 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
From Off-Policy to On-Policy: Enhancing GUI Agents via Bi-level Expert-to-Policy Assimilation
Jan 09, 2026Vision-language models are increasingly deployed as computer-use agents (CUAs) that operate desktops and browsers. Top-performing CUAs are framework-based systems that decompose planning and execution, while end-to-end screenshot-to-action policies are easier to deploy but lag behind on benchmarks such as OSWorld-Verified. GUI datasets like OSWorld pose two bottlenecks: they expose only a few hundred interactive, verifiable tasks and environments, and expert trajectories must be gathered by interacting with these environments, making such data hard to scale. We therefore ask how reinforcement learning from verifiable rewards (RLVR) can best exploit a small pool of exist expert trajectories to train end-to-end policies. Naively mixing these off-policy traces into on-policy RLVR is brittle: even after format conversion, expert trajectories exhibit structural mismatch and distribution shift from the learner. We propose BEPA (Bi-Level Expert-to-Policy Assimilation), which turns static expert traces into policy-aligned guidance via self-rolled reachable trajectories under the base policy (LEVEL-1) and a per-task, dynamically updated cache used in RLVR (LEVEL-2). On OSWorld-Verified, BEPA improves UITARS1.5-7B success from 22.87% to 32.13% and raises a held-out split from 5.74% to 10.30%, with consistent gains on MMBench-GUI and Online-Mind2Web. Our code and data are available at: https://github.com/LEON-gittech/Verl_GUI.git
InfiniteWeb: Scalable Web Environment Synthesis for GUI Agent Training
Jan 08, 2026GUI agents that interact with graphical interfaces on behalf of users represent a promising direction for practical AI assistants. However, training such agents is hindered by the scarcity of suitable environments. We present InfiniteWeb, a system that automatically generates functional web environments at scale for GUI agent training. While LLMs perform well on generating a single webpage, building a realistic and functional website with many interconnected pages faces challenges. We address these challenges through unified specification, task-centric test-driven development, and a combination of website seed with reference design image to ensure diversity. Our system also generates verifiable task evaluators enabling dense reward signals for reinforcement learning. Experiments show that InfiniteWeb surpasses commercial coding agents at realistic website construction, and GUI agents trained on our generated environments achieve significant performance improvements on OSWorld and Online-Mind2Web, demonstrating the effectiveness of proposed system.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025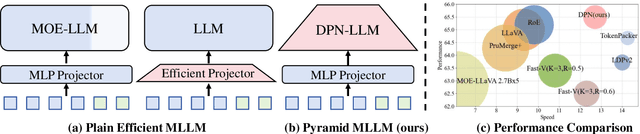

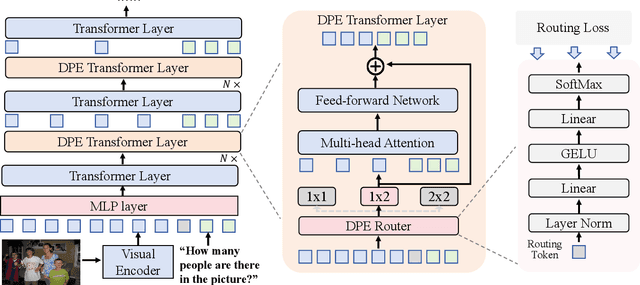

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
Utilizing Causal Network Markers to Identify Tipping Points ahead of Critical Transition
Dec 19, 2024



Early-warning signals of delicate design are always used to predict critical transitions in complex systems, which makes it possible to render the systems far away from the catastrophic state by introducing timely interventions. Traditional signals including the dynamical network biomarker (DNB), based on statistical properties such as variance and autocorrelation of nodal dynamics, overlook directional interactions and thus have limitations in capturing underlying mechanisms and simultaneously sustaining robustness against noise perturbations. This paper therefore introduces a framework of causal network markers (CNMs) by incorporating causality indicators, which reflect the directional influence between variables. Actually, to detect and identify the tipping points ahead of critical transition, two markers are designed: CNM-GC for linear causality and CNM-TE for non-linear causality, as well as a functional representation of different causality indicators and a clustering technique to verify the system's dominant group. Through demonstrations using benchmark models and real-world datasets of epileptic seizure, the framework of CNMs shows higher predictive power and accuracy than the traditional DNB indicator. It is believed that, due to the versatility and scalability, the CNMs are suitable for comprehensively evaluating the systems. The most possible direction for application includes the identification of tipping points in clinical disease.
Federated Instruction Tuning of LLMs with Domain Coverage Augmentation
Sep 30, 2024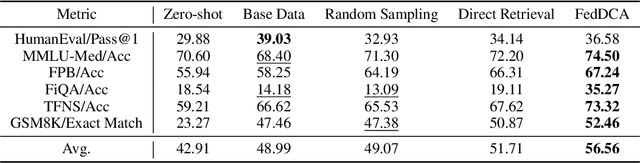
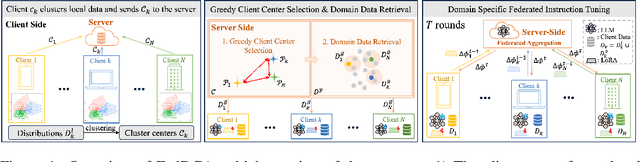
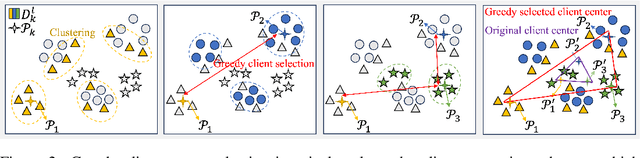
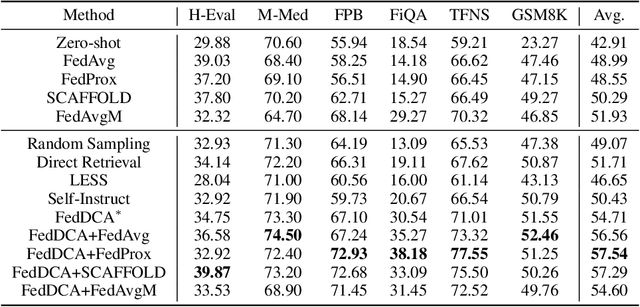
Federated Domain-specific Instruction Tuning (FedDIT) leverages a few cross-client private data and server-side public data for instruction augmentation, enhancing model performance in specific domains. While the factors affecting FedDIT remain unclear and existing instruction augmentation methods mainly focus on the centralized setting without considering the distributed environment. Firstly, our experiments show that cross-client domain coverage, rather than data heterogeneity, drives model performance in FedDIT. Thus, we propose FedDCA, which maximizes domain coverage through greedy client center selection and retrieval-based augmentation. To reduce client-side computation, FedDCA$^*$ uses heterogeneous encoders with server-side feature alignment. Extensive experiments across four domains (code, medical, financial, and mathematical) validate the effectiveness of both methods. Additionally, we explore the privacy protection against memory extraction attacks with various amounts of public data and results show that there is no significant correlation between the amount of public data and the privacy-preserving capability. However, as the fine-tuning round increases, the risk of privacy leakage reduces or converges.
OpenNet: Incremental Learning for Autonomous Driving Object Detection with Balanced Loss
Nov 25, 2023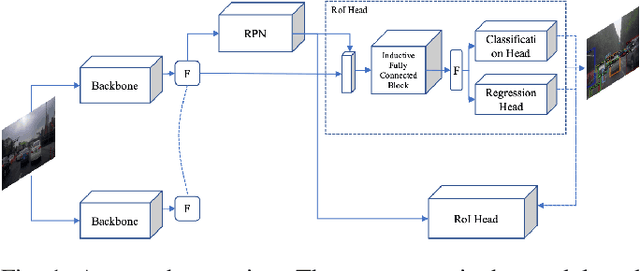

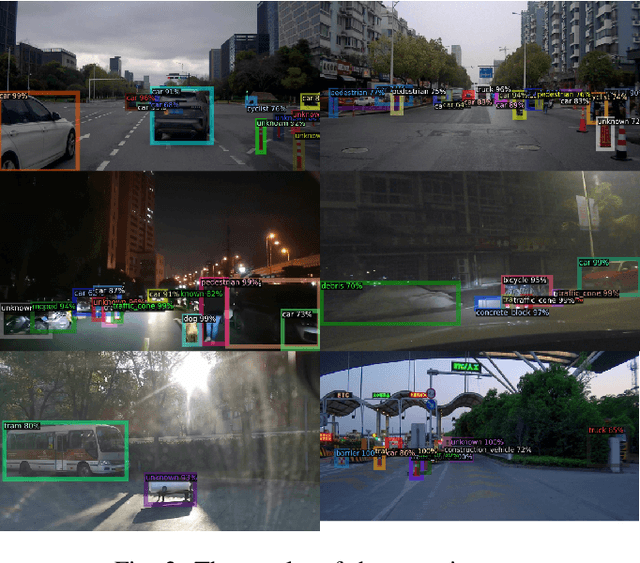

Automated driving object detection has always been a challenging task in computer vision due to environmental uncertainties. These uncertainties include significant differences in object sizes and encountering the class unseen. It may result in poor performance when traditional object detection models are directly applied to automated driving detection. Because they usually presume fixed categories of common traffic participants, such as pedestrians and cars. Worsely, the huge class imbalance between common and novel classes further exacerbates performance degradation. To address the issues stated, we propose OpenNet to moderate the class imbalance with the Balanced Loss, which is based on Cross Entropy Loss. Besides, we adopt an inductive layer based on gradient reshaping to fast learn new classes with limited samples during incremental learning. To against catastrophic forgetting, we employ normalized feature distillation. By the way, we improve multi-scale detection robustness and unknown class recognition through FPN and energy-based detection, respectively. The Experimental results upon the CODA dataset show that the proposed method can obtain better performance than that of the existing methods.