 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamVAR: Taming Reinforced Visual Autoregressive Model for High-Fidelity Subject-Driven Image Generation
Jan 30, 2026Recent advances in subject-driven image generation using diffusion models have attracted considerable attention for their remarkable capabilities in producing high-quality images. Nevertheless, the potential of Visual Autoregressive (VAR) models, despite their unified architecture and efficient inference, remains underexplored. In this work, we present DreamVAR, a novel framework for subject-driven image synthesis built upon a VAR model that employs next-scale prediction. Technically, multi-scale features of the reference subject are first extracted by a visual tokenizer. Instead of interleaving these conditional features with target image tokens across scales, our DreamVAR pre-fills the full subject feature sequence prior to predicting target image tokens. This design simplifies autoregressive dependencies and mitigates the train-test discrepancy in multi-scale conditioning scenario within the VAR paradigm. DreamVAR further incorporates reinforcement learning to jointly enhance semantic alignment and subject consistency. Extensive experiments demonstrate that DreamVAR achieves superior appearance preservation compared to leading diffusion-based methods.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Hierarchical Masked Autoregressive Models with Low-Resolution Token Pivots
May 26, 2025Autoregressive models have emerged as a powerful generative paradigm for visual generation. The current de-facto standard of next token prediction commonly operates over a single-scale sequence of dense image tokens, and is incapable of utilizing global context especially for early tokens prediction. In this paper, we introduce a new autoregressive design to model a hierarchy from a few low-resolution image tokens to the typical dense image tokens, and delve into a thorough hierarchical dependency across multi-scale image tokens. Technically, we present a Hierarchical Masked Autoregressive models (Hi-MAR) that pivot on low-resolution image tokens to trigger hierarchical autoregressive modeling in a multi-phase manner. Hi-MAR learns to predict a few image tokens in low resolution, functioning as intermediary pivots to reflect global structure, in the first phase. Such pivots act as the additional guidance to strengthen the next autoregressive modeling phase by shaping global structural awareness of typical dense image tokens. A new Diffusion Transformer head is further devised to amplify the global context among all tokens for mask token prediction. Extensive evaluations on both class-conditional and text-to-image generation tasks demonstrate that Hi-MAR outperforms typical AR baselines, while requiring fewer computational costs. Code is available at https://github.com/HiDream-ai/himar.
Unleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
Dec 31, 2024Recently, zero-shot image captioning has gained increasing attention, where only text data is available for training. The remarkable progress in text-to-image diffusion model presents the potential to resolve this task by employing synthetic image-caption pairs generated by this pre-trained prior. Nonetheless, the defective details in the salient regions of the synthetic images introduce semantic misalignment between the synthetic image and text, leading to compromised results. To address this challenge, we propose a novel Patch-wise Cross-modal feature Mix-up (PCM) mechanism to adaptively mitigate the unfaithful contents in a fine-grained manner during training, which can be integrated into most of encoder-decoder frameworks, introducing our PCM-Net. Specifically, for each input image, salient visual concepts in the image are first detected considering the image-text similarity in CLIP space. Next, the patch-wise visual features of the input image are selectively fused with the textual features of the salient visual concepts, leading to a mixed-up feature map with less defective content. Finally, a visual-semantic encoder is exploited to refine the derived feature map, which is further incorporated into the sentence decoder for caption generation. Additionally, to facilitate the model training with synthetic data, a novel CLIP-weighted cross-entropy loss is devised to prioritize the high-quality image-text pairs over the low-quality counterparts. Extensive experiments on MSCOCO and Flickr30k datasets demonstrate the superiority of our PCM-Net compared with state-of-the-art VLMs-based approaches. It is noteworthy that our PCM-Net ranks first in both in-domain and cross-domain zero-shot image captioning. The synthetic dataset SynthImgCap and code are available at https://jianjieluo.github.io/SynthImgCap.
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Sep 12, 2024Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at \url{https://github.com/Nnn-s/CATdiffusion}.
Improving Virtual Try-On with Garment-focused Diffusion Models
Sep 12, 2024


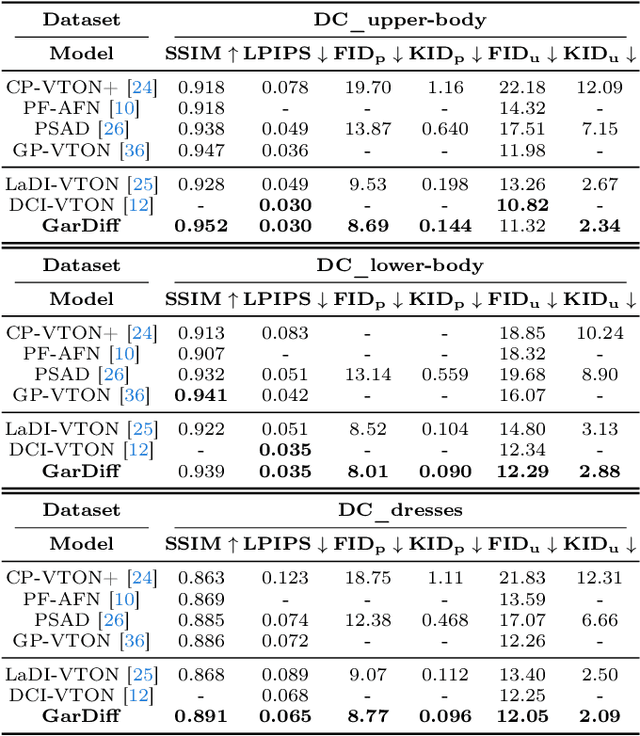
Diffusion models have led to the revolutionizing of generative modeling in numerous image synthesis tasks. Nevertheless, it is not trivial to directly apply diffusion models for synthesizing an image of a target person wearing a given in-shop garment, i.e., image-based virtual try-on (VTON) task. The difficulty originates from the aspect that the diffusion process should not only produce holistically high-fidelity photorealistic image of the target person, but also locally preserve every appearance and texture detail of the given garment. To address this, we shape a new Diffusion model, namely GarDiff, which triggers the garment-focused diffusion process with amplified guidance of both basic visual appearance and detailed textures (i.e., high-frequency details) derived from the given garment. GarDiff first remoulds a pre-trained latent diffusion model with additional appearance priors derived from the CLIP and VAE encodings of the reference garment. Meanwhile, a novel garment-focused adapter is integrated into the UNet of diffusion model, pursuing local fine-grained alignment with the visual appearance of reference garment and human pose. We specifically design an appearance loss over the synthesized garment to enhance the crucial, high-frequency details. Extensive experiments on VITON-HD and DressCode datasets demonstrate the superiority of our GarDiff when compared to state-of-the-art VTON approaches. Code is publicly available at: \href{https://github.com/siqi0905/GarDiff/tree/master}{https://github.com/siqi0905/GarDiff/tree/master}.
Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
Mar 26, 2024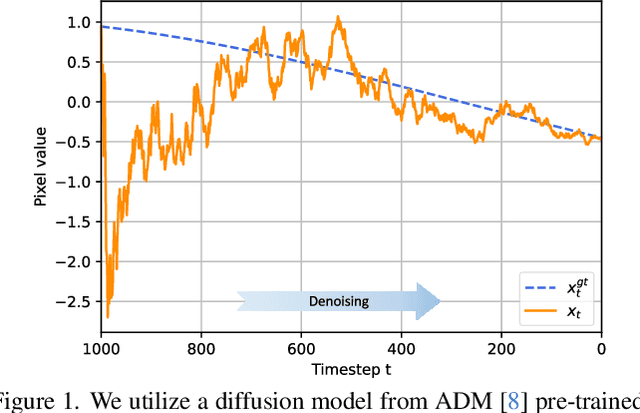
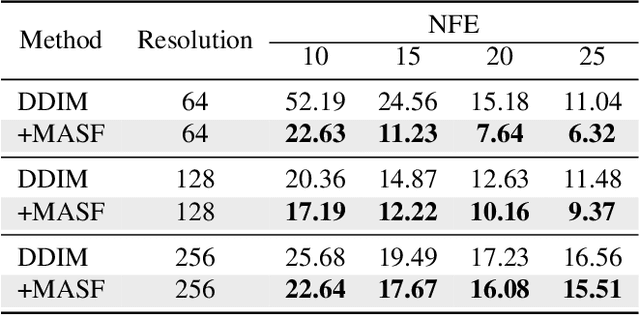

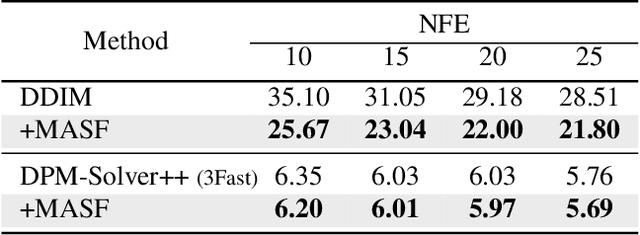
Diffusion models have recently brought a powerful revolution in image generation. Despite showing impressive generative capabilities, most of these models rely on the current sample to denoise the next one, possibly resulting in denoising instability. In this paper, we reinterpret the iterative denoising process as model optimization and leverage a moving average mechanism to ensemble all the prior samples. Instead of simply applying moving average to the denoised samples at different timesteps, we first map the denoised samples to data space and then perform moving average to avoid distribution shift across timesteps. In view that diffusion models evolve the recovery from low-frequency components to high-frequency details, we further decompose the samples into different frequency components and execute moving average separately on each component. We name the complete approach "Moving Average Sampling in Frequency domain (MASF)". MASF could be seamlessly integrated into mainstream pre-trained diffusion models and sampling schedules. Extensive experiments on both unconditional and conditional diffusion models demonstrate that our MASF leads to superior performances compared to the baselines, with almost negligible additional complexity cost.
SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
Mar 25, 2024Diffusion Transformer (DiT) has emerged as the new trend of generative diffusion models on image generation. In view of extremely slow convergence in typical DiT, recent breakthroughs have been driven by mask strategy that significantly improves the training efficiency of DiT with additional intra-image contextual learning. Despite this progress, mask strategy still suffers from two inherent limitations: (a) training-inference discrepancy and (b) fuzzy relations between mask reconstruction & generative diffusion process, resulting in sub-optimal training of DiT. In this work, we address these limitations by novelly unleashing the self-supervised discrimination knowledge to boost DiT training. Technically, we frame our DiT in a teacher-student manner. The teacher-student discriminative pairs are built on the diffusion noises along the same Probability Flow Ordinary Differential Equation (PF-ODE). Instead of applying mask reconstruction loss over both DiT encoder and decoder, we decouple DiT encoder and decoder to separately tackle discriminative and generative objectives. In particular, by encoding discriminative pairs with student and teacher DiT encoders, a new discriminative loss is designed to encourage the inter-image alignment in the self-supervised embedding space. After that, student samples are fed into student DiT decoder to perform the typical generative diffusion task. Extensive experiments are conducted on ImageNet dataset, and our method achieves a competitive balance between training cost and generative capacity.
HIRI-ViT: Scaling Vision Transformer with High Resolution Inputs
Mar 18, 2024
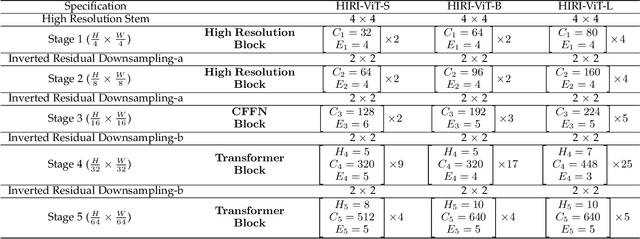


The hybrid deep models of Vision Transformer (ViT) and Convolution Neural Network (CNN) have emerged as a powerful class of backbones for vision tasks. Scaling up the input resolution of such hybrid backbones naturally strengthes model capacity, but inevitably suffers from heavy computational cost that scales quadratically. Instead, we present a new hybrid backbone with HIgh-Resolution Inputs (namely HIRI-ViT), that upgrades prevalent four-stage ViT to five-stage ViT tailored for high-resolution inputs. HIRI-ViT is built upon the seminal idea of decomposing the typical CNN operations into two parallel CNN branches in a cost-efficient manner. One high-resolution branch directly takes primary high-resolution features as inputs, but uses less convolution operations. The other low-resolution branch first performs down-sampling and then utilizes more convolution operations over such low-resolution features. Experiments on both recognition task (ImageNet-1K dataset) and dense prediction tasks (COCO and ADE20K datasets) demonstrate the superiority of HIRI-ViT. More remarkably, under comparable computational cost ($\sim$5.0 GFLOPs), HIRI-ViT achieves to-date the best published Top-1 accuracy of 84.3% on ImageNet with 448$\times$448 inputs, which absolutely improves 83.4% of iFormer-S by 0.9% with 224$\times$224 inputs.
Control3D: Towards Controllable Text-to-3D Generation
Nov 09, 2023Recent remarkable advances in large-scale text-to-image diffusion models have inspired a significant breakthrough in text-to-3D generation, pursuing 3D content creation solely from a given text prompt. However, existing text-to-3D techniques lack a crucial ability in the creative process: interactively control and shape the synthetic 3D contents according to users' desired specifications (e.g., sketch). To alleviate this issue, we present the first attempt for text-to-3D generation conditioning on the additional hand-drawn sketch, namely Control3D, which enhances controllability for users. In particular, a 2D conditioned diffusion model (ControlNet) is remoulded to guide the learning of 3D scene parameterized as NeRF, encouraging each view of 3D scene aligned with the given text prompt and hand-drawn sketch. Moreover, we exploit a pre-trained differentiable photo-to-sketch model to directly estimate the sketch of the rendered image over synthetic 3D scene. Such estimated sketch along with each sampled view is further enforced to be geometrically consistent with the given sketch, pursuing better controllable text-to-3D generation. Through extensive experiments, we demonstrate that our proposal can generate accurate and faithful 3D scenes that align closely with the input text prompts and sketches.