 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinAlign: Scaling Healthcare Alignment from Clinician Preference
Feb 11, 2026Although large language models (LLMs) demonstrate expert-level medical knowledge, aligning their open-ended outputs with fine-grained clinician preferences remains challenging. Existing methods often rely on coarse objectives or unreliable automated judges that are weakly grounded in professional guidelines. We propose a two-stage framework to address this gap. First, we introduce HealthRubrics, a dataset of 7,034 physician-verified preference examples in which clinicians refine LLM-drafted rubrics to meet rigorous medical standards. Second, we distill these rubrics into HealthPrinciples: 119 broadly reusable, clinically grounded principles organized by clinical dimensions, enabling scalable supervision beyond manual annotation. We use HealthPrinciples for (1) offline alignment by synthesizing rubrics for unlabeled queries and (2) an inference-time tool for guided self-revision. A 30B-A3B model trained with our framework achieves 33.4% on HealthBench-Hard, outperforming much larger models including Deepseek-R1 and o3, establishing a resource-efficient baseline for clinical alignment.
Predict and Interpret Health Risk using EHR through Typical Patients
Dec 18, 2023Predicting health risks from electronic health records (EHR) is a topic of recent interest. Deep learning models have achieved success by modeling temporal and feature interaction. However, these methods learn insufficient representations and lead to poor performance when it comes to patients with few visits or sparse records. Inspired by the fact that doctors may compare the patient with typical patients and make decisions from similar cases, we propose a Progressive Prototypical Network (PPN) to select typical patients as prototypes and utilize their information to enhance the representation of the given patient. In particular, a progressive prototype memory and two prototype separation losses are proposed to update prototypes. Besides, a novel integration is introduced for better fusing information from patients and prototypes. Experiments on three real-world datasets demonstrate that our model brings improvement on all metrics. To make our results better understood by physicians, we developed an application at http://ppn.ai-care.top. Our code is released at https://github.com/yzhHoward/PPN.
A Transfer-Learning-Based Prognosis Prediction Paradigm that Bridges Data Distribution Shift across EMR Datasets
Oct 11, 2023Due to the limited information about emerging diseases, symptoms are hard to be noticed and recognized, so that the window for clinical intervention could be ignored. An effective prognostic model is expected to assist doctors in making right diagnosis and designing personalized treatment plan, so to promptly prevent unfavorable outcomes. However, in the early stage of a disease, limited data collection and clinical experiences, plus the concern out of privacy and ethics, may result in restricted data availability for reference, to the extent that even data labels are difficult to mark correctly. In addition, Electronic Medical Record (EMR) data of different diseases or of different sources of the same disease can prove to be having serious cross-dataset feature misalignment problems, greatly mutilating the efficiency of deep learning models. This article introduces a transfer learning method to build a transition model from source dataset to target dataset. By way of constraining the distribution shift of features generated in disparate domains, domain-invariant features that are exclusively relative to downstream tasks are captured, so to cultivate a unified domain-invariant encoder across various task domains to achieve better feature representation. Experimental results of several target tasks demonstrate that our proposed model outperforms competing baseline methods and has higher rate of training convergence, especially in dealing with limited data amount. A multitude of experiences have proven the efficacy of our method to provide more accurate predictions concerning newly emergent pandemics and other diseases.
Mortality Prediction with Adaptive Feature Importance Recalibration for Peritoneal Dialysis Patients: a deep-learning-based study on a real-world longitudinal follow-up dataset
Jan 17, 2023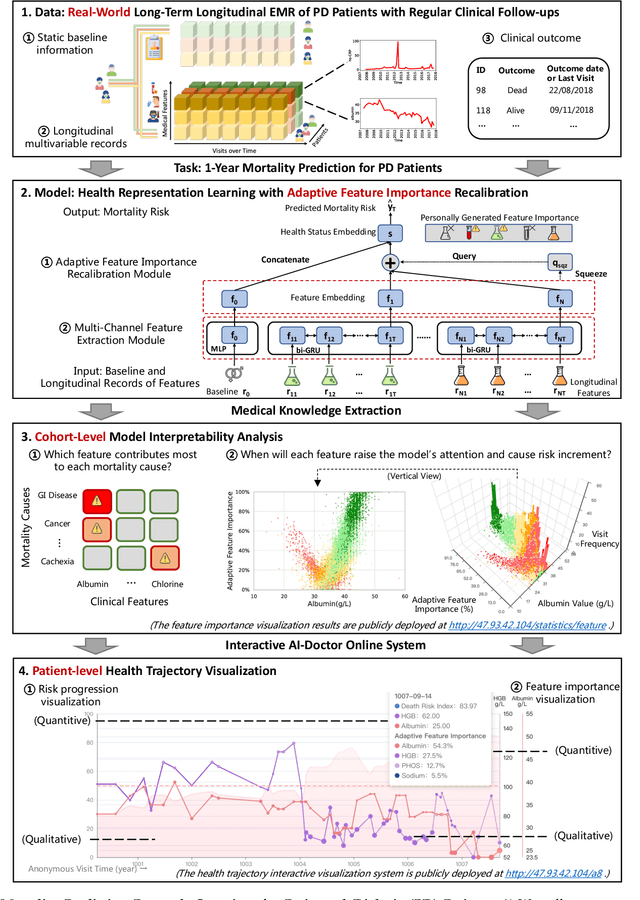
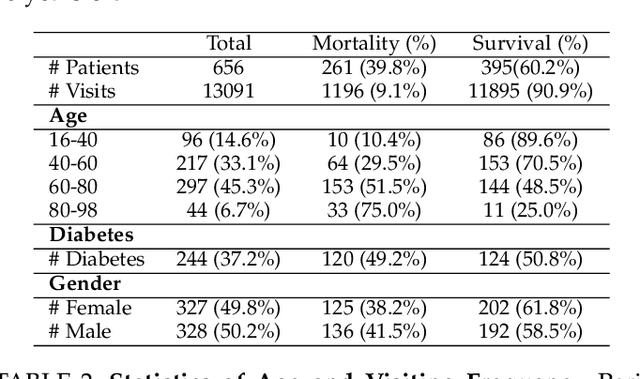
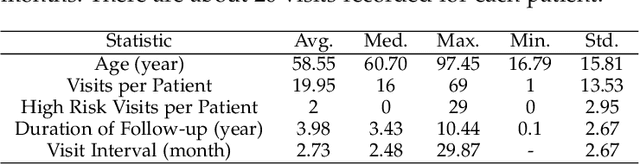
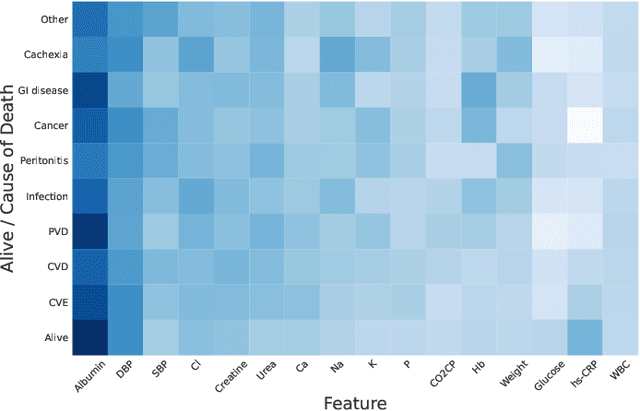
Objective: Peritoneal Dialysis (PD) is one of the most widely used life-supporting therapies for patients with End-Stage Renal Disease (ESRD). Predicting mortality risk and identifying modifiable risk factors based on the Electronic Medical Records (EMR) collected along with the follow-up visits are of great importance for personalized medicine and early intervention. Here, our objective is to develop a deep learning model for a real-time, individualized, and interpretable mortality prediction model - AICare. Method and Materials: Our proposed model consists of a multi-channel feature extraction module and an adaptive feature importance recalibration module. AICare explicitly identifies the key features that strongly indicate the outcome prediction for each patient to build the health status embedding individually. This study has collected 13,091 clinical follow-up visits and demographic data of 656 PD patients. To verify the application universality, this study has also collected 4,789 visits of 1,363 hemodialysis dialysis (HD) as an additional experiment dataset to test the prediction performance, which will be discussed in the Appendix. Results: 1) Experiment results show that AICare achieves 81.6%/74.3% AUROC and 47.2%/32.5% AUPRC for the 1-year mortality prediction task on PD/HD dataset respectively, which outperforms the state-of-the-art comparative deep learning models. 2) This study first provides a comprehensive elucidation of the relationship between the causes of mortality in patients with PD and clinical features based on an end-to-end deep learning model. 3) This study first reveals the pattern of variation in the importance of each feature in the mortality prediction based on built-in interpretability. 4) We develop a practical AI-Doctor interaction system to visualize the trajectory of patients' health status and risk indicators.
M$^3$Care: Learning with Missing Modalities in Multimodal Healthcare Data
Oct 28, 2022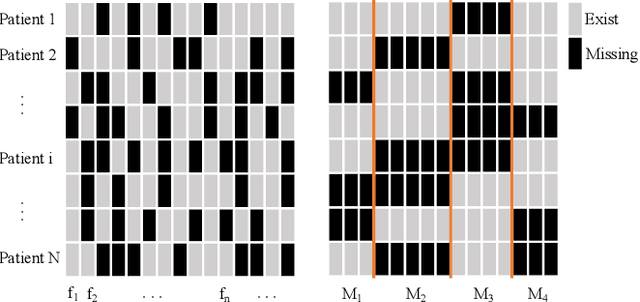



Multimodal electronic health record (EHR) data are widely used in clinical applications. Conventional methods usually assume that each sample (patient) is associated with the unified observed modalities, and all modalities are available for each sample. However, missing modality caused by various clinical and social reasons is a common issue in real-world clinical scenarios. Existing methods mostly rely on solving a generative model that learns a mapping from the latent space to the original input space, which is an unstable ill-posed inverse problem. To relieve the underdetermined system, we propose a model solving a direct problem, dubbed learning with Missing Modalities in Multimodal healthcare data (M3Care). M3Care is an end-to-end model compensating the missing information of the patients with missing modalities to perform clinical analysis. Instead of generating raw missing data, M3Care imputes the task-related information of the missing modalities in the latent space by the auxiliary information from each patient's similar neighbors, measured by a task-guided modality-adaptive similarity metric, and thence conducts the clinical tasks. The task-guided modality-adaptive similarity metric utilizes the uncensored modalities of the patient and the other patients who also have the same uncensored modalities to find similar patients. Experiments on real-world datasets show that M3Care outperforms the state-of-the-art baselines. Moreover, the findings discovered by M3Care are consistent with experts and medical knowledge, demonstrating the capability and the potential of providing useful insights and explanations.
* 9 pages
CovidCare: Transferring Knowledge from Existing EMR to Emerging Epidemic for Interpretable Prognosis
Jul 17, 2020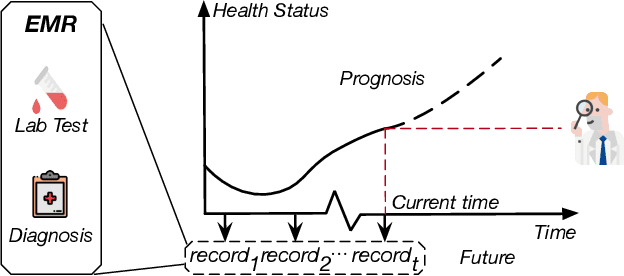

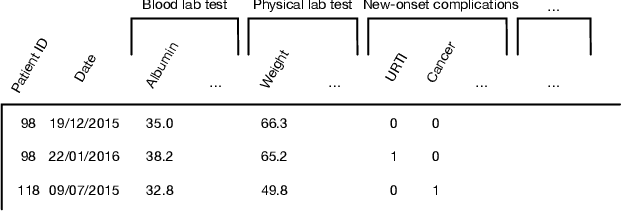
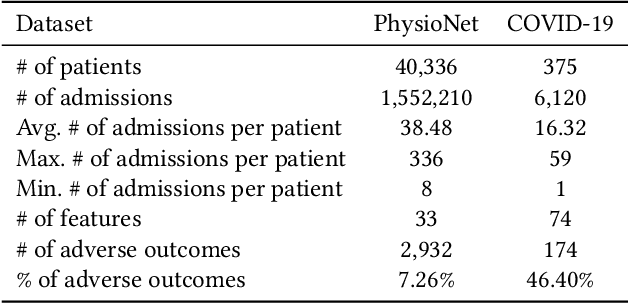
Due to the characteristics of COVID-19, the epidemic develops rapidly and overwhelms health service systems worldwide. Many patients suffer from systemic life-threatening problems and need to be carefully monitored in ICUs. Thus the intelligent prognosis is in an urgent need to assist physicians to take an early intervention, prevent the adverse outcome, and optimize the medical resource allocation. However, in the early stage of the epidemic outbreak, the data available for analysis is limited due to the lack of effective diagnostic mechanisms, rarity of the cases, and privacy concerns. In this paper, we propose a deep-learning-based approach, CovidCare, which leverages the existing electronic medical records to enhance the prognosis for inpatients with emerging infectious diseases. It learns to embed the COVID-19-related medical features based on massive existing EMR data via transfer learning. The transferred parameters are further trained to imitate the teacher model's representation behavior based on knowledge distillation, which embeds the health status more comprehensively in the source dataset. We conduct the length of stay prediction experiments for patients on a real-world COVID-19 dataset. The experiment results indicate that our proposed model consistently outperforms the comparative baseline methods. CovidCare also reveals that, 1) hs-cTnI, hs-CRP and Platelet Counts are the most fatal biomarkers, whose abnormal values usually indicate emergency adverse outcome. 2) Normal values of gamma-GT, AP and eGFR indicate the overall improvement of health. The medical findings extracted by CovidCare are empirically confirmed by human experts and medical literatures.
ConCare: Personalized Clinical Feature Embedding via Capturing the Healthcare Context
Nov 27, 2019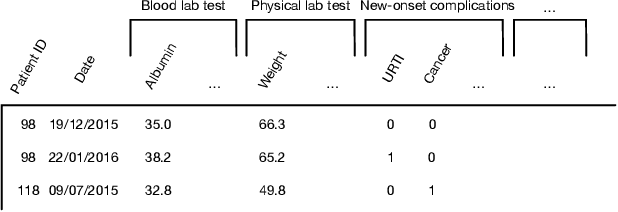

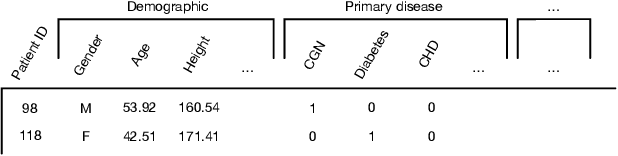
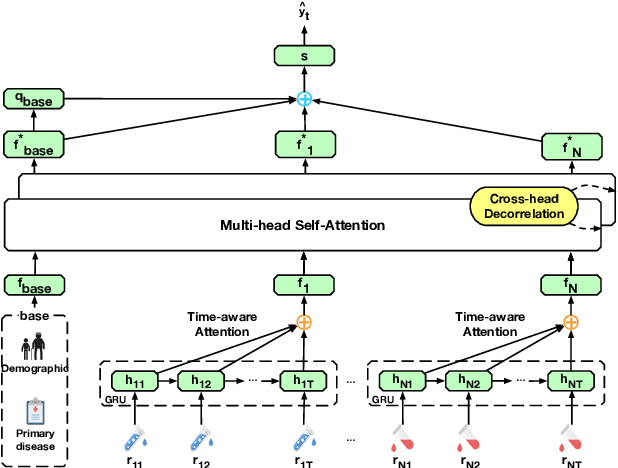
Predicting the patient's clinical outcome from the historical electronic medical records (EMR) is a fundamental research problem in medical informatics. Most deep learning-based solutions for EMR analysis concentrate on learning the clinical visit embedding and exploring the relations between visits. Although those works have shown superior performances in healthcare prediction, they fail to explore the personal characteristics during the clinical visits thoroughly. Moreover, existing works usually assume that the more recent record weights more in the prediction, but this assumption is not suitable for all conditions. In this paper, we propose ConCare to handle the irregular EMR data and extract feature interrelationship to perform individualized healthcare prediction. Our solution can embed the feature sequences separately by modeling the time-aware distribution. ConCare further improves the multi-head self-attention via the cross-head decorrelation, so that the inter-dependencies among dynamic features and static baseline information can be effectively captured to form the personal health context. Experimental results on two real-world EMR datasets demonstrate the effectiveness of ConCare. The medical findings extracted by ConCare are also empirically confirmed by human experts and medical literature.
AdaCare: Explainable Clinical Health Status Representation Learning via Scale-Adaptive Feature Extraction and Recalibration
Nov 27, 2019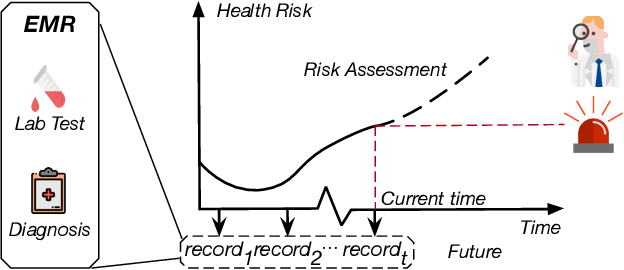

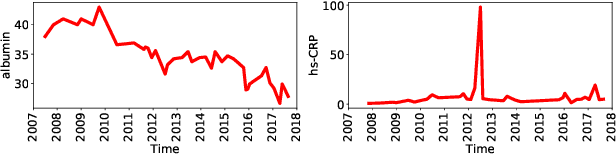

Deep learning-based health status representation learning and clinical prediction have raised much research interest in recent years. Existing models have shown superior performance, but there are still several major issues that have not been fully taken into consideration. First, the historical variation pattern of the biomarker in diverse time scales plays a vital role in indicating the health status, but it has not been explicitly extracted by existing works. Second, key factors that strongly indicate the health risk are different among patients. It is still challenging to adaptively make use of the features for patients in diverse conditions. Third, using prediction models as the black box will limit the reliability in clinical practice. However, none of the existing works can provide satisfying interpretability and meanwhile achieve high prediction performance. In this work, we develop a general health status representation learning model, named AdaCare. It can capture the long and short-term variations of biomarkers as clinical features to depict the health status in multiple time scales. It also models the correlation between clinical features to enhance the ones which strongly indicate the health status and thus can maintain a state-of-the-art performance in terms of prediction accuracy while providing qualitative interpretability. We conduct a health risk prediction experiment on two real-world datasets. Experiment results indicate that AdaCare outperforms state-of-the-art approaches and provides effective interpretability, which is verifiable by clinical experts.