 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFT-Free PAPR Reduction Methods for OFDM Signals
Sep 17, 2025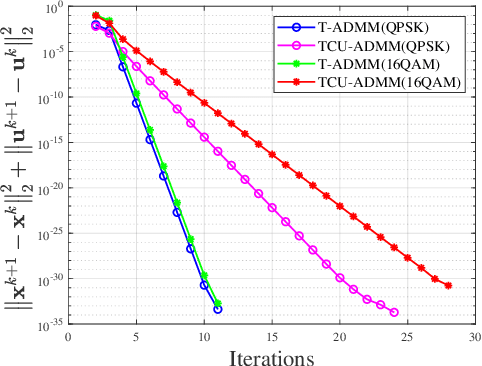
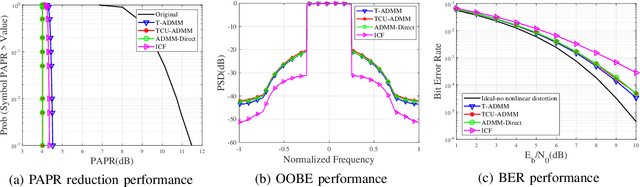
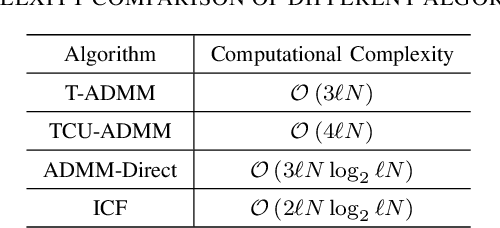
In this paper, we propose two low-complexity peak to average power ratio(PAPR) reduction algorithms for orthogonal frequency division multiplexing(OFDM) signals. The main content is as follows: First, a non-convex optimization model is established by minimizing the signal distortion power. Then, a customized alternating direction method of multipliers(ADMM) algorithm is proposed to solve the problem, named time domain ADMM(T-ADMM) along with an improved version called T-ADMM with constrain update(TCU-ADMM). In the algorithms, all subproblems can be solved analytically, and each iteration has linear computational complexity. These algorithms circumvents the challenges posed by repeated fast Fourier transform(FFT) and inverse FFT(IFFT) operations in traditional PAPR reduction algorithms. Additionally, we prove that the T-ADMM algorithm is theoretically guaranteed convergent if proper parameter is chosen. Finally, simulation results demonstrate the effectiveness of the proposed methods.
Unimodular Waveform Design for Integrated Sensing and Communication MIMO System via Manifold Optimization
Apr 08, 2025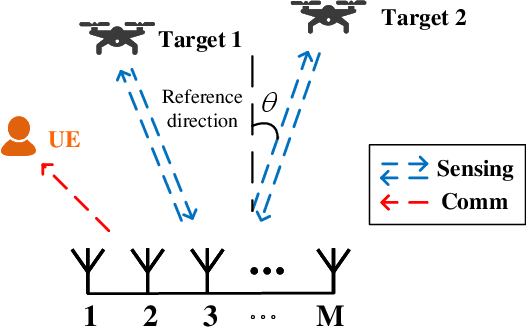
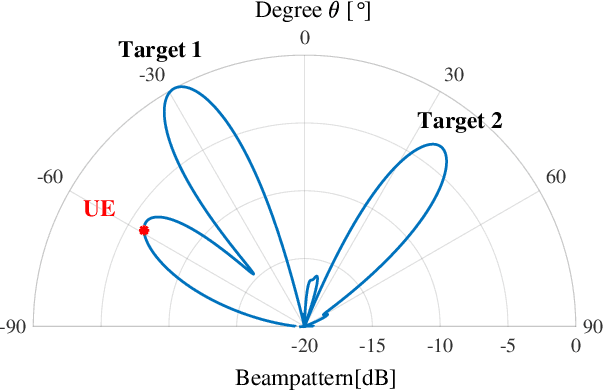
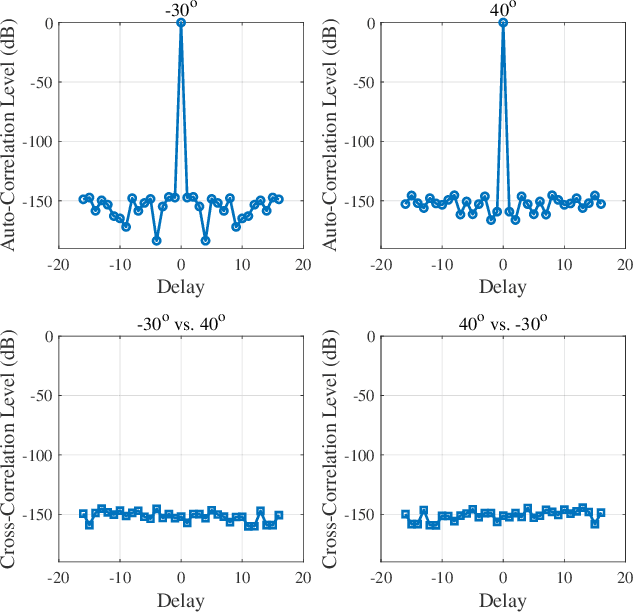
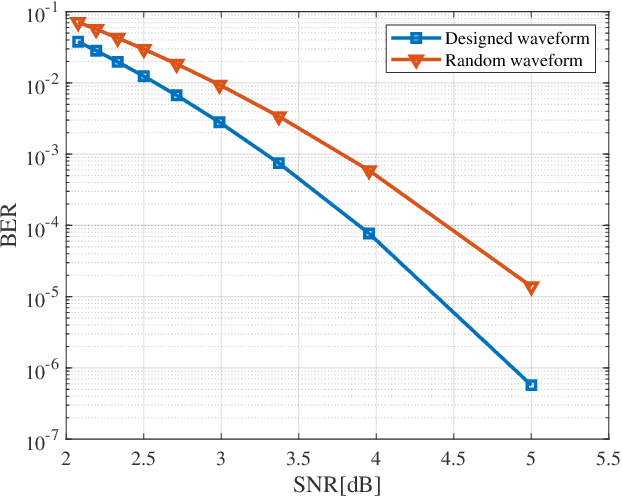
Integrated sensing and communication (ISAC) has been widely recognized as one of the key technologies for 6G wireless networks. In this paper, we focus on the waveform design of ISAC system, which can realize radar sensing while also facilitate information transmission. The main content is as follows: first, we formulate the waveform design problem as a nonconvex and non-smooth model with a unimodulus constraint based on the measurement metric of the radar and communication system. Second, we transform the model into an unconstrained problem on the Riemannian manifold and construct the corresponding operators by analyzing the unimodulus constraint. Third, to achieve the solution efficiently, we propose a low-complexity non-smooth unimodulus manifold gradient descent (N-UMGD) algorithm with theoretical convergence guarantee. The simulation results show that the proposed algorithm can concentrate the energy of the sensing signal in the desired direction and realize information transmission with a low bit error rate.
Scaling Image Tokenizers with Grouped Spherical Quantization
Dec 03, 2024



Vision tokenizers have gained a lot of attraction due to their scalability and compactness; previous works depend on old-school GAN-based hyperparameters, biased comparisons, and a lack of comprehensive analysis of the scaling behaviours. To tackle those issues, we introduce Grouped Spherical Quantization (GSQ), featuring spherical codebook initialization and lookup regularization to constrain codebook latent to a spherical surface. Our empirical analysis of image tokenizer training strategies demonstrates that GSQ-GAN achieves superior reconstruction quality over state-of-the-art methods with fewer training iterations, providing a solid foundation for scaling studies. Building on this, we systematically examine the scaling behaviours of GSQ, specifically in latent dimensionality, codebook size, and compression ratios, and their impact on model performance. Our findings reveal distinct behaviours at high and low spatial compression levels, underscoring challenges in representing high-dimensional latent spaces. We show that GSQ can restructure high-dimensional latent into compact, low-dimensional spaces, thus enabling efficient scaling with improved quality. As a result, GSQ-GAN achieves a 16x down-sampling with a reconstruction FID (rFID) of 0.50.
Data Pruning in Generative Diffusion Models
Nov 19, 2024



Data pruning is the problem of identifying a core subset that is most beneficial to training and discarding the remainder. While pruning strategies are well studied for discriminative models like those used in classification, little research has gone into their application to generative models. Generative models aim to estimate the underlying distribution of the data, so presumably they should benefit from larger datasets. In this work we aim to shed light on the accuracy of this statement, specifically answer the question of whether data pruning for generative diffusion models could have a positive impact. Contrary to intuition, we show that eliminating redundant or noisy data in large datasets is beneficial particularly when done strategically. We experiment with several pruning methods including recent-state-of-art methods, and evaluate over CelebA-HQ and ImageNet datasets. We demonstrate that a simple clustering method outperforms other sophisticated and computationally demanding methods. We further exhibit how we can leverage clustering to balance skewed datasets in an unsupervised manner to allow fair sampling for underrepresented populations in the data distribution, which is a crucial problem in generative models.
Designing Unimodular Waveforms with Good Correlation Properties for Large-Scale MIMO Radar via Manifold Optimization Method
Oct 10, 2024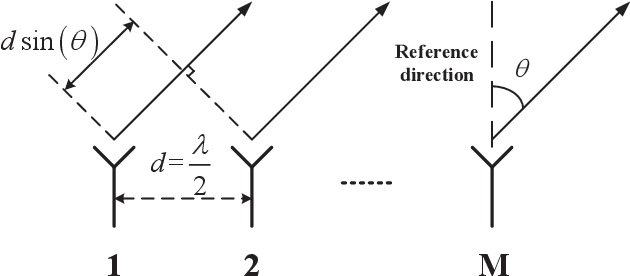
In this paper, we design constant modulus probing waveforms with good correlation properties for large-scale collocated multi-input multi-output (MIMO) radar systems. The main content is as follows: First, we formulate the design problem as a fourth-order polynomial minimization problem with unimodulus constraints. Then, by analyzing the geometric properties of the unimodulus constraints through Riemannian geometry theory and embedding them into the search space, we transform the original non-convex optimization problem into an unconstrained problem on a Riemannian manifold for solution. Second, we convert the objective function into the form of a large but finite number of loss functions and employ a customized R-SVRG algorithm to solve it. Third, we prove that the customized R-SVRG algorithm is theoretically guaranteed to converge if appropriate parameters are chosen. Numerical examples demonstrate the effectiveness of the proposed R-SVRG algorithm.
Time Transfer: On Optimal Learning Rate and Batch Size In The Infinite Data Limit
Oct 08, 2024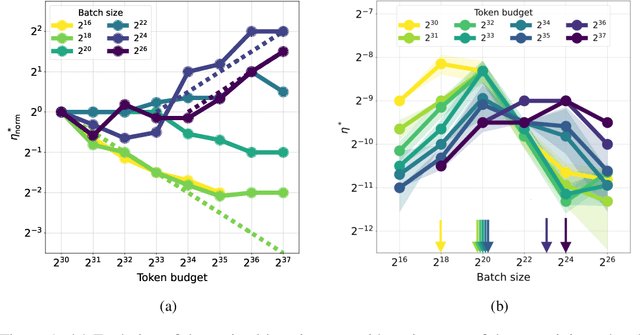
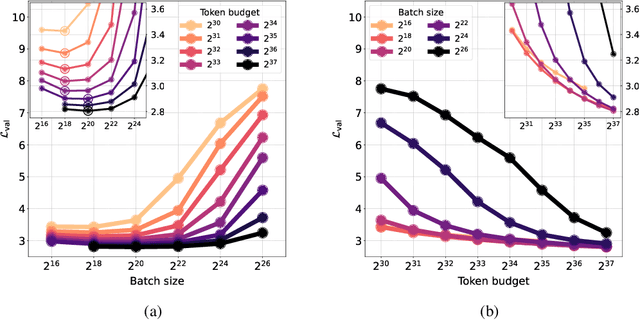
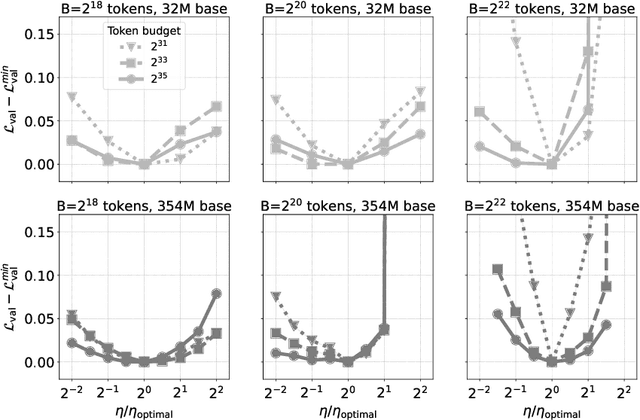
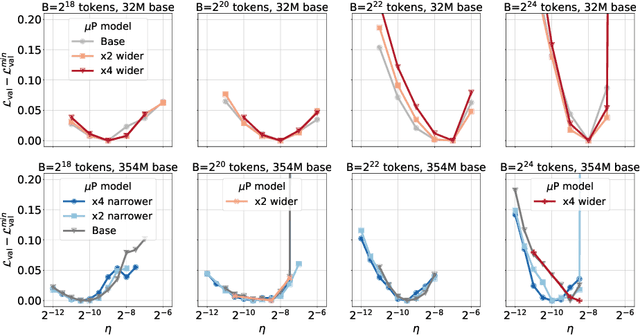
One of the main challenges in optimal scaling of large language models (LLMs) is the prohibitive cost of hyperparameter tuning, particularly learning rate $\eta$ and batch size $B$. While techniques like $\mu$P (Yang et al., 2022) provide scaling rules for optimal $\eta$ transfer in the infinite model size limit, the optimal scaling behavior in the infinite data size limit ($T \to \infty$) remains unknown. We fill in this gap by observing for the first time an interplay of three optimal $\eta$ scaling regimes: $\eta \propto \sqrt{T}$, $\eta \propto 1$, and $\eta \propto 1/\sqrt{T}$ with transitions controlled by $B$ and its relation to the time-evolving critical batch size $B_\mathrm{crit} \propto T$. Furthermore, we show that the optimal batch size is positively correlated with $B_\mathrm{crit}$: keeping it fixed becomes suboptimal over time even if learning rate is scaled optimally. Surprisingly, our results demonstrate that the observed optimal $\eta$ and $B$ dynamics are preserved with $\mu$P model scaling, challenging the conventional view of $B_\mathrm{crit}$ dependence solely on loss value. Complementing optimality, we examine the sensitivity of loss to changes in learning rate, where we find the sensitivity to decrease with $T \to \infty$ and to remain constant with $\mu$P model scaling. We hope our results make the first step towards a unified picture of the joint optimal data and model scaling.
Predict and Interpret Health Risk using EHR through Typical Patients
Dec 18, 2023Predicting health risks from electronic health records (EHR) is a topic of recent interest. Deep learning models have achieved success by modeling temporal and feature interaction. However, these methods learn insufficient representations and lead to poor performance when it comes to patients with few visits or sparse records. Inspired by the fact that doctors may compare the patient with typical patients and make decisions from similar cases, we propose a Progressive Prototypical Network (PPN) to select typical patients as prototypes and utilize their information to enhance the representation of the given patient. In particular, a progressive prototype memory and two prototype separation losses are proposed to update prototypes. Besides, a novel integration is introduced for better fusing information from patients and prototypes. Experiments on three real-world datasets demonstrate that our model brings improvement on all metrics. To make our results better understood by physicians, we developed an application at http://ppn.ai-care.top. Our code is released at https://github.com/yzhHoward/PPN.
OpenNet: Incremental Learning for Autonomous Driving Object Detection with Balanced Loss
Nov 25, 2023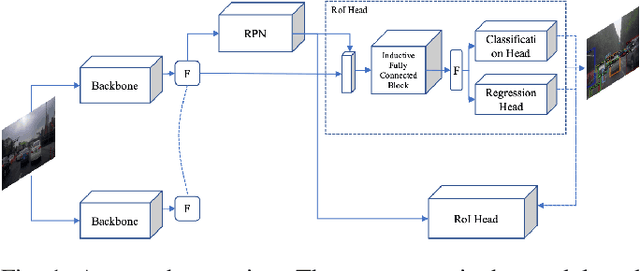

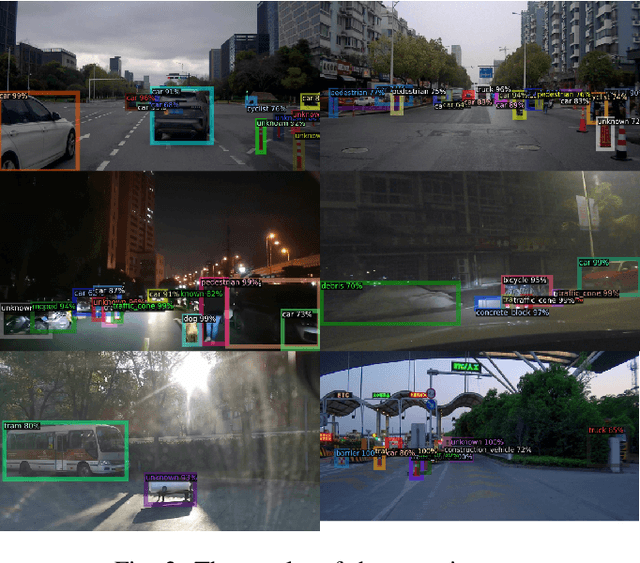

Automated driving object detection has always been a challenging task in computer vision due to environmental uncertainties. These uncertainties include significant differences in object sizes and encountering the class unseen. It may result in poor performance when traditional object detection models are directly applied to automated driving detection. Because they usually presume fixed categories of common traffic participants, such as pedestrians and cars. Worsely, the huge class imbalance between common and novel classes further exacerbates performance degradation. To address the issues stated, we propose OpenNet to moderate the class imbalance with the Balanced Loss, which is based on Cross Entropy Loss. Besides, we adopt an inductive layer based on gradient reshaping to fast learn new classes with limited samples during incremental learning. To against catastrophic forgetting, we employ normalized feature distillation. By the way, we improve multi-scale detection robustness and unknown class recognition through FPN and energy-based detection, respectively. The Experimental results upon the CODA dataset show that the proposed method can obtain better performance than that of the existing methods.
Exploit the antenna response consistency to define the alignment criteria for CSI data
Oct 10, 2023


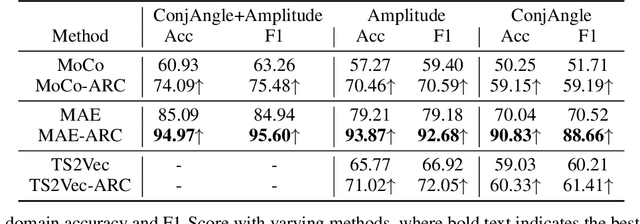
Self-supervised learning (SSL) for WiFi-based human activity recognition (HAR) holds great promise due to its ability to address the challenge of insufficient labeled data. However, directly transplanting SSL algorithms, especially contrastive learning, originally designed for other domains to CSI data, often fails to achieve the expected performance. We attribute this issue to the inappropriate alignment criteria, which disrupt the semantic distance consistency between the feature space and the input space. To address this challenge, we introduce \textbf{A}netenna \textbf{R}esponse \textbf{C}onsistency (ARC) as a solution to define proper alignment criteria. ARC is designed to retain semantic information from the input space while introducing robustness to real-world noise. We analyze ARC from the perspective of CSI data structure, demonstrating that its optimal solution leads to a direct mapping from input CSI data to action vectors in the feature map. Furthermore, we provide extensive experimental evidence to validate the effectiveness of ARC in improving the performance of self-supervised learning for WiFi-based HAR.
Self-Supervised Learning for WiFi CSI-Based Human Activity Recognition: A Systematic Study
Jul 19, 2023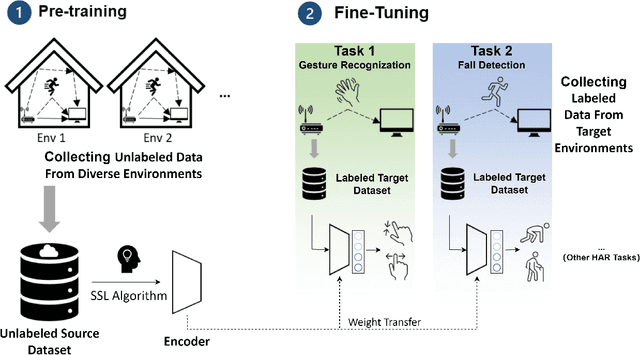

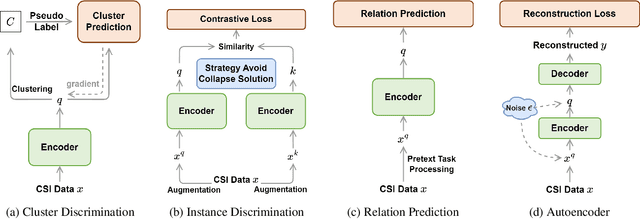
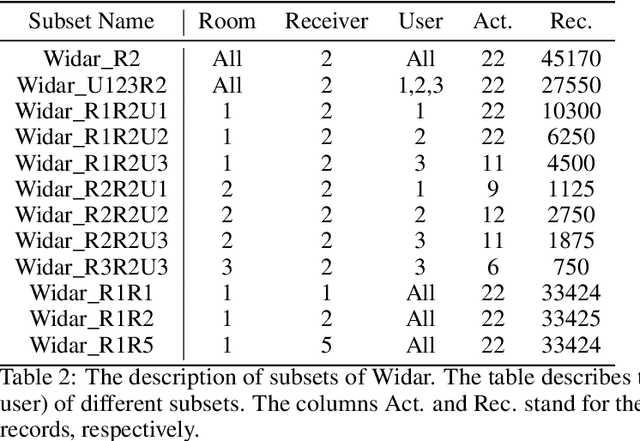
Recently, with the advancement of the Internet of Things (IoT), WiFi CSI-based HAR has gained increasing attention from academic and industry communities. By integrating the deep learning technology with CSI-based HAR, researchers achieve state-of-the-art performance without the need of expert knowledge. However, the scarcity of labeled CSI data remains the most prominent challenge when applying deep learning models in the context of CSI-based HAR due to the privacy and incomprehensibility of CSI-based HAR data. On the other hand, SSL has emerged as a promising approach for learning meaningful representations from data without heavy reliance on labeled examples. Therefore, considerable efforts have been made to address the challenge of insufficient data in deep learning by leveraging SSL algorithms. In this paper, we undertake a comprehensive inventory and analysis of the potential held by different categories of SSL algorithms, including those that have been previously studied and those that have not yet been explored, within the field. We provide an in-depth investigation of SSL algorithms in the context of WiFi CSI-based HAR. We evaluate four categories of SSL algorithms using three publicly available CSI HAR datasets, each encompassing different tasks and environmental settings. To ensure relevance to real-world applications, we design performance metrics that align with specific requirements. Furthermore, our experimental findings uncover several limitations and blind spots in existing work, highlighting the barriers that need to be addressed before SSL can be effectively deployed in real-world WiFi-based HAR applications. Our results also serve as a practical guideline for industry practitioners and provide valuable insights for future research endeavors in this field.