 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Representation Alignment: Bridging 2D and 3D Vision via Geometry-Aware Architecture Search
Mar 20, 2026Modern computer vision requires balancing predictive accuracy with real-time efficiency, yet the high inference cost of large vision models (LVMs) limits deployment on resource-constrained edge devices. Although Evolutionary Neural Architecture Search (ENAS) is well suited for multi-objective optimization, its practical use is hindered by two issues: expensive candidate evaluation and ranking inconsistency among subnetworks. To address them, we propose EvoNAS, an efficient distributed framework for multi-objective evolutionary architecture search. We build a hybrid supernet that integrates Vision State Space and Vision Transformer (VSS-ViT) modules, and optimize it with a Cross-Architecture Dual-Domain Knowledge Distillation (CA-DDKD) strategy. By coupling the computational efficiency of VSS blocks with the semantic expressiveness of ViT modules, CA-DDKD improves the representational capacity of the shared supernet and enhances ranking consistency, enabling reliable fitness estimation during evolution without extra fine-tuning. To reduce the cost of large-scale validation, we further introduce a Distributed Multi-Model Parallel Evaluation (DMMPE) framework based on GPU resource pooling and asynchronous scheduling. Compared with conventional data-parallel evaluation, DMMPE improves efficiency by over 70% through concurrent multi-GPU, multi-model execution. Experiments on COCO, ADE20K, KITTI, and NYU-Depth v2 show that the searched architectures, termed EvoNets, consistently achieve Pareto-optimal trade-offs between accuracy and efficiency. Compared with representative CNN-, ViT-, and Mamba-based models, EvoNets deliver lower inference latency and higher throughput under strict computational budgets while maintaining strong generalization on downstream tasks such as novel view synthesis. Code is available at https://github.com/EMI-Group/evonas
IntelliCare: Improving Healthcare Analysis with Variance-Controlled Patient-Level Knowledge from Large Language Models
Aug 23, 2024While pioneering deep learning methods have made great strides in analyzing electronic health record (EHR) data, they often struggle to fully capture the semantics of diverse medical codes from limited data. The integration of external knowledge from Large Language Models (LLMs) presents a promising avenue for improving healthcare predictions. However, LLM analyses may exhibit significant variance due to ambiguity problems and inconsistency issues, hindering their effective utilization. To address these challenges, we propose IntelliCare, a novel framework that leverages LLMs to provide high-quality patient-level external knowledge and enhance existing EHR models. Concretely, IntelliCare identifies patient cohorts and employs task-relevant statistical information to augment LLM understanding and generation, effectively mitigating the ambiguity problem. Additionally, it refines LLM-derived knowledge through a hybrid approach, generating multiple analyses and calibrating them using both the EHR model and perplexity measures. Experimental evaluations on three clinical prediction tasks across two large-scale EHR datasets demonstrate that IntelliCare delivers significant performance improvements to existing methods, highlighting its potential in advancing personalized healthcare predictions and decision support systems.
SMART: Towards Pre-trained Missing-Aware Model for Patient Health Status Prediction
May 15, 2024



Electronic health record (EHR) data has emerged as a valuable resource for analyzing patient health status. However, the prevalence of missing data in EHR poses significant challenges to existing methods, leading to spurious correlations and suboptimal predictions. While various imputation techniques have been developed to address this issue, they often obsess unnecessary details and may introduce additional noise when making clinical predictions. To tackle this problem, we propose SMART, a Self-Supervised Missing-Aware RepresenTation Learning approach for patient health status prediction, which encodes missing information via elaborated attentions and learns to impute missing values through a novel self-supervised pre-training approach that reconstructs missing data representations in the latent space. By adopting missing-aware attentions and focusing on learning higher-order representations, SMART promotes better generalization and robustness to missing data. We validate the effectiveness of SMART through extensive experiments on six EHR tasks, demonstrating its superiority over state-of-the-art methods.
Imputation with Inter-Series Information from Prototypes for Irregular Sampled Time Series
Jan 14, 2024Irregularly sampled time series are ubiquitous, presenting significant challenges for analysis due to missing values. Despite existing methods address imputation, they predominantly focus on leveraging intra-series information, neglecting the potential benefits that inter-series information could provide, such as reducing uncertainty and memorization effect. To bridge this gap, we propose PRIME, a Prototype Recurrent Imputation ModEl, which integrates both intra-series and inter-series information for imputing missing values in irregularly sampled time series. Our framework comprises a prototype memory module for learning inter-series information, a bidirectional gated recurrent unit utilizing prototype information for imputation, and an attentive prototypical refinement module for adjusting imputations. We conducted extensive experiments on three datasets, and the results underscore PRIME's superiority over the state-of-the-art models by up to 26% relative improvement on mean square error.
Learning the Dynamic Correlations and Mitigating Noise by Hierarchical Convolution for Long-term Sequence Forecasting
Dec 28, 2023Deep learning algorithms, especially Transformer-based models, have achieved significant performance by capturing long-range dependencies and historical information. However, the power of convolution has not been fully investigated. Moreover, most existing works ignore the dynamic interaction among variables and evolutionary noise in series. Addressing these issues, we propose a Hierarchical Memorizing Network (HMNet). In particular, a hierarchical convolution structure is introduced to extract the information from the series at various scales. Besides, we propose a dynamic variable interaction module to learn the varying correlation and an adaptive denoising module to search and exploit similar patterns to alleviate noises. These modules can cooperate with the hierarchical structure from the perspective of fine to coarse grain. Experiments on five benchmarks demonstrate that HMNet significantly outperforms the state-of-the-art models by 10.6% on MSE and 5.7% on MAE. Our code is released at https://github.com/yzhHoward/HMNet.
Predict and Interpret Health Risk using EHR through Typical Patients
Dec 18, 2023Predicting health risks from electronic health records (EHR) is a topic of recent interest. Deep learning models have achieved success by modeling temporal and feature interaction. However, these methods learn insufficient representations and lead to poor performance when it comes to patients with few visits or sparse records. Inspired by the fact that doctors may compare the patient with typical patients and make decisions from similar cases, we propose a Progressive Prototypical Network (PPN) to select typical patients as prototypes and utilize their information to enhance the representation of the given patient. In particular, a progressive prototype memory and two prototype separation losses are proposed to update prototypes. Besides, a novel integration is introduced for better fusing information from patients and prototypes. Experiments on three real-world datasets demonstrate that our model brings improvement on all metrics. To make our results better understood by physicians, we developed an application at http://ppn.ai-care.top. Our code is released at https://github.com/yzhHoward/PPN.
Mortality Prediction with Adaptive Feature Importance Recalibration for Peritoneal Dialysis Patients: a deep-learning-based study on a real-world longitudinal follow-up dataset
Jan 17, 2023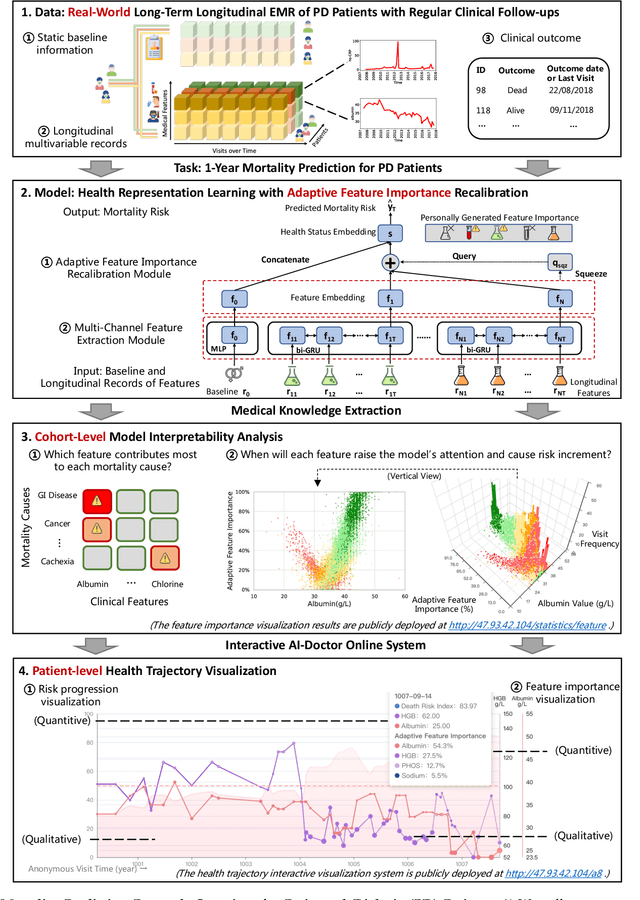
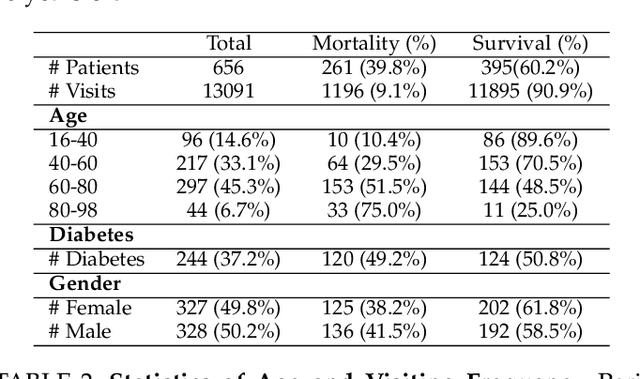
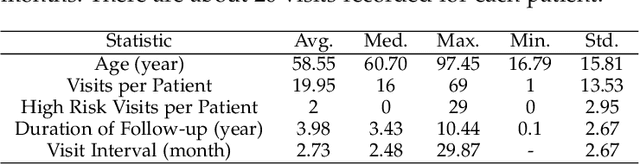
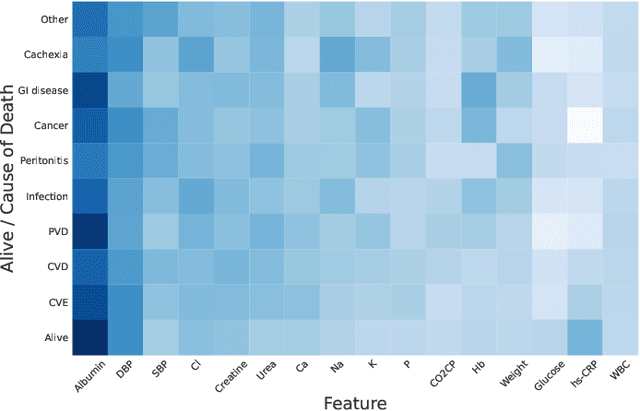
Objective: Peritoneal Dialysis (PD) is one of the most widely used life-supporting therapies for patients with End-Stage Renal Disease (ESRD). Predicting mortality risk and identifying modifiable risk factors based on the Electronic Medical Records (EMR) collected along with the follow-up visits are of great importance for personalized medicine and early intervention. Here, our objective is to develop a deep learning model for a real-time, individualized, and interpretable mortality prediction model - AICare. Method and Materials: Our proposed model consists of a multi-channel feature extraction module and an adaptive feature importance recalibration module. AICare explicitly identifies the key features that strongly indicate the outcome prediction for each patient to build the health status embedding individually. This study has collected 13,091 clinical follow-up visits and demographic data of 656 PD patients. To verify the application universality, this study has also collected 4,789 visits of 1,363 hemodialysis dialysis (HD) as an additional experiment dataset to test the prediction performance, which will be discussed in the Appendix. Results: 1) Experiment results show that AICare achieves 81.6%/74.3% AUROC and 47.2%/32.5% AUPRC for the 1-year mortality prediction task on PD/HD dataset respectively, which outperforms the state-of-the-art comparative deep learning models. 2) This study first provides a comprehensive elucidation of the relationship between the causes of mortality in patients with PD and clinical features based on an end-to-end deep learning model. 3) This study first reveals the pattern of variation in the importance of each feature in the mortality prediction based on built-in interpretability. 4) We develop a practical AI-Doctor interaction system to visualize the trajectory of patients' health status and risk indicators.
CovidCare: Transferring Knowledge from Existing EMR to Emerging Epidemic for Interpretable Prognosis
Jul 17, 2020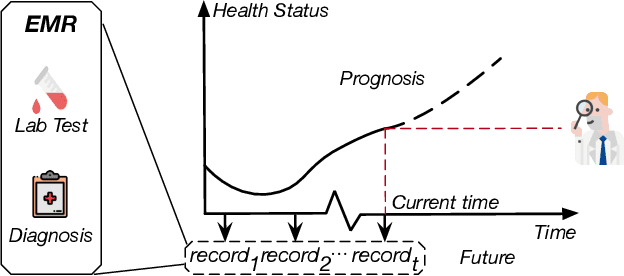

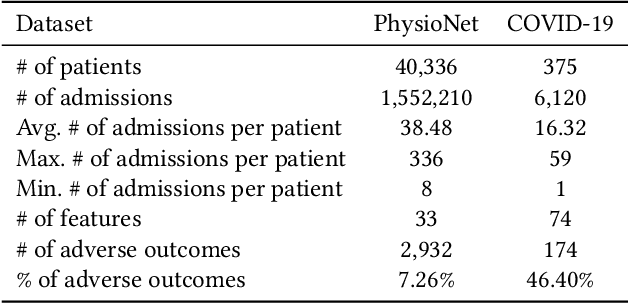
Due to the characteristics of COVID-19, the epidemic develops rapidly and overwhelms health service systems worldwide. Many patients suffer from systemic life-threatening problems and need to be carefully monitored in ICUs. Thus the intelligent prognosis is in an urgent need to assist physicians to take an early intervention, prevent the adverse outcome, and optimize the medical resource allocation. However, in the early stage of the epidemic outbreak, the data available for analysis is limited due to the lack of effective diagnostic mechanisms, rarity of the cases, and privacy concerns. In this paper, we propose a deep-learning-based approach, CovidCare, which leverages the existing electronic medical records to enhance the prognosis for inpatients with emerging infectious diseases. It learns to embed the COVID-19-related medical features based on massive existing EMR data via transfer learning. The transferred parameters are further trained to imitate the teacher model's representation behavior based on knowledge distillation, which embeds the health status more comprehensively in the source dataset. We conduct the length of stay prediction experiments for patients on a real-world COVID-19 dataset. The experiment results indicate that our proposed model consistently outperforms the comparative baseline methods. CovidCare also reveals that, 1) hs-cTnI, hs-CRP and Platelet Counts are the most fatal biomarkers, whose abnormal values usually indicate emergency adverse outcome. 2) Normal values of gamma-GT, AP and eGFR indicate the overall improvement of health. The medical findings extracted by CovidCare are empirically confirmed by human experts and medical literatures.