 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Constraint In-Context Generation for Instructional Video Editing
Dec 19, 2025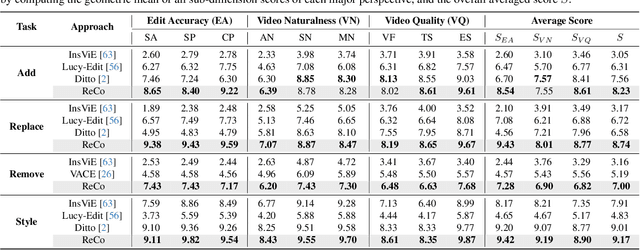
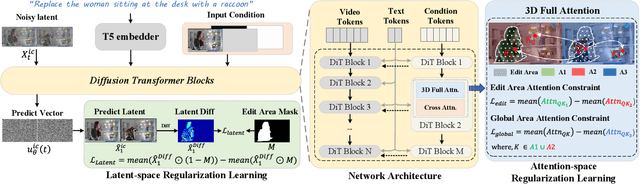

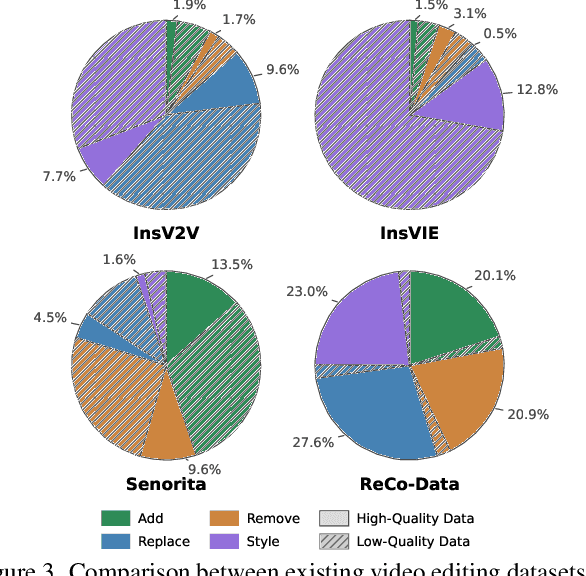
The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality. Nevertheless, shaping such in-context learning for instruction-based video editing is not trivial. Without specifying editing regions, the results can suffer from the problem of inaccurate editing regions and the token interference between editing and non-editing areas during denoising. To address these, we present ReCo, a new instructional video editing paradigm that novelly delves into constraint modeling between editing and non-editing regions during in-context generation. Technically, ReCo width-wise concatenates source and target video for joint denoising. To calibrate video diffusion learning, ReCo capitalizes on two regularization terms, i.e., latent and attention regularization, conducting on one-step backward denoised latents and attention maps, respectively. The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas, emphasizing the modification on editing area and alleviating outside unexpected content generation. The latter suppresses the attention of tokens in the editing region to the tokens in counterpart of the source video, thereby mitigating their interference during novel object generation in target video. Furthermore, we propose a large-scale, high-quality video editing dataset, i.e., ReCo-Data, comprising 500K instruction-video pairs to benefit model training. Extensive experiments conducted on four major instruction-based video editing tasks demonstrate the superiority of our proposal.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
MotionPro: A Precise Motion Controller for Image-to-Video Generation
May 26, 2025



Animating images with interactive motion control has garnered popularity for image-to-video (I2V) generation. Modern approaches typically rely on large Gaussian kernels to extend motion trajectories as condition without explicitly defining movement region, leading to coarse motion control and failing to disentangle object and camera moving. To alleviate these, we present MotionPro, a precise motion controller that novelly leverages region-wise trajectory and motion mask to regulate fine-grained motion synthesis and identify target motion category (i.e., object or camera moving), respectively. Technically, MotionPro first estimates the flow maps on each training video via a tracking model, and then samples the region-wise trajectories to simulate inference scenario. Instead of extending flow through large Gaussian kernels, our region-wise trajectory approach enables more precise control by directly utilizing trajectories within local regions, thereby effectively characterizing fine-grained movements. A motion mask is simultaneously derived from the predicted flow maps to capture the holistic motion dynamics of the movement regions. To pursue natural motion control, MotionPro further strengthens video denoising by incorporating both region-wise trajectories and motion mask through feature modulation. More remarkably, we meticulously construct a benchmark, i.e., MC-Bench, with 1.1K user-annotated image-trajectory pairs, for the evaluation of both fine-grained and object-level I2V motion control. Extensive experiments conducted on WebVid-10M and MC-Bench demonstrate the effectiveness of MotionPro. Please refer to our project page for more results: https://zhw-zhang.github.io/MotionPro-page/.
Ouroboros-Diffusion: Exploring Consistent Content Generation in Tuning-free Long Video Diffusion
Jan 15, 2025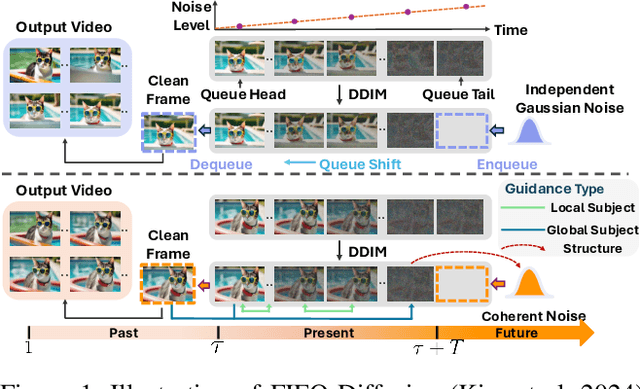

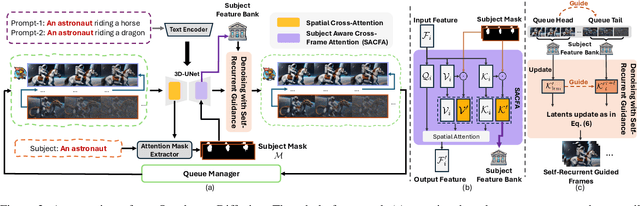

The first-in-first-out (FIFO) video diffusion, built on a pre-trained text-to-video model, has recently emerged as an effective approach for tuning-free long video generation. This technique maintains a queue of video frames with progressively increasing noise, continuously producing clean frames at the queue's head while Gaussian noise is enqueued at the tail. However, FIFO-Diffusion often struggles to keep long-range temporal consistency in the generated videos due to the lack of correspondence modeling across frames. In this paper, we propose Ouroboros-Diffusion, a novel video denoising framework designed to enhance structural and content (subject) consistency, enabling the generation of consistent videos of arbitrary length. Specifically, we introduce a new latent sampling technique at the queue tail to improve structural consistency, ensuring perceptually smooth transitions among frames. To enhance subject consistency, we devise a Subject-Aware Cross-Frame Attention (SACFA) mechanism, which aligns subjects across frames within short segments to achieve better visual coherence. Furthermore, we introduce self-recurrent guidance. This technique leverages information from all previous cleaner frames at the front of the queue to guide the denoising of noisier frames at the end, fostering rich and contextual global information interaction. Extensive experiments of long video generation on the VBench benchmark demonstrate the superiority of our Ouroboros-Diffusion, particularly in terms of subject consistency, motion smoothness, and temporal consistency.
FreeEnhance: Tuning-Free Image Enhancement via Content-Consistent Noising-and-Denoising Process
Sep 11, 2024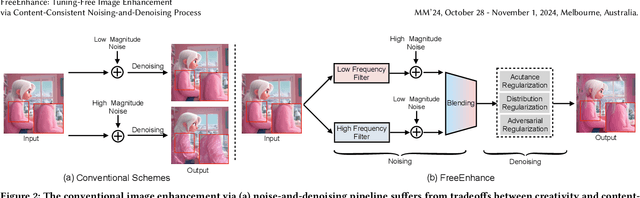
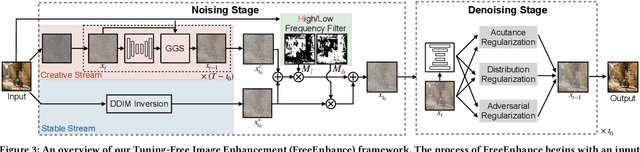
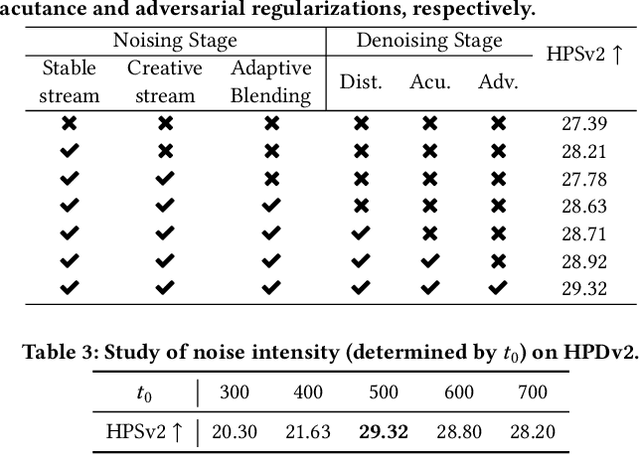

The emergence of text-to-image generation models has led to the recognition that image enhancement, performed as post-processing, would significantly improve the visual quality of the generated images. Exploring diffusion models to enhance the generated images nevertheless is not trivial and necessitates to delicately enrich plentiful details while preserving the visual appearance of key content in the original image. In this paper, we propose a novel framework, namely FreeEnhance, for content-consistent image enhancement using the off-the-shelf image diffusion models. Technically, FreeEnhance is a two-stage process that firstly adds random noise to the input image and then capitalizes on a pre-trained image diffusion model (i.e., Latent Diffusion Models) to denoise and enhance the image details. In the noising stage, FreeEnhance is devised to add lighter noise to the region with higher frequency to preserve the high-frequent patterns (e.g., edge, corner) in the original image. In the denoising stage, we present three target properties as constraints to regularize the predicted noise, enhancing images with high acutance and high visual quality. Extensive experiments conducted on the HPDv2 dataset demonstrate that our FreeEnhance outperforms the state-of-the-art image enhancement models in terms of quantitative metrics and human preference. More remarkably, FreeEnhance also shows higher human preference compared to the commercial image enhancement solution of Magnific AI.
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
Mar 25, 2024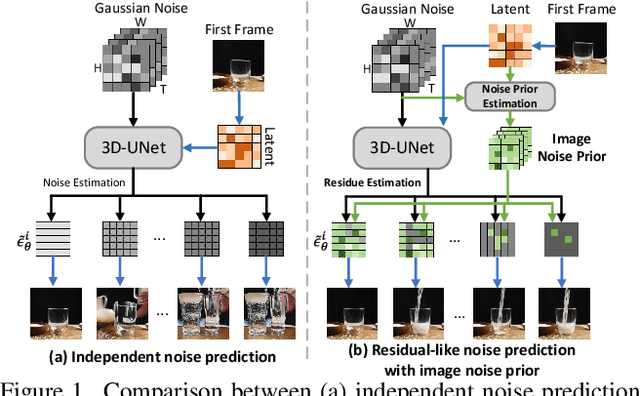
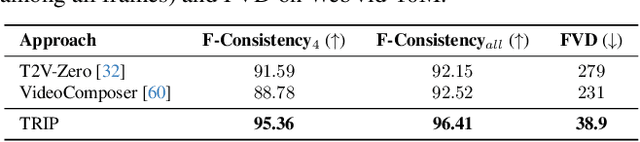
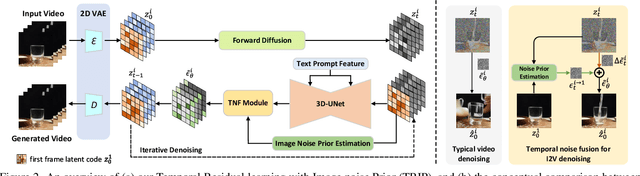
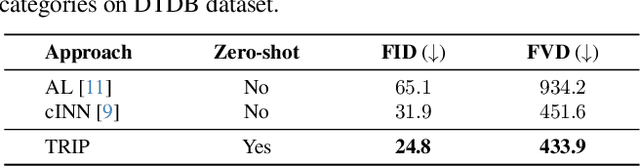
Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static image (i.e., image-to-video generation). The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames. To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through one-step backward diffusion process based on both static image and noised video latent codes. Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame. Furthermore, both reference and residual noise of each frame are dynamically merged via attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation. Please see our project page at https://trip-i2v.github.io/TRIP/.
Learning Spatial Adaptation and Temporal Coherence in Diffusion Models for Video Super-Resolution
Mar 25, 2024
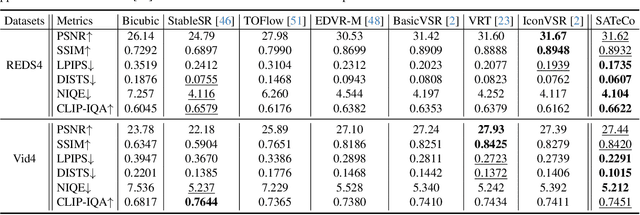
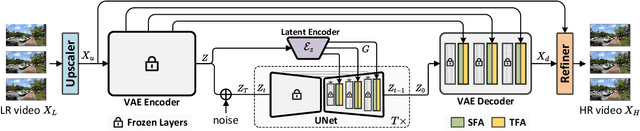
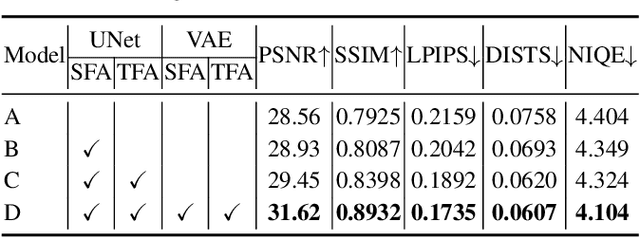
Diffusion models are just at a tipping point for image super-resolution task. Nevertheless, it is not trivial to capitalize on diffusion models for video super-resolution which necessitates not only the preservation of visual appearance from low-resolution to high-resolution videos, but also the temporal consistency across video frames. In this paper, we propose a novel approach, pursuing Spatial Adaptation and Temporal Coherence (SATeCo), for video super-resolution. SATeCo pivots on learning spatial-temporal guidance from low-resolution videos to calibrate both latent-space high-resolution video denoising and pixel-space video reconstruction. Technically, SATeCo freezes all the parameters of the pre-trained UNet and VAE, and only optimizes two deliberately-designed spatial feature adaptation (SFA) and temporal feature alignment (TFA) modules, in the decoder of UNet and VAE. SFA modulates frame features via adaptively estimating affine parameters for each pixel, guaranteeing pixel-wise guidance for high-resolution frame synthesis. TFA delves into feature interaction within a 3D local window (tubelet) through self-attention, and executes cross-attention between tubelet and its low-resolution counterpart to guide temporal feature alignment. Extensive experiments conducted on the REDS4 and Vid4 datasets demonstrate the effectiveness of our approach.
VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM
Jan 02, 2024



The recent innovations and breakthroughs in diffusion models have significantly expanded the possibilities of generating high-quality videos for the given prompts. Most existing works tackle the single-scene scenario with only one video event occurring in a single background. Extending to generate multi-scene videos nevertheless is not trivial and necessitates to nicely manage the logic in between while preserving the consistent visual appearance of key content across video scenes. In this paper, we propose a novel framework, namely VideoDrafter, for content-consistent multi-scene video generation. Technically, VideoDrafter leverages Large Language Models (LLM) to convert the input prompt into comprehensive multi-scene script that benefits from the logical knowledge learnt by LLM. The script for each scene includes a prompt describing the event, the foreground/background entities, as well as camera movement. VideoDrafter identifies the common entities throughout the script and asks LLM to detail each entity. The resultant entity description is then fed into a text-to-image model to generate a reference image for each entity. Finally, VideoDrafter outputs a multi-scene video by generating each scene video via a diffusion process that takes the reference images, the descriptive prompt of the event and camera movement into account. The diffusion model incorporates the reference images as the condition and alignment to strengthen the content consistency of multi-scene videos. Extensive experiments demonstrate that VideoDrafter outperforms the SOTA video generation models in terms of visual quality, content consistency, and user preference.
Selective Volume Mixup for Video Action Recognition
Sep 18, 2023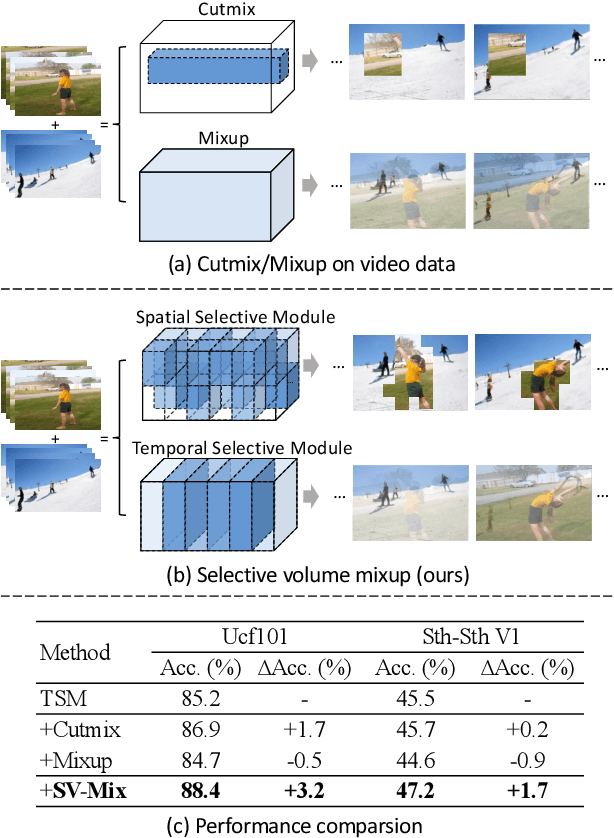
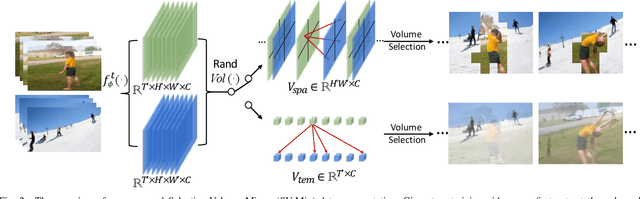
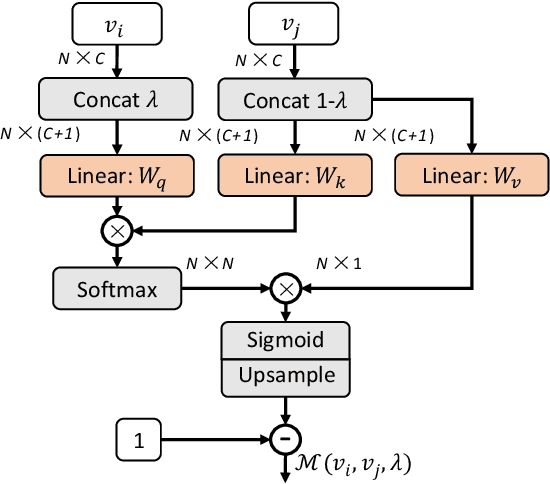
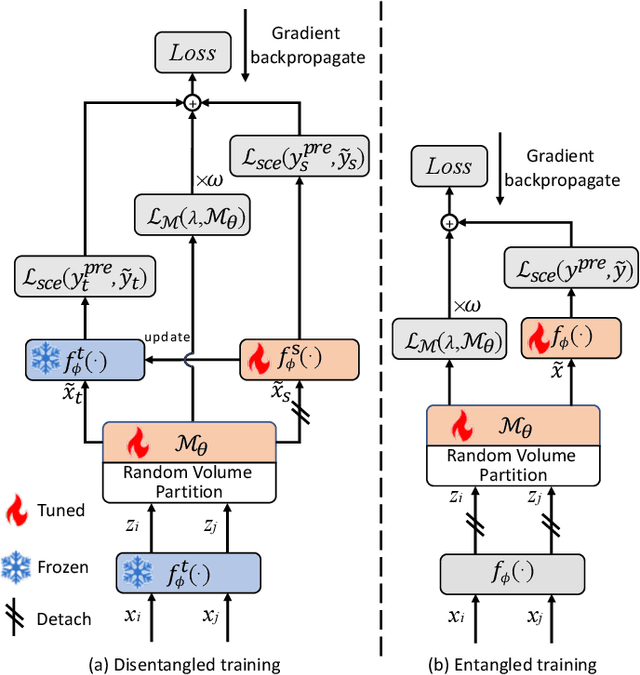
The recent advances in Convolutional Neural Networks (CNNs) and Vision Transformers have convincingly demonstrated high learning capability for video action recognition on large datasets. Nevertheless, deep models often suffer from the overfitting effect on small-scale datasets with a limited number of training videos. A common solution is to exploit the existing image augmentation strategies for each frame individually including Mixup, Cutmix, and RandAugment, which are not particularly optimized for video data. In this paper, we propose a novel video augmentation strategy named Selective Volume Mixup (SV-Mix) to improve the generalization ability of deep models with limited training videos. SV-Mix devises a learnable selective module to choose the most informative volumes from two videos and mixes the volumes up to achieve a new training video. Technically, we propose two new modules, i.e., a spatial selective module to select the local patches for each spatial position, and a temporal selective module to mix the entire frames for each timestamp and maintain the spatial pattern. At each time, we randomly choose one of the two modules to expand the diversity of training samples. The selective modules are jointly optimized with the video action recognition framework to find the optimal augmentation strategy. We empirically demonstrate the merits of the SV-Mix augmentation on a wide range of video action recognition benchmarks and consistently boot the performances of both CNN-based and transformer-based models.
SPE-Net: Boosting Point Cloud Analysis via Rotation Robustness Enhancement
Nov 15, 2022In this paper, we propose a novel deep architecture tailored for 3D point cloud applications, named as SPE-Net. The embedded ``Selective Position Encoding (SPE)'' procedure relies on an attention mechanism that can effectively attend to the underlying rotation condition of the input. Such encoded rotation condition then determines which part of the network parameters to be focused on, and is shown to efficiently help reduce the degree of freedom of the optimization during training. This mechanism henceforth can better leverage the rotation augmentations through reduced training difficulties, making SPE-Net robust against rotated data both during training and testing. The new findings in our paper also urge us to rethink the relationship between the extracted rotation information and the actual test accuracy. Intriguingly, we reveal evidences that by locally encoding the rotation information through SPE-Net, the rotation-invariant features are still of critical importance in benefiting the test samples without any actual global rotation. We empirically demonstrate the merits of the SPE-Net and the associated hypothesis on four benchmarks, showing evident improvements on both rotated and unrotated test data over SOTA methods. Source code is available at https://github.com/ZhaofanQiu/SPE-Net.