 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduled Sampling in Vision-Language Pretraining with Decoupled Encoder-Decoder Network
Paper and Code



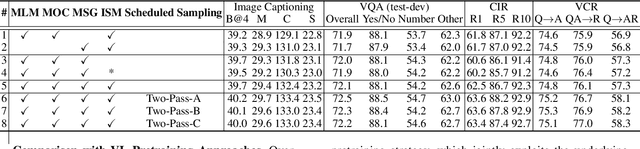
Despite having impressive vision-language (VL) pretraining with BERT-based encoder for VL understanding, the pretraining of a universal encoder-decoder for both VL understanding and generation remains challenging. The difficulty originates from the inherently different peculiarities of the two disciplines, e.g., VL understanding tasks capitalize on the unrestricted message passing across modalities, while generation tasks only employ visual-to-textual message passing. In this paper, we start with a two-stream decoupled design of encoder-decoder structure, in which two decoupled cross-modal encoder and decoder are involved to separately perform each type of proxy tasks, for simultaneous VL understanding and generation pretraining. Moreover, for VL pretraining, the dominant way is to replace some input visual/word tokens with mask tokens and enforce the multi-modal encoder/decoder to reconstruct the original tokens, but no mask token is involved when fine-tuning on downstream tasks. As an alternative, we propose a primary scheduled sampling strategy that elegantly mitigates such discrepancy via pretraining encoder-decoder in a two-pass manner. Extensive experiments demonstrate the compelling generalizability of our pretrained encoder-decoder by fine-tuning on four VL understanding and generation downstream tasks. Source code is available at \url{https://github.com/YehLi/TDEN}.