 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Understanding with Large Language Models: A Survey
Jan 04, 2024


With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of Large Language Models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of the recent advancements in video understanding harnessing the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended spatial-temporal reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into four main types: LLM-based Video Agents, Vid-LLMs Pretraining, Vid-LLMs Instruction Tuning, and Hybrid Methods. Furthermore, this survey presents a comprehensive study of the tasks, datasets, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
LaunchpadGPT: Language Model as Music Visualization Designer on Launchpad
Jul 23, 2023Launchpad is a musical instrument that allows users to create and perform music by pressing illuminated buttons. To assist and inspire the design of the Launchpad light effect, and provide a more accessible approach for beginners to create music visualization with this instrument, we proposed the LaunchpadGPT model to generate music visualization designs on Launchpad automatically. Based on the language model with excellent generation ability, our proposed LaunchpadGPT takes an audio piece of music as input and outputs the lighting effects of Launchpad-playing in the form of a video (Launchpad-playing video). We collect Launchpad-playing videos and process them to obtain music and corresponding video frame of Launchpad-playing as prompt-completion pairs, to train the language model. The experiment result shows the proposed method can create better music visualization than random generation methods and hold the potential for a broader range of music visualization applications. Our code is available at https://github.com/yunlong10/LaunchpadGPT/.
Multi-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward
Sep 25, 2022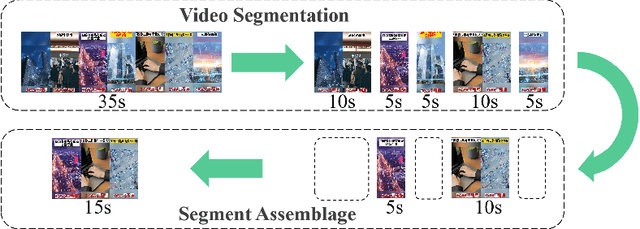

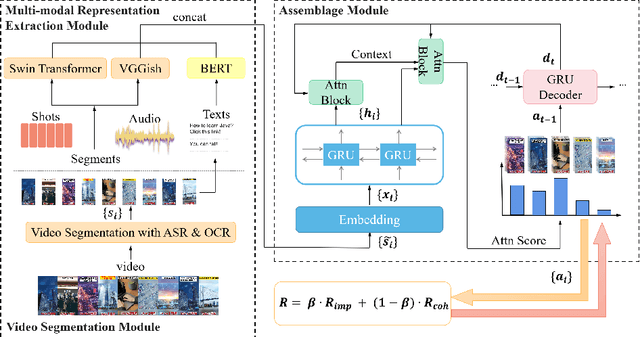

Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k