 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Conditioned Patch Parallelism for Accelerated Diffusion Model Inference
Dec 04, 2024Diffusion models have exhibited exciting capabilities in generating images and are also very promising for video creation. However, the inference speed of diffusion models is limited by the slow sampling process, restricting its use cases. The sequential denoising steps required for generating a single sample could take tens or hundreds of iterations and thus have become a significant bottleneck. This limitation is more salient for applications that are interactive in nature or require small latency. To address this challenge, we propose Partially Conditioned Patch Parallelism (PCPP) to accelerate the inference of high-resolution diffusion models. Using the fact that the difference between the images in adjacent diffusion steps is nearly zero, Patch Parallelism (PP) leverages multiple GPUs communicating asynchronously to compute patches of an image in multiple computing devices based on the entire image (all patches) in the previous diffusion step. PCPP develops PP to reduce computation in inference by conditioning only on parts of the neighboring patches in each diffusion step, which also decreases communication among computing devices. As a result, PCPP decreases the communication cost by around $70\%$ compared to DistriFusion (the state of the art implementation of PP) and achieves $2.36\sim 8.02\times$ inference speed-up using $4\sim 8$ GPUs compared to $2.32\sim 6.71\times$ achieved by DistriFusion depending on the computing device configuration and resolution of generation at the cost of a possible decrease in image quality. PCPP demonstrates the potential to strike a favorable trade-off, enabling high-quality image generation with substantially reduced latency.
CLAS: A Machine Learning Enhanced Framework for Exploring Large 3D Design Datasets
Dec 04, 2024
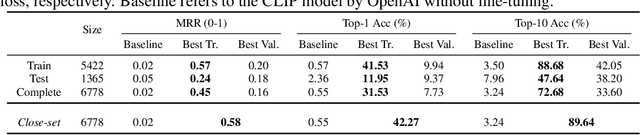
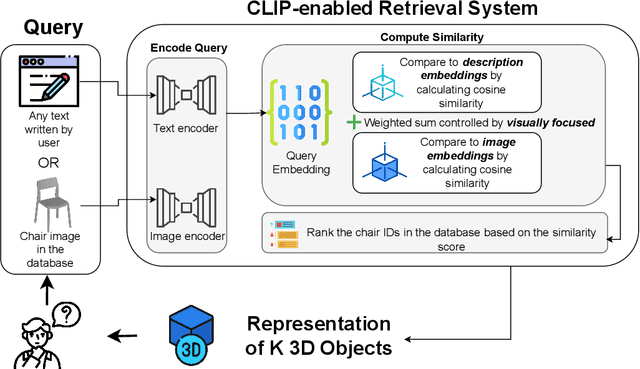
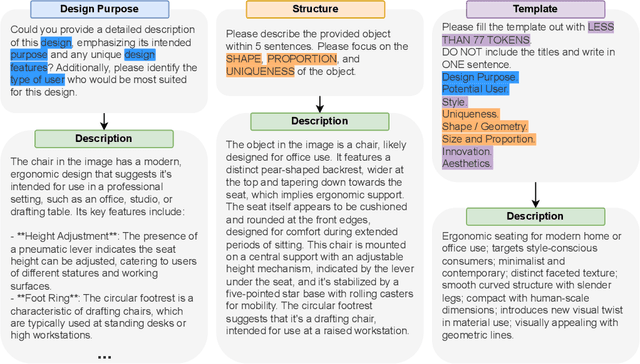
Three-dimensional (3D) objects have wide applications. Despite the growing interest in 3D modeling in academia and industries, designing and/or creating 3D objects from scratch remains time-consuming and challenging. With the development of generative artificial intelligence (AI), designers discover a new way to create images for ideation. However, generative AIs are less useful in creating 3D objects with satisfying qualities. To allow 3D designers to access a wide range of 3D objects for creative activities based on their specific demands, we propose a machine learning (ML) enhanced framework CLAS - named after the four-step of capture, label, associate, and search - to enable fully automatic retrieval of 3D objects based on user specifications leveraging the existing datasets of 3D objects. CLAS provides an effective and efficient method for any person or organization to benefit from their existing but not utilized 3D datasets. In addition, CLAS may also be used to produce high-quality 3D object synthesis datasets for training and evaluating 3D generative models. As a proof of concept, we created and showcased a search system with a web user interface (UI) for retrieving 6,778 3D objects of chairs in the ShapeNet dataset powered by CLAS. In a close-set retrieval setting, our retrieval method achieves a mean reciprocal rank (MRR) of 0.58, top 1 accuracy of 42.27%, and top 10 accuracy of 89.64%.
Advancing Conversational Psychotherapy: Integrating Privacy, Dual-Memory, and Domain Expertise with Large Language Models
Dec 04, 2024Mental health has increasingly become a global issue that reveals the limitations of traditional conversational psychotherapy, constrained by location, time, expense, and privacy concerns. In response to these challenges, we introduce SoulSpeak, a Large Language Model (LLM)-enabled chatbot designed to democratize access to psychotherapy. SoulSpeak improves upon the capabilities of standard LLM-enabled chatbots by incorporating a novel dual-memory component that combines short-term and long-term context via Retrieval Augmented Generation (RAG) to offer personalized responses while ensuring the preservation of user privacy and intimacy through a dedicated privacy module. In addition, it leverages a counseling chat dataset of therapist-client interactions and various prompting techniques to align the generated responses with psychotherapeutic methods. We introduce two fine-tuned BERT models to evaluate the system against existing LLMs and human therapists: the Conversational Psychotherapy Preference Model (CPPM) to simulate human preference among responses and another to assess response relevance to user input. CPPM is useful for training and evaluating psychotherapy-focused language models independent from SoulSpeak, helping with the constrained resources available for psychotherapy. Furthermore, the effectiveness of the dual-memory component and the robustness of the privacy module are also examined. Our findings highlight the potential and challenge of enhancing mental health care by offering an alternative that combines the expertise of traditional therapy with the advantages of LLMs, providing a promising way to address the accessibility and personalization gap in current mental health services.