 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
Mar 15, 2026While Large Language Models (LLMs) have evolved into tool-using agents, they remain brittle in long-horizon interactions. Unlike mathematical reasoning where errors are often rectifiable via backtracking, tool-use failures frequently induce irreversible side effects, making accurate step-level verification critical. However, existing process-level benchmarks are predominantly confined to closed-world mathematical domains, failing to capture the dynamic and open-ended nature of tool execution. To bridge this gap, we introduce AgentProcessBench, the first benchmark dedicated to evaluating step-level effectiveness in realistic, tool-augmented trajectories. The benchmark comprises 1,000 diverse trajectories and 8,509 human-labeled step annotations with 89.1% inter-annotator agreement. It features a ternary labeling scheme to capture exploration and an error propagation rule to reduce labeling ambiguity. Extensive experiments reveal key insights: (1) weaker policy models exhibit inflated ratios of correct steps due to early termination; (2) distinguishing neutral and erroneous actions remains a significant challenge for current models; and (3) process-derived signals provide complementary value to outcome supervision, significantly enhancing test-time scaling. We hope AgentProcessBench can foster future research in reward models and pave the way toward general agents. The code and data are available at https://github.com/RUCBM/AgentProcessBench.
DreamVAR: Taming Reinforced Visual Autoregressive Model for High-Fidelity Subject-Driven Image Generation
Jan 30, 2026Recent advances in subject-driven image generation using diffusion models have attracted considerable attention for their remarkable capabilities in producing high-quality images. Nevertheless, the potential of Visual Autoregressive (VAR) models, despite their unified architecture and efficient inference, remains underexplored. In this work, we present DreamVAR, a novel framework for subject-driven image synthesis built upon a VAR model that employs next-scale prediction. Technically, multi-scale features of the reference subject are first extracted by a visual tokenizer. Instead of interleaving these conditional features with target image tokens across scales, our DreamVAR pre-fills the full subject feature sequence prior to predicting target image tokens. This design simplifies autoregressive dependencies and mitigates the train-test discrepancy in multi-scale conditioning scenario within the VAR paradigm. DreamVAR further incorporates reinforcement learning to jointly enhance semantic alignment and subject consistency. Extensive experiments demonstrate that DreamVAR achieves superior appearance preservation compared to leading diffusion-based methods.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Incorporating Visual Correspondence into Diffusion Model for Virtual Try-On
May 22, 2025



Diffusion models have shown preliminary success in virtual try-on (VTON) task. The typical dual-branch architecture comprises two UNets for implicit garment deformation and synthesized image generation respectively, and has emerged as the recipe for VTON task. Nevertheless, the problem remains challenging to preserve the shape and every detail of the given garment due to the intrinsic stochasticity of diffusion model. To alleviate this issue, we novelly propose to explicitly capitalize on visual correspondence as the prior to tame diffusion process instead of simply feeding the whole garment into UNet as the appearance reference. Specifically, we interpret the fine-grained appearance and texture details as a set of structured semantic points, and match the semantic points rooted in garment to the ones over target person through local flow warping. Such 2D points are then augmented into 3D-aware cues with depth/normal map of target person. The correspondence mimics the way of putting clothing on human body and the 3D-aware cues act as semantic point matching to supervise diffusion model training. A point-focused diffusion loss is further devised to fully take the advantage of semantic point matching. Extensive experiments demonstrate strong garment detail preservation of our approach, evidenced by state-of-the-art VTON performances on both VITON-HD and DressCode datasets. Code is publicly available at: https://github.com/HiDream-ai/SPM-Diff.
DeepCritic: Deliberate Critique with Large Language Models
May 01, 2025As Large Language Models (LLMs) are rapidly evolving, providing accurate feedback and scalable oversight on their outputs becomes an urgent and critical problem. Leveraging LLMs as critique models to achieve automated supervision is a promising solution. In this work, we focus on studying and enhancing the math critique ability of LLMs. Current LLM critics provide critiques that are too shallow and superficial on each step, leading to low judgment accuracy and struggling to offer sufficient feedback for the LLM generator to correct mistakes. To tackle this issue, we propose a novel and effective two-stage framework to develop LLM critics that are capable of deliberately critiquing on each reasoning step of math solutions. In the first stage, we utilize Qwen2.5-72B-Instruct to generate 4.5K long-form critiques as seed data for supervised fine-tuning. Each seed critique consists of deliberate step-wise critiques that includes multi-perspective verifications as well as in-depth critiques of initial critiques for each reasoning step. Then, we perform reinforcement learning on the fine-tuned model with either existing human-labeled data from PRM800K or our automatically annotated data obtained via Monte Carlo sampling-based correctness estimation, to further incentivize its critique ability. Our developed critique model built on Qwen2.5-7B-Instruct not only significantly outperforms existing LLM critics (including the same-sized DeepSeek-R1-distill models and GPT-4o) on various error identification benchmarks, but also more effectively helps the LLM generator refine erroneous steps through more detailed feedback.
Beyond Wide-Angle Images: Unsupervised Video Portrait Correction via Spatiotemporal Diffusion Adaptation
Apr 01, 2025Wide-angle cameras, despite their popularity for content creation, suffer from distortion-induced facial stretching-especially at the edge of the lens-which degrades visual appeal. To address this issue, we propose an image portrait correction framework using diffusion models named ImagePD. It integrates the long-range awareness of transformer and multi-step denoising of diffusion models into a unified framework, achieving global structural robustness and local detail refinement. Besides, considering the high cost of obtaining video labels, we then repurpose ImagePD for unlabeled wide-angle videos (termed VideoPD), by spatiotemporal diffusion adaption with spatial consistency and temporal smoothness constraints. For the former, we encourage the denoised image to approximate pseudo labels following the wide-angle distortion distribution pattern, while for the latter, we derive rectification trajectories with backward optical flows and smooth them. Compared with ImagePD, VideoPD maintains high-quality facial corrections in space and mitigates the potential temporal shakes sequentially. Finally, to establish an evaluation benchmark and train the framework, we establish a video portrait dataset with a large diversity in people number, lighting conditions, and background. Experiments demonstrate that the proposed methods outperform existing solutions quantitatively and qualitatively, contributing to high-fidelity wide-angle videos with stable and natural portraits. The codes and dataset will be available.
Unleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
Dec 31, 2024Recently, zero-shot image captioning has gained increasing attention, where only text data is available for training. The remarkable progress in text-to-image diffusion model presents the potential to resolve this task by employing synthetic image-caption pairs generated by this pre-trained prior. Nonetheless, the defective details in the salient regions of the synthetic images introduce semantic misalignment between the synthetic image and text, leading to compromised results. To address this challenge, we propose a novel Patch-wise Cross-modal feature Mix-up (PCM) mechanism to adaptively mitigate the unfaithful contents in a fine-grained manner during training, which can be integrated into most of encoder-decoder frameworks, introducing our PCM-Net. Specifically, for each input image, salient visual concepts in the image are first detected considering the image-text similarity in CLIP space. Next, the patch-wise visual features of the input image are selectively fused with the textual features of the salient visual concepts, leading to a mixed-up feature map with less defective content. Finally, a visual-semantic encoder is exploited to refine the derived feature map, which is further incorporated into the sentence decoder for caption generation. Additionally, to facilitate the model training with synthetic data, a novel CLIP-weighted cross-entropy loss is devised to prioritize the high-quality image-text pairs over the low-quality counterparts. Extensive experiments on MSCOCO and Flickr30k datasets demonstrate the superiority of our PCM-Net compared with state-of-the-art VLMs-based approaches. It is noteworthy that our PCM-Net ranks first in both in-domain and cross-domain zero-shot image captioning. The synthetic dataset SynthImgCap and code are available at https://jianjieluo.github.io/SynthImgCap.
Improving Virtual Try-On with Garment-focused Diffusion Models
Sep 12, 2024


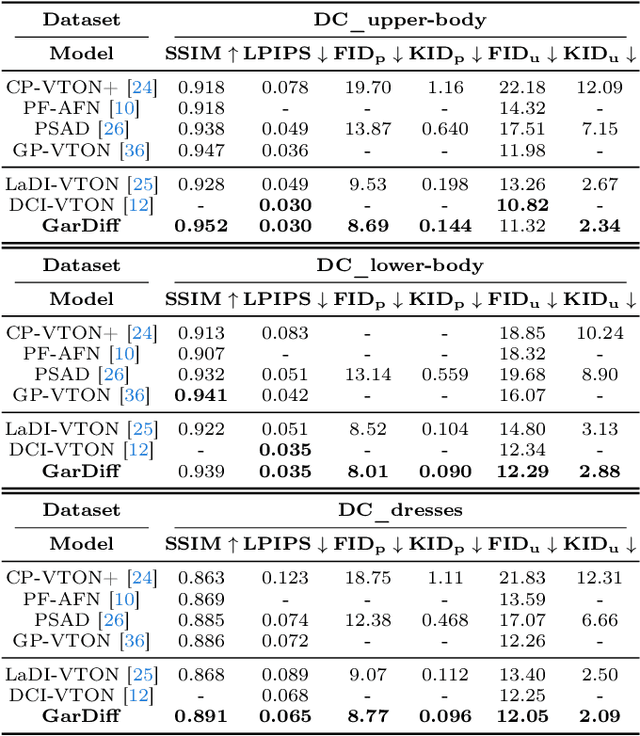
Diffusion models have led to the revolutionizing of generative modeling in numerous image synthesis tasks. Nevertheless, it is not trivial to directly apply diffusion models for synthesizing an image of a target person wearing a given in-shop garment, i.e., image-based virtual try-on (VTON) task. The difficulty originates from the aspect that the diffusion process should not only produce holistically high-fidelity photorealistic image of the target person, but also locally preserve every appearance and texture detail of the given garment. To address this, we shape a new Diffusion model, namely GarDiff, which triggers the garment-focused diffusion process with amplified guidance of both basic visual appearance and detailed textures (i.e., high-frequency details) derived from the given garment. GarDiff first remoulds a pre-trained latent diffusion model with additional appearance priors derived from the CLIP and VAE encodings of the reference garment. Meanwhile, a novel garment-focused adapter is integrated into the UNet of diffusion model, pursuing local fine-grained alignment with the visual appearance of reference garment and human pose. We specifically design an appearance loss over the synthesized garment to enhance the crucial, high-frequency details. Extensive experiments on VITON-HD and DressCode datasets demonstrate the superiority of our GarDiff when compared to state-of-the-art VTON approaches. Code is publicly available at: \href{https://github.com/siqi0905/GarDiff/tree/master}{https://github.com/siqi0905/GarDiff/tree/master}.
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Sep 12, 2024Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at \url{https://github.com/Nnn-s/CATdiffusion}.
ControlStyle: Text-Driven Stylized Image Generation Using Diffusion Priors
Nov 09, 2023



Recently, the multimedia community has witnessed the rise of diffusion models trained on large-scale multi-modal data for visual content creation, particularly in the field of text-to-image generation. In this paper, we propose a new task for ``stylizing'' text-to-image models, namely text-driven stylized image generation, that further enhances editability in content creation. Given input text prompt and style image, this task aims to produce stylized images which are both semantically relevant to input text prompt and meanwhile aligned with the style image in style. To achieve this, we present a new diffusion model (ControlStyle) via upgrading a pre-trained text-to-image model with a trainable modulation network enabling more conditions of text prompts and style images. Moreover, diffusion style and content regularizations are simultaneously introduced to facilitate the learning of this modulation network with these diffusion priors, pursuing high-quality stylized text-to-image generation. Extensive experiments demonstrate the effectiveness of our ControlStyle in producing more visually pleasing and artistic results, surpassing a simple combination of text-to-image model and conventional style transfer techniques.