 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Synthesis of Cyber-Physical Systems for Real-Time Specifications through Causation-Guided Reinforcement Learning
Oct 09, 2025In real-time and safety-critical cyber-physical systems (CPSs), control synthesis must guarantee that generated policies meet stringent timing and correctness requirements under uncertain and dynamic conditions. Signal temporal logic (STL) has emerged as a powerful formalism of expressing real-time constraints, with its semantics enabling quantitative assessment of system behavior. Meanwhile, reinforcement learning (RL) has become an important method for solving control synthesis problems in unknown environments. Recent studies incorporate STL-based reward functions into RL to automatically synthesize control policies. However, the automatically inferred rewards obtained by these methods represent the global assessment of a whole or partial path but do not accumulate the rewards of local changes accurately, so the sparse global rewards may lead to non-convergence and unstable training performances. In this paper, we propose an online reward generation method guided by the online causation monitoring of STL. Our approach continuously monitors system behavior against an STL specification at each control step, computing the quantitative distance toward satisfaction or violation and thereby producing rewards that reflect instantaneous state dynamics. Additionally, we provide a smooth approximation of the causation semantics to overcome the discontinuity of the causation semantics and make it differentiable for using deep-RL methods. We have implemented a prototype tool and evaluated it in the Gym environment on a variety of continuously controlled benchmarks. Experimental results show that our proposed STL-guided RL method with online causation semantics outperforms existing relevant STL-guided RL methods, providing a more robust and efficient reward generation framework for deep-RL.
Enhancing Transformation from Natural Language to Signal Temporal Logic Using LLMs with Diverse External Knowledge
May 27, 2025Temporal Logic (TL), especially Signal Temporal Logic (STL), enables precise formal specification, making it widely used in cyber-physical systems such as autonomous driving and robotics. Automatically transforming NL into STL is an attractive approach to overcome the limitations of manual transformation, which is time-consuming and error-prone. However, due to the lack of datasets, automatic transformation currently faces significant challenges and has not been fully explored. In this paper, we propose an NL-STL dataset named STL-Diversity-Enhanced (STL-DivEn), which comprises 16,000 samples enriched with diverse patterns. To develop the dataset, we first manually create a small-scale seed set of NL-STL pairs. Next, representative examples are identified through clustering and used to guide large language models (LLMs) in generating additional NL-STL pairs. Finally, diversity and accuracy are ensured through rigorous rule-based filters and human validation. Furthermore, we introduce the Knowledge-Guided STL Transformation (KGST) framework, a novel approach for transforming natural language into STL, involving a generate-then-refine process based on external knowledge. Statistical analysis shows that the STL-DivEn dataset exhibits more diversity than the existing NL-STL dataset. Moreover, both metric-based and human evaluations indicate that our KGST approach outperforms baseline models in transformation accuracy on STL-DivEn and DeepSTL datasets.
Ouroboros-Diffusion: Exploring Consistent Content Generation in Tuning-free Long Video Diffusion
Jan 15, 2025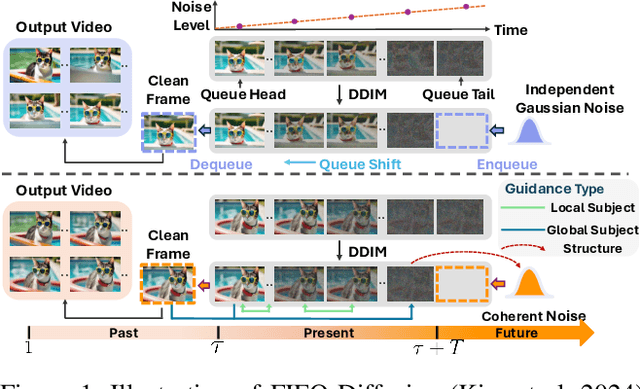

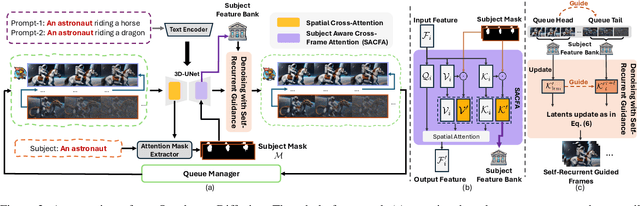

The first-in-first-out (FIFO) video diffusion, built on a pre-trained text-to-video model, has recently emerged as an effective approach for tuning-free long video generation. This technique maintains a queue of video frames with progressively increasing noise, continuously producing clean frames at the queue's head while Gaussian noise is enqueued at the tail. However, FIFO-Diffusion often struggles to keep long-range temporal consistency in the generated videos due to the lack of correspondence modeling across frames. In this paper, we propose Ouroboros-Diffusion, a novel video denoising framework designed to enhance structural and content (subject) consistency, enabling the generation of consistent videos of arbitrary length. Specifically, we introduce a new latent sampling technique at the queue tail to improve structural consistency, ensuring perceptually smooth transitions among frames. To enhance subject consistency, we devise a Subject-Aware Cross-Frame Attention (SACFA) mechanism, which aligns subjects across frames within short segments to achieve better visual coherence. Furthermore, we introduce self-recurrent guidance. This technique leverages information from all previous cleaner frames at the front of the queue to guide the denoising of noisier frames at the end, fostering rich and contextual global information interaction. Extensive experiments of long video generation on the VBench benchmark demonstrate the superiority of our Ouroboros-Diffusion, particularly in terms of subject consistency, motion smoothness, and temporal consistency.
Latent-Reframe: Enabling Camera Control for Video Diffusion Model without Training
Dec 08, 2024



Precise camera pose control is crucial for video generation with diffusion models. Existing methods require fine-tuning with additional datasets containing paired videos and camera pose annotations, which are both data-intensive and computationally costly, and can disrupt the pre-trained model distribution. We introduce Latent-Reframe, which enables camera control in a pre-trained video diffusion model without fine-tuning. Unlike existing methods, Latent-Reframe operates during the sampling stage, maintaining efficiency while preserving the original model distribution. Our approach reframes the latent code of video frames to align with the input camera trajectory through time-aware point clouds. Latent code inpainting and harmonization then refine the model latent space, ensuring high-quality video generation. Experimental results demonstrate that Latent-Reframe achieves comparable or superior camera control precision and video quality to training-based methods, without the need for fine-tuning on additional datasets.
On Inductive Biases That Enable Generalization of Diffusion Transformers
Oct 28, 2024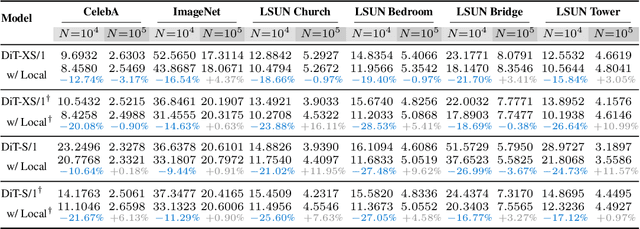
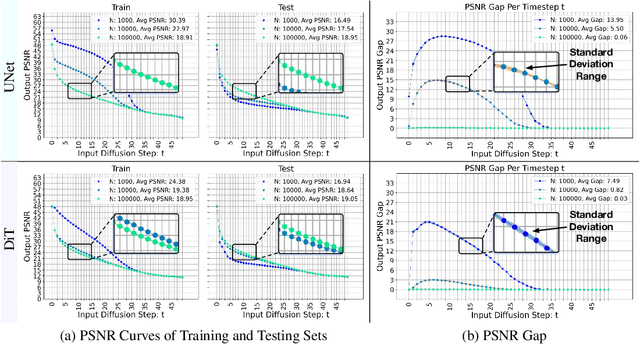
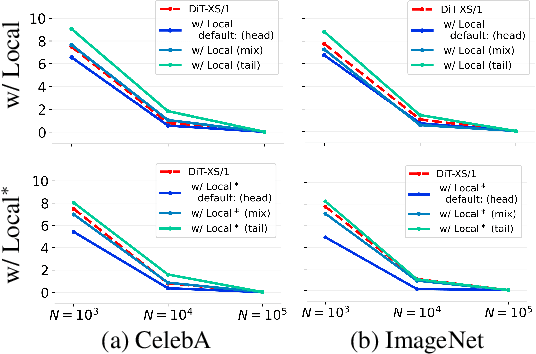
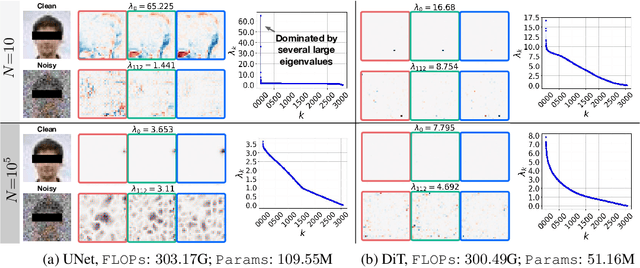
Recent work studying the generalization of diffusion models with UNet-based denoisers reveals inductive biases that can be expressed via geometry-adaptive harmonic bases. However, in practice, more recent denoising networks are often based on transformers, e.g., the diffusion transformer (DiT). This raises the question: do transformer-based denoising networks exhibit inductive biases that can also be expressed via geometry-adaptive harmonic bases? To our surprise, we find that this is not the case. This discrepancy motivates our search for the inductive bias that can lead to good generalization in DiT models. Investigating the pivotal attention modules of a DiT, we find that locality of attention maps are closely associated with generalization. To verify this finding, we modify the generalization of a DiT by restricting its attention windows. We inject local attention windows to a DiT and observe an improvement in generalization. Furthermore, we empirically find that both the placement and the effective attention size of these local attention windows are crucial factors. Experimental results on the CelebA, ImageNet, and LSUN datasets show that strengthening the inductive bias of a DiT can improve both generalization and generation quality when less training data is available. Source code will be released publicly upon paper publication. Project page: dit-generalization.github.io/.
Bring Metric Functions into Diffusion Models
Jan 04, 2024



We introduce a Cascaded Diffusion Model (Cas-DM) that improves a Denoising Diffusion Probabilistic Model (DDPM) by effectively incorporating additional metric functions in training. Metric functions such as the LPIPS loss have been proven highly effective in consistency models derived from the score matching. However, for the diffusion counterparts, the methodology and efficacy of adding extra metric functions remain unclear. One major challenge is the mismatch between the noise predicted by a DDPM at each step and the desired clean image that the metric function works well on. To address this problem, we propose Cas-DM, a network architecture that cascades two network modules to effectively apply metric functions to the diffusion model training. The first module, similar to a standard DDPM, learns to predict the added noise and is unaffected by the metric function. The second cascaded module learns to predict the clean image, thereby facilitating the metric function computation. Experiment results show that the proposed diffusion model backbone enables the effective use of the LPIPS loss, leading to state-of-the-art image quality (FID, sFID, IS) on various established benchmarks.
Video Understanding with Large Language Models: A Survey
Jan 04, 2024


With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of Large Language Models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of the recent advancements in video understanding harnessing the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended spatial-temporal reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into four main types: LLM-based Video Agents, Vid-LLMs Pretraining, Vid-LLMs Instruction Tuning, and Hybrid Methods. Furthermore, this survey presents a comprehensive study of the tasks, datasets, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
OpenLEAF: Open-Domain Interleaved Image-Text Generation and Evaluation
Oct 11, 2023

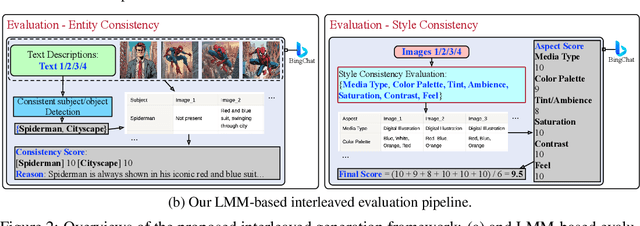

This work investigates a challenging task named open-domain interleaved image-text generation, which generates interleaved texts and images following an input query. We propose a new interleaved generation framework based on prompting large-language models (LLMs) and pre-trained text-to-image (T2I) models, namely OpenLEAF. In OpenLEAF, the LLM generates textual descriptions, coordinates T2I models, creates visual prompts for generating images, and incorporates global contexts into the T2I models. This global context improves the entity and style consistencies of images in the interleaved generation. For model assessment, we first propose to use large multi-modal models (LMMs) to evaluate the entity and style consistencies of open-domain interleaved image-text sequences. According to the LMM evaluation on our constructed evaluation set, the proposed interleaved generation framework can generate high-quality image-text content for various domains and applications, such as how-to question answering, storytelling, graphical story rewriting, and webpage/poster generation tasks. Moreover, we validate the effectiveness of the proposed LMM evaluation technique with human assessment. We hope our proposed framework, benchmark, and LMM evaluation could help establish the intriguing interleaved image-text generation task.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Aug 14, 2023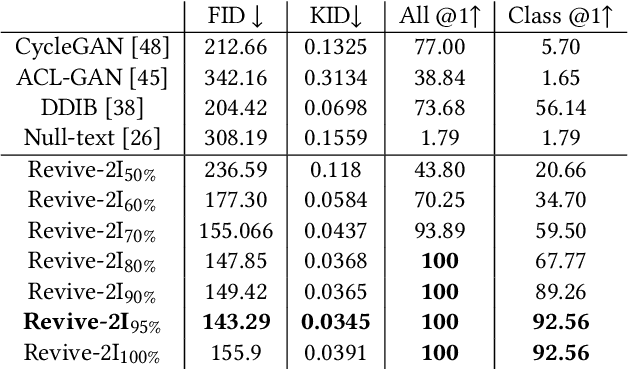
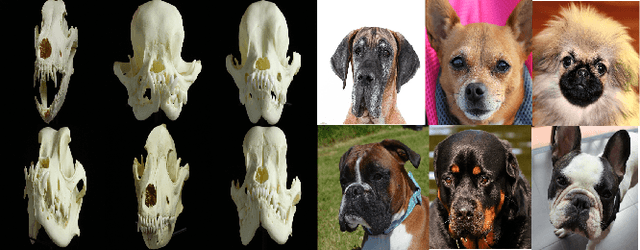
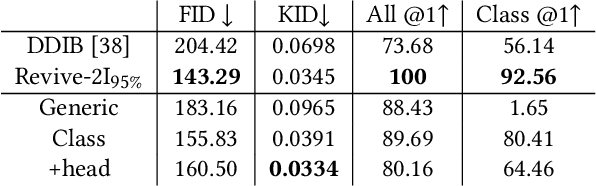
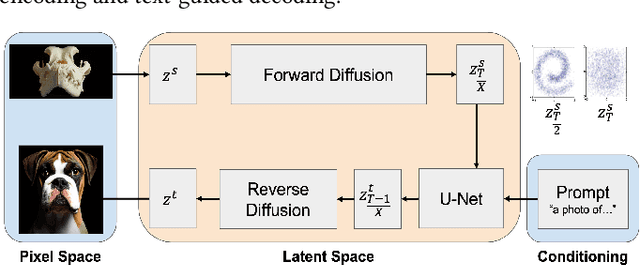
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
Domain-Scalable Unpaired Image Translation via Latent Space Anchoring
Jun 26, 2023



Unpaired image-to-image translation (UNIT) aims to map images between two visual domains without paired training data. However, given a UNIT model trained on certain domains, it is difficult for current methods to incorporate new domains because they often need to train the full model on both existing and new domains. To address this problem, we propose a new domain-scalable UNIT method, termed as latent space anchoring, which can be efficiently extended to new visual domains and does not need to fine-tune encoders and decoders of existing domains. Our method anchors images of different domains to the same latent space of frozen GANs by learning lightweight encoder and regressor models to reconstruct single-domain images. In the inference phase, the learned encoders and decoders of different domains can be arbitrarily combined to translate images between any two domains without fine-tuning. Experiments on various datasets show that the proposed method achieves superior performance on both standard and domain-scalable UNIT tasks in comparison with the state-of-the-art methods.