wide-angle cameras, despite their popularity for content creation, suffer from distortion-induced facial stretching-especially at the edge of the lens-which degrades visual appeal. To address this issue, we propose an image portrait correction framework using diffusion models named ImagePD. It integrates the long-range awareness of transformer and multi-step denoising of diffusion models into a unified framework, achieving global structural robustness and local detail refinement. Besides, considering the high cost of obtaining video labels, we then repurpose ImagePD for unlabeled wide-angle videos (termed VideoPD), by spatiotemporal diffusion adaption with spatial consistency and temporal smoothness constraints. For the former, we encourage the denoised image to approximate pseudo labels following the wide-angle distortion distribution pattern, while for the latter, we derive rectification trajectories with backward optical flows and smooth them. Compared with ImagePD, VideoPD maintains high-quality facial corrections in space and mitigates the potential temporal shakes sequentially. Finally, to establish an evaluation benchmark and train the framework, we establish a video portrait dataset with a large diversity in people number, lighting conditions, and background. Experiments demonstrate that the proposed methods outperform existing solutions quantitatively and qualitatively, contributing to high-fidelity wide-angle videos with stable and natural portraits. The codes and dataset will be available.
Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
Mar 20, 2025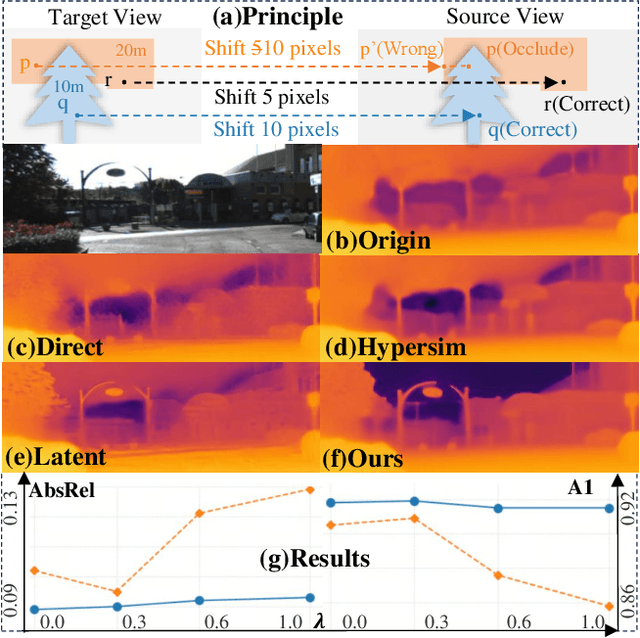
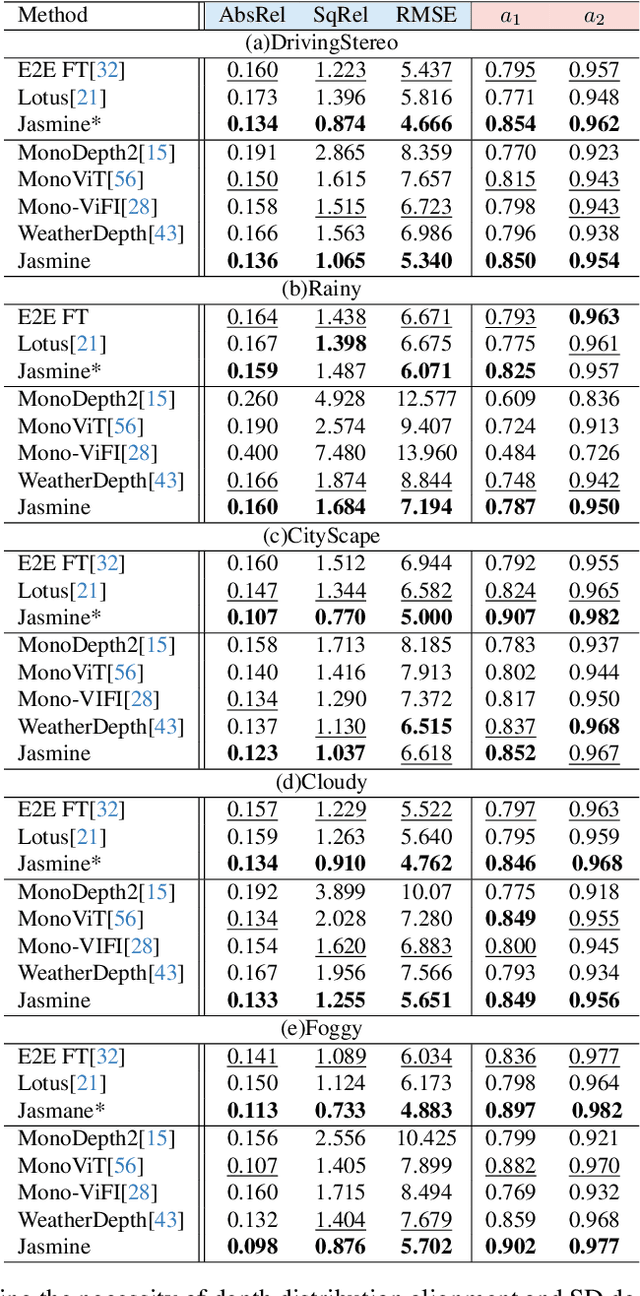
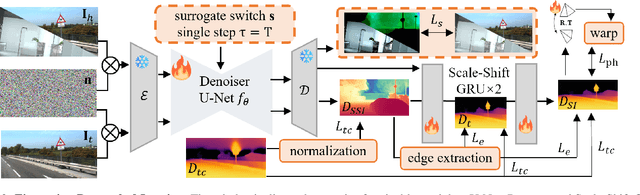
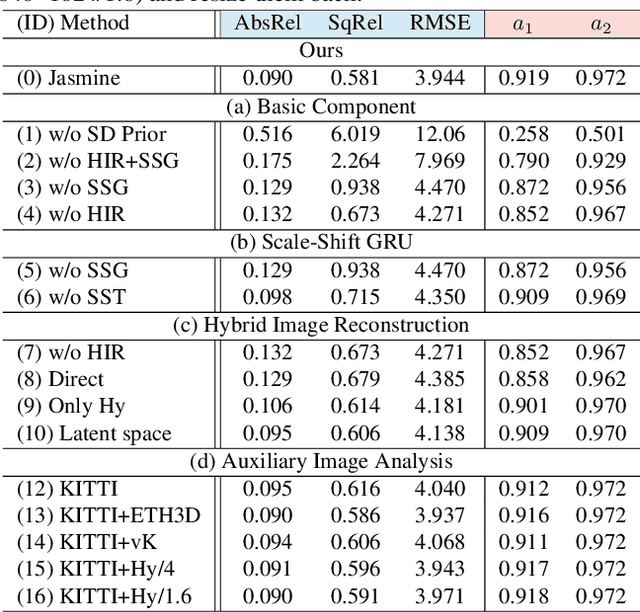
In this paper, we propose Jasmine, the first Stable Diffusion (SD)-based self-supervised framework for monocular depth estimation, which effectively harnesses SD's visual priors to enhance the sharpness and generalization of unsupervised prediction. Previous SD-based methods are all supervised since adapting diffusion models for dense prediction requires high-precision supervision. In contrast, self-supervised reprojection suffers from inherent challenges (e.g., occlusions, texture-less regions, illumination variance), and the predictions exhibit blurs and artifacts that severely compromise SD's latent priors. To resolve this, we construct a novel surrogate task of hybrid image reconstruction. Without any additional supervision, it preserves the detail priors of SD models by reconstructing the images themselves while preventing depth estimation from degradation. Furthermore, to address the inherent misalignment between SD's scale and shift invariant estimation and self-supervised scale-invariant depth estimation, we build the Scale-Shift GRU. It not only bridges this distribution gap but also isolates the fine-grained texture of SD output against the interference of reprojection loss. Extensive experiments demonstrate that Jasmine achieves SoTA performance on the KITTI benchmark and exhibits superior zero-shot generalization across multiple datasets.
Semi-Supervised 360 Layout Estimation with Panoramic Collaborative Perturbations
Mar 03, 2025The performance of existing supervised layout estimation methods heavily relies on the quality of data annotations. However, obtaining large-scale and high-quality datasets remains a laborious and time-consuming challenge. To solve this problem, semi-supervised approaches are introduced to relieve the demand for expensive data annotations by encouraging the consistent results of unlabeled data with different perturbations. However, existing solutions merely employ vanilla perturbations, ignoring the characteristics of panoramic layout estimation. In contrast, we propose a novel semi-supervised method named SemiLayout360, which incorporates the priors of the panoramic layout and distortion through collaborative perturbations. Specifically, we leverage the panoramic layout prior to enhance the model's focus on potential layout boundaries. Meanwhile, we introduce the panoramic distortion prior to strengthen distortion awareness. Furthermore, to prevent intense perturbations from hindering model convergence and ensure the effectiveness of prior-based perturbations, we divide and reorganize them as panoramic collaborative perturbations. Our experimental results on three mainstream benchmarks demonstrate that the proposed method offers significant advantages over existing state-of-the-art (SoTA) solutions.
Revisiting 360 Depth Estimation with PanoGabor: A New Fusion Perspective
Aug 30, 2024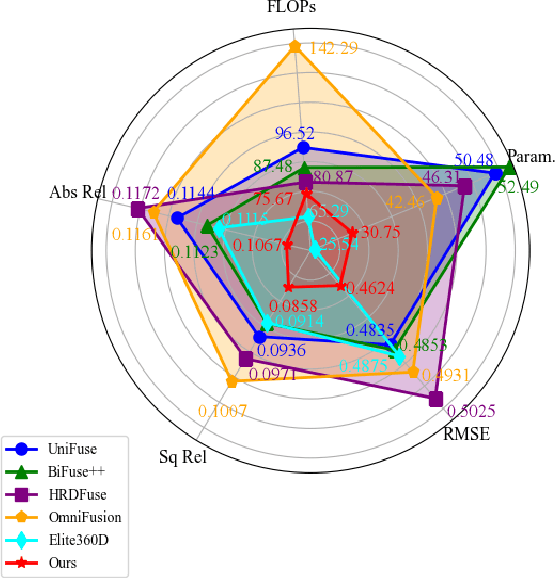
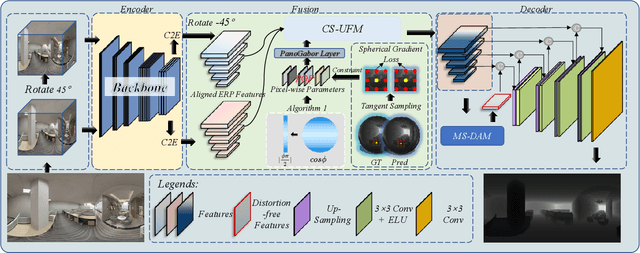

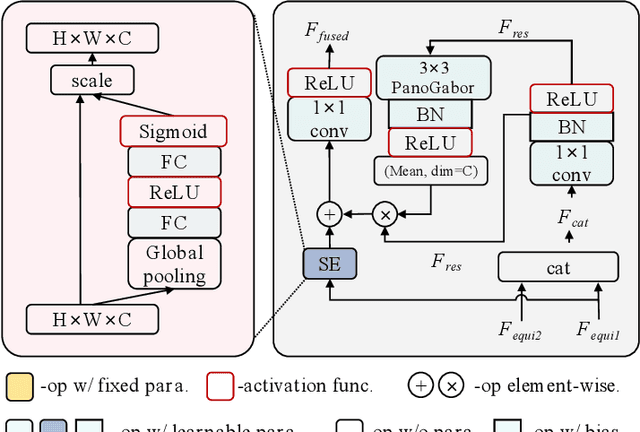
Depth estimation from a monocular 360 image is important to the perception of the entire 3D environment. However, the inherent distortion and large field of view (FoV) in 360 images pose great challenges for this task. To this end, existing mainstream solutions typically introduce additional perspective-based 360 representations (\textit{e.g.}, Cubemap) to achieve effective feature extraction. Nevertheless, regardless of the introduced representations, they eventually need to be unified into the equirectangular projection (ERP) format for the subsequent depth estimation, which inevitably reintroduces the troublesome distortions. In this work, we propose an oriented distortion-aware Gabor Fusion framework (PGFuse) to address the above challenges. First, we introduce Gabor filters that analyze texture in the frequency domain, thereby extending the receptive fields and enhancing depth cues. To address the reintroduced distortions, we design a linear latitude-aware distortion representation method to generate customized, distortion-aware Gabor filters (PanoGabor filters). Furthermore, we design a channel-wise and spatial-wise unidirectional fusion module (CS-UFM) that integrates the proposed PanoGabor filters to unify other representations into the ERP format, delivering effective and distortion-free features. Considering the orientation sensitivity of the Gabor transform, we introduce a spherical gradient constraint to stabilize this sensitivity. Experimental results on three popular indoor 360 benchmarks demonstrate the superiority of the proposed PGFuse to existing state-of-the-art solutions. Code can be available upon acceptance.
SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
Apr 23, 2024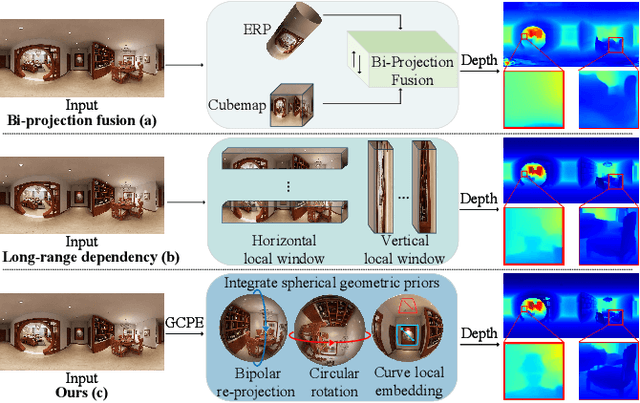
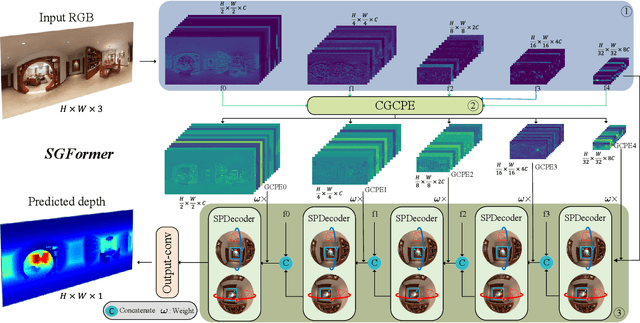
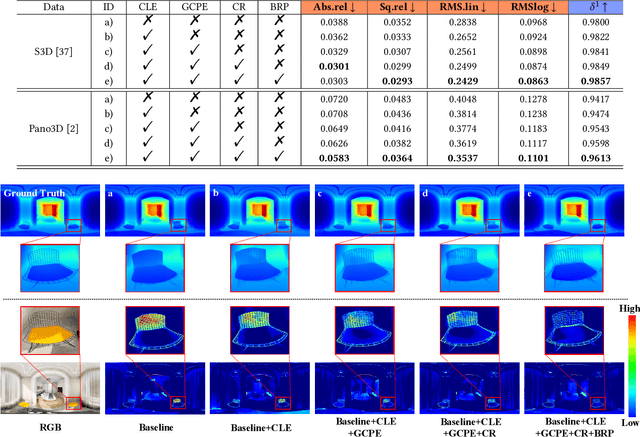
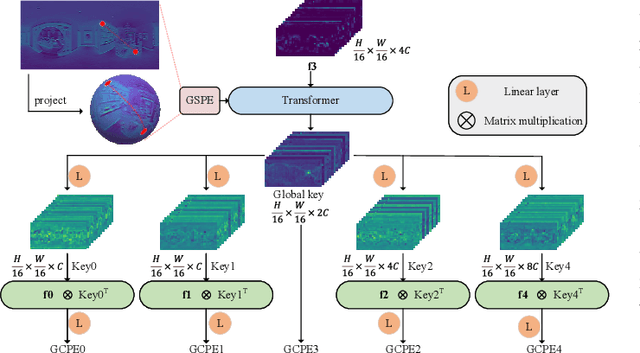
Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles. Existing methods either adopt a bi-projection fusion strategy to remove distortions or model long-range dependencies to capture global structures, which can result in either unclear structure or insufficient local perception. In this paper, we propose a spherical geometry transformer, named SGFormer, to address the above issues, with an innovative step to integrate spherical geometric priors into vision transformers. To this end, we retarget the transformer decoder to a spherical prior decoder (termed SPDecoder), which endeavors to uphold the integrity of spherical structures during decoding. Concretely, we leverage bipolar re-projection, circular rotation, and curve local embedding to preserve the spherical characteristics of equidistortion, continuity, and surface distance, respectively. Furthermore, we present a query-based global conditional position embedding to compensate for spatial structure at varying resolutions. It not only boosts the global perception of spatial position but also sharpens the depth structure across different patches. Finally, we conduct extensive experiments on popular benchmarks, demonstrating our superiority over state-of-the-art solutions.