 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Transformation from Natural Language to Signal Temporal Logic Using LLMs with Diverse External Knowledge
May 27, 2025Temporal Logic (TL), especially Signal Temporal Logic (STL), enables precise formal specification, making it widely used in cyber-physical systems such as autonomous driving and robotics. Automatically transforming NL into STL is an attractive approach to overcome the limitations of manual transformation, which is time-consuming and error-prone. However, due to the lack of datasets, automatic transformation currently faces significant challenges and has not been fully explored. In this paper, we propose an NL-STL dataset named STL-Diversity-Enhanced (STL-DivEn), which comprises 16,000 samples enriched with diverse patterns. To develop the dataset, we first manually create a small-scale seed set of NL-STL pairs. Next, representative examples are identified through clustering and used to guide large language models (LLMs) in generating additional NL-STL pairs. Finally, diversity and accuracy are ensured through rigorous rule-based filters and human validation. Furthermore, we introduce the Knowledge-Guided STL Transformation (KGST) framework, a novel approach for transforming natural language into STL, involving a generate-then-refine process based on external knowledge. Statistical analysis shows that the STL-DivEn dataset exhibits more diversity than the existing NL-STL dataset. Moreover, both metric-based and human evaluations indicate that our KGST approach outperforms baseline models in transformation accuracy on STL-DivEn and DeepSTL datasets.
CLAS: A Machine Learning Enhanced Framework for Exploring Large 3D Design Datasets
Dec 04, 2024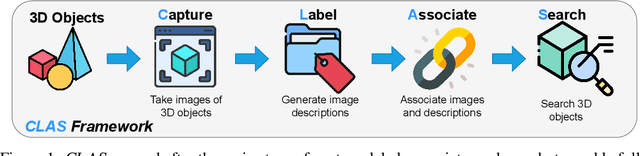
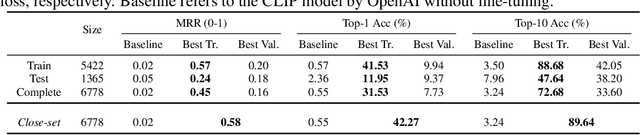
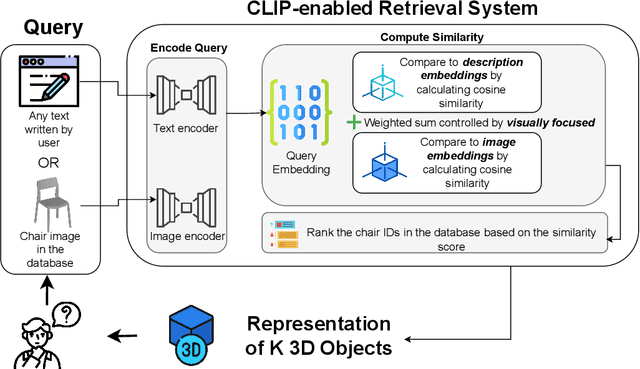
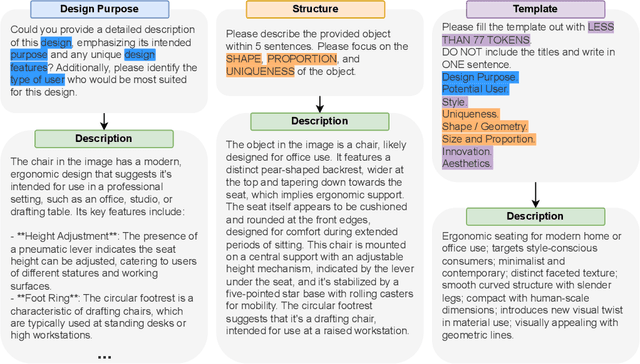
Three-dimensional (3D) objects have wide applications. Despite the growing interest in 3D modeling in academia and industries, designing and/or creating 3D objects from scratch remains time-consuming and challenging. With the development of generative artificial intelligence (AI), designers discover a new way to create images for ideation. However, generative AIs are less useful in creating 3D objects with satisfying qualities. To allow 3D designers to access a wide range of 3D objects for creative activities based on their specific demands, we propose a machine learning (ML) enhanced framework CLAS - named after the four-step of capture, label, associate, and search - to enable fully automatic retrieval of 3D objects based on user specifications leveraging the existing datasets of 3D objects. CLAS provides an effective and efficient method for any person or organization to benefit from their existing but not utilized 3D datasets. In addition, CLAS may also be used to produce high-quality 3D object synthesis datasets for training and evaluating 3D generative models. As a proof of concept, we created and showcased a search system with a web user interface (UI) for retrieving 6,778 3D objects of chairs in the ShapeNet dataset powered by CLAS. In a close-set retrieval setting, our retrieval method achieves a mean reciprocal rank (MRR) of 0.58, top 1 accuracy of 42.27%, and top 10 accuracy of 89.64%.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024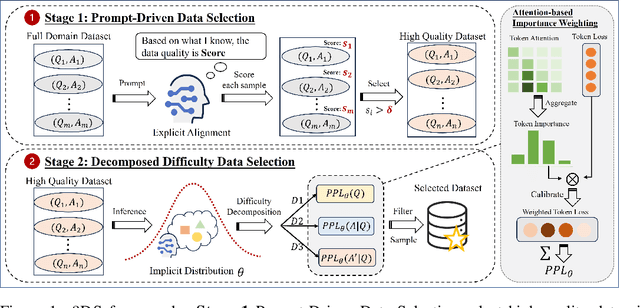
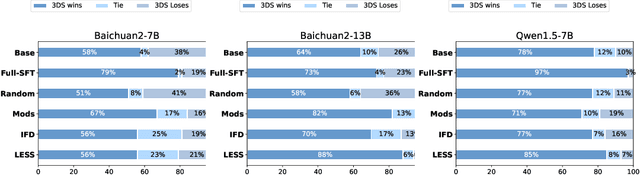
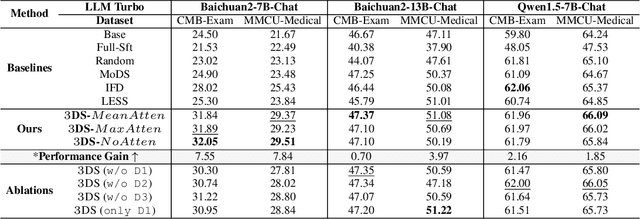
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
TC-RAG:Turing-Complete RAG's Case study on Medical LLM Systems
Aug 17, 2024



In the pursuit of enhancing domain-specific Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) emerges as a promising solution to mitigate issues such as hallucinations, outdated knowledge, and limited expertise in highly specialized queries. However, existing approaches to RAG fall short by neglecting system state variables, which are crucial for ensuring adaptive control, retrieval halting, and system convergence. In this paper, we introduce the TC-RAG through rigorous proof, a novel framework that addresses these challenges by incorporating a Turing Complete System to manage state variables, thereby enabling more efficient and accurate knowledge retrieval. By leveraging a memory stack system with adaptive retrieval, reasoning, and planning capabilities, TC-RAG not only ensures the controlled halting of retrieval processes but also mitigates the accumulation of erroneous knowledge via Push and Pop actions. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of TC-RAG over existing methods in accuracy by over 7.20\%. Our dataset and code have been available at https://https://github.com/Artessay/SAMA.git.
A Comprehensive Evaluation on Event Reasoning of Large Language Models
Apr 26, 2024



Event reasoning is a fundamental ability that underlies many applications. It requires event schema knowledge to perform global reasoning and needs to deal with the diversity of the inter-event relations and the reasoning paradigms. How well LLMs accomplish event reasoning on various relations and reasoning paradigms remains unknown. To mitigate this disparity, we comprehensively evaluate the abilities of event reasoning of LLMs. We introduce a novel benchmark EV2 for EValuation of EVent reasoning. EV2 consists of two levels of evaluation of schema and instance and is comprehensive in relations and reasoning paradigms. We conduct extensive experiments on EV2. We find that LLMs have abilities to accomplish event reasoning but their performances are far from satisfactory. We also notice the imbalance of event reasoning abilities in LLMs. Besides, LLMs have event schema knowledge, however, they're not aligned with humans on how to utilize the knowledge. Based on these findings, we introduce two methods to guide the LLMs to utilize the event schema knowledge. Both methods achieve improvements.
Think and Retrieval: A Hypothesis Knowledge Graph Enhanced Medical Large Language Models
Dec 26, 2023We explore how the rise of Large Language Models (LLMs) significantly impacts task performance in the field of Natural Language Processing. We focus on two strategies, Retrieval-Augmented Generation (RAG) and Fine-Tuning (FT), and propose the Hypothesis Knowledge Graph Enhanced (HyKGE) framework, leveraging a knowledge graph to enhance medical LLMs. By integrating LLMs and knowledge graphs, HyKGE demonstrates superior performance in addressing accuracy and interpretability challenges, presenting potential applications in the medical domain. Our evaluations using real-world datasets highlight HyKGE's superiority in providing accurate knowledge with precise confidence, particularly in complex and difficult scenarios. The code will be available until published.
Spatially and Robustly Hybrid Mixture Regression Model for Inference of Spatial Dependence
Sep 28, 2021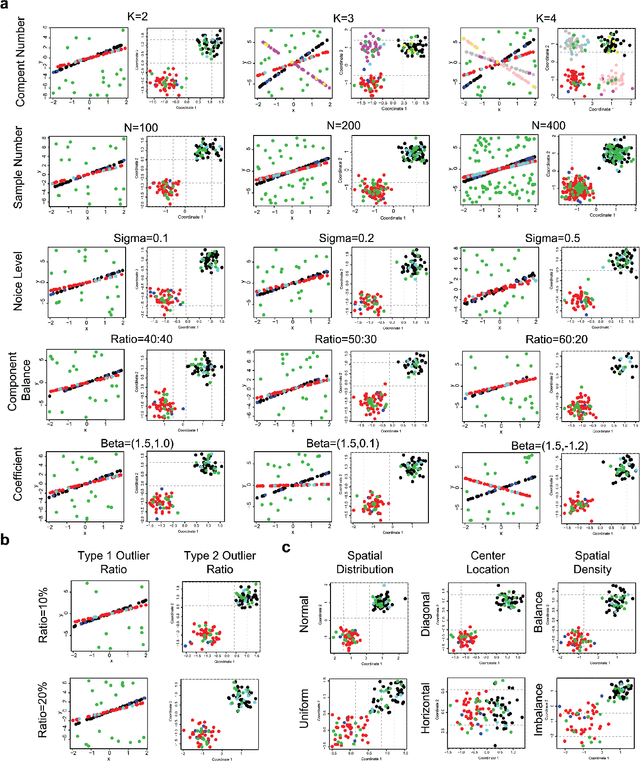
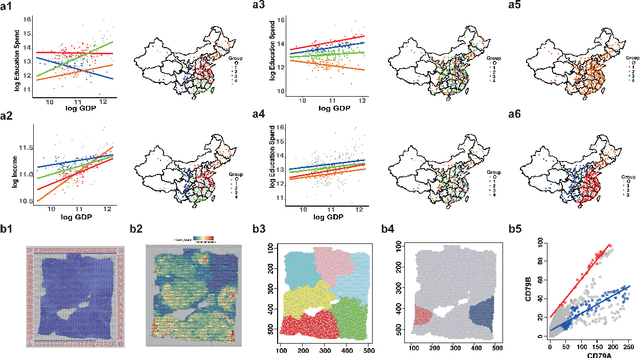
In this paper, we propose a Spatial Robust Mixture Regression model to investigate the relationship between a response variable and a set of explanatory variables over the spatial domain, assuming that the relationships may exhibit complex spatially dynamic patterns that cannot be captured by constant regression coefficients. Our method integrates the robust finite mixture Gaussian regression model with spatial constraints, to simultaneously handle the spatial nonstationarity, local homogeneity, and outlier contaminations. Compared with existing spatial regression models, our proposed model assumes the existence a few distinct regression models that are estimated based on observations that exhibit similar response-predictor relationships. As such, the proposed model not only accounts for nonstationarity in the spatial trend, but also clusters observations into a few distinct and homogenous groups. This provides an advantage on interpretation with a few stationary sub-processes identified that capture the predominant relationships between response and predictor variables. Moreover, the proposed method incorporates robust procedures to handle contaminations from both regression outliers and spatial outliers. By doing so, we robustly segment the spatial domain into distinct local regions with similar regression coefficients, and sporadic locations that are purely outliers. Rigorous statistical hypothesis testing procedure has been designed to test the significance of such segmentation. Experimental results on many synthetic and real-world datasets demonstrate the robustness, accuracy, and effectiveness of our proposed method, compared with other robust finite mixture regression, spatial regression and spatial segmentation methods.