 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward
Paper and Code
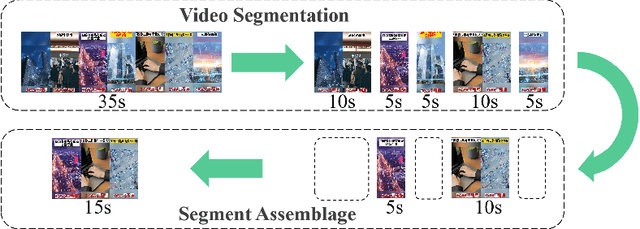

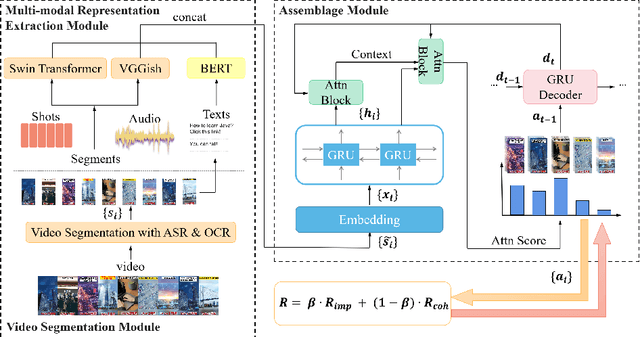

Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k