 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
Bridging Global Intent with Local Details: A Hierarchical Representation Approach for Semantic Validation in Text-to-SQL
Dec 28, 2025Text-to-SQL translates natural language questions into SQL statements grounded in a target database schema. Ensuring the reliability and executability of such systems requires validating generated SQL, but most existing approaches focus only on syntactic correctness, with few addressing semantic validation (detecting misalignments between questions and SQL). As a consequence, effective semantic validation still faces two key challenges: capturing both global user intent and SQL structural details, and constructing high-quality fine-grained sub-SQL annotations. To tackle these, we introduce HEROSQL, a hierarchical SQL representation approach that integrates global intent (via Logical Plans, LPs) and local details (via Abstract Syntax Trees, ASTs). To enable better information propagation, we employ a Nested Message Passing Neural Network (NMPNN) to capture inherent relational information in SQL and aggregate schema-guided semantics across LPs and ASTs. Additionally, to generate high-quality negative samples, we propose an AST-driven sub-SQL augmentation strategy, supporting robust optimization of fine-grained semantic inconsistencies. Extensive experiments conducted on Text-to-SQL validation benchmarks (both in-domain and out-of-domain settings) demonstrate that our approach outperforms existing state-of-the-art methods, achieving an average 9.40% improvement of AUPRC and 12.35% of AUROC in identifying semantic inconsistencies. It excels at detecting fine-grained semantic errors, provides large language models with more granular feedback, and ultimately enhances the reliability and interpretability of data querying platforms.
EL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
Enhanced Cooperative Perception Through Asynchronous Vehicle to Infrastructure Framework with Delay Mitigation for Connected and Automated Vehicles
Apr 10, 2025Perception is a key component of Automated vehicles (AVs). However, sensors mounted to the AVs often encounter blind spots due to obstructions from other vehicles, infrastructure, or objects in the surrounding area. While recent advancements in planning and control algorithms help AVs react to sudden object appearances from blind spots at low speeds and less complex scenarios, challenges remain at high speeds and complex intersections. Vehicle to Infrastructure (V2I) technology promises to enhance scene representation for AVs in complex intersections, providing sufficient time and distance to react to adversary vehicles violating traffic rules. Most existing methods for infrastructure-based vehicle detection and tracking rely on LIDAR, RADAR or sensor fusion methods, such as LIDAR-Camera and RADAR-Camera. Although LIDAR and RADAR provide accurate spatial information, the sparsity of point cloud data limits its ability to capture detailed object contours of objects far away, resulting in inaccurate 3D object detection results. Furthermore, the absence of LIDAR or RADAR at every intersection increases the cost of implementing V2I technology. To address these challenges, this paper proposes a V2I framework that utilizes monocular traffic cameras at road intersections to detect 3D objects. The results from the roadside unit (RSU) are then combined with the on-board system using an asynchronous late fusion method to enhance scene representation. Additionally, the proposed framework provides a time delay compensation module to compensate for the processing and transmission delay from the RSU. Lastly, the V2I framework is tested by simulating and validating a scenario similar to the one described in an industry report by Waymo. The results show that the proposed method improves the scene representation and the AV's perception range, giving enough time and space to react to adversary vehicles.
LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
Apr 03, 2025Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
Jan 24, 2025We introduce DRESS, a novel approach for generating stylized large language model (LLM) responses through representation editing. Existing methods like prompting and fine-tuning are either insufficient for complex style adaptation or computationally expensive, particularly in tasks like NPC creation or character role-playing. Our approach leverages the over-parameterized nature of LLMs to disentangle a style-relevant subspace within the model's representation space to conduct representation editing, ensuring a minimal impact on the original semantics. By applying adaptive editing strengths, we dynamically adjust the steering vectors in the style subspace to maintain both stylistic fidelity and semantic integrity. We develop two stylized QA benchmark datasets to validate the effectiveness of DRESS, and the results demonstrate significant improvements compared to baseline methods such as prompting and ITI. In short, DRESS is a lightweight, train-free solution for enhancing LLMs with flexible and effective style control, making it particularly useful for developing stylized conversational agents. Codes and benchmark datasets are available at https://github.com/ArthurLeoM/DRESS-LLM.
RAGraph: A General Retrieval-Augmented Graph Learning Framework
Oct 31, 2024



Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024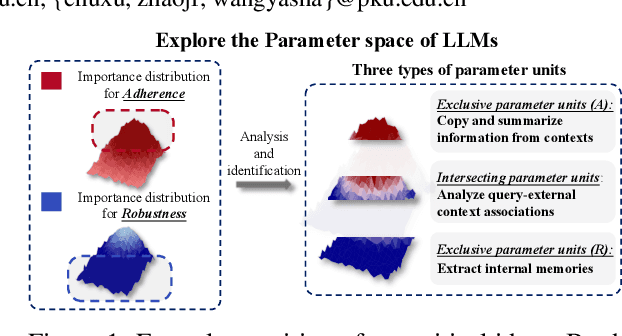
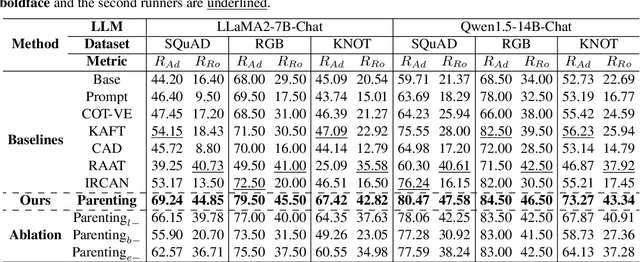
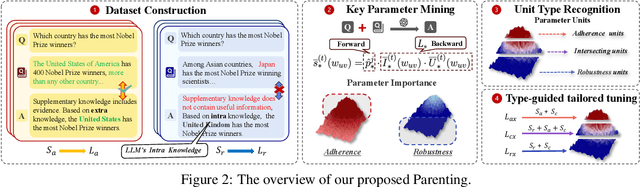
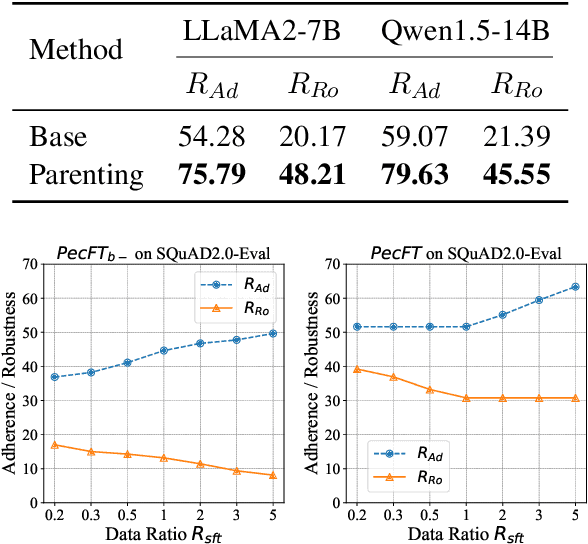
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024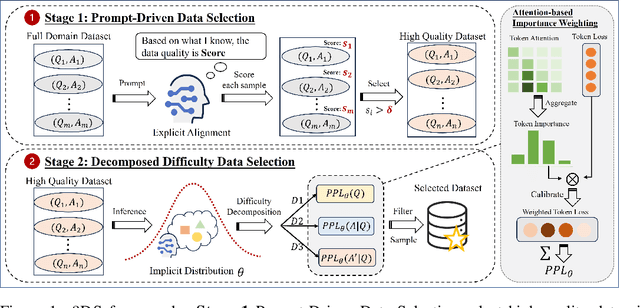
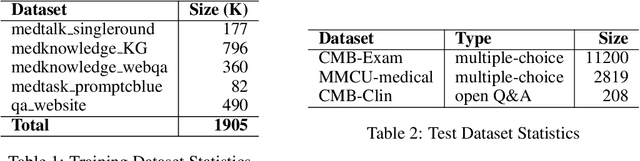
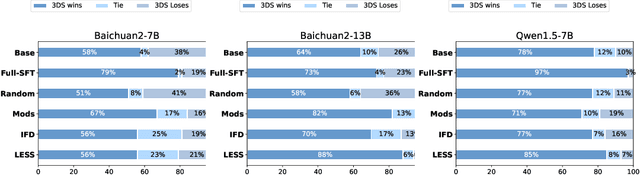
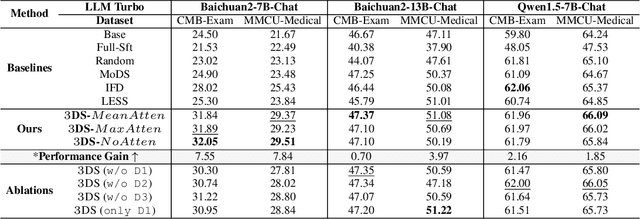
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
IntelliCare: Improving Healthcare Analysis with Variance-Controlled Patient-Level Knowledge from Large Language Models
Aug 23, 2024While pioneering deep learning methods have made great strides in analyzing electronic health record (EHR) data, they often struggle to fully capture the semantics of diverse medical codes from limited data. The integration of external knowledge from Large Language Models (LLMs) presents a promising avenue for improving healthcare predictions. However, LLM analyses may exhibit significant variance due to ambiguity problems and inconsistency issues, hindering their effective utilization. To address these challenges, we propose IntelliCare, a novel framework that leverages LLMs to provide high-quality patient-level external knowledge and enhance existing EHR models. Concretely, IntelliCare identifies patient cohorts and employs task-relevant statistical information to augment LLM understanding and generation, effectively mitigating the ambiguity problem. Additionally, it refines LLM-derived knowledge through a hybrid approach, generating multiple analyses and calibrating them using both the EHR model and perplexity measures. Experimental evaluations on three clinical prediction tasks across two large-scale EHR datasets demonstrate that IntelliCare delivers significant performance improvements to existing methods, highlighting its potential in advancing personalized healthcare predictions and decision support systems.