 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Off-Policy to On-Policy: Enhancing GUI Agents via Bi-level Expert-to-Policy Assimilation
Jan 09, 2026Vision-language models are increasingly deployed as computer-use agents (CUAs) that operate desktops and browsers. Top-performing CUAs are framework-based systems that decompose planning and execution, while end-to-end screenshot-to-action policies are easier to deploy but lag behind on benchmarks such as OSWorld-Verified. GUI datasets like OSWorld pose two bottlenecks: they expose only a few hundred interactive, verifiable tasks and environments, and expert trajectories must be gathered by interacting with these environments, making such data hard to scale. We therefore ask how reinforcement learning from verifiable rewards (RLVR) can best exploit a small pool of exist expert trajectories to train end-to-end policies. Naively mixing these off-policy traces into on-policy RLVR is brittle: even after format conversion, expert trajectories exhibit structural mismatch and distribution shift from the learner. We propose BEPA (Bi-Level Expert-to-Policy Assimilation), which turns static expert traces into policy-aligned guidance via self-rolled reachable trajectories under the base policy (LEVEL-1) and a per-task, dynamically updated cache used in RLVR (LEVEL-2). On OSWorld-Verified, BEPA improves UITARS1.5-7B success from 22.87% to 32.13% and raises a held-out split from 5.74% to 10.30%, with consistent gains on MMBench-GUI and Online-Mind2Web. Our code and data are available at: https://github.com/LEON-gittech/Verl_GUI.git
Federated Instruction Tuning of LLMs with Domain Coverage Augmentation
Sep 30, 2024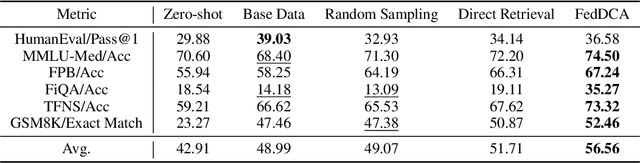
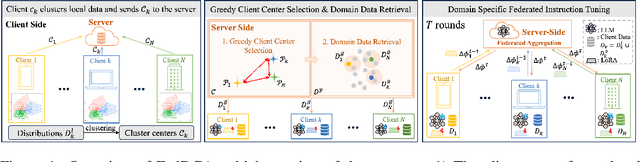
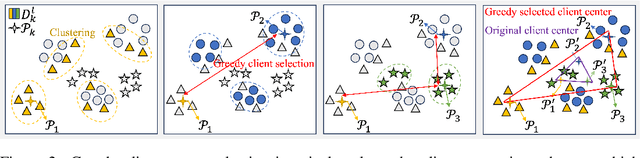
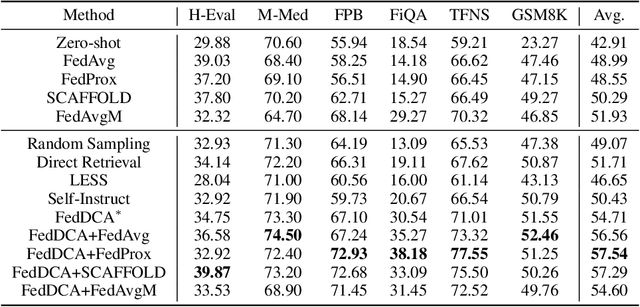
Federated Domain-specific Instruction Tuning (FedDIT) leverages a few cross-client private data and server-side public data for instruction augmentation, enhancing model performance in specific domains. While the factors affecting FedDIT remain unclear and existing instruction augmentation methods mainly focus on the centralized setting without considering the distributed environment. Firstly, our experiments show that cross-client domain coverage, rather than data heterogeneity, drives model performance in FedDIT. Thus, we propose FedDCA, which maximizes domain coverage through greedy client center selection and retrieval-based augmentation. To reduce client-side computation, FedDCA$^*$ uses heterogeneous encoders with server-side feature alignment. Extensive experiments across four domains (code, medical, financial, and mathematical) validate the effectiveness of both methods. Additionally, we explore the privacy protection against memory extraction attacks with various amounts of public data and results show that there is no significant correlation between the amount of public data and the privacy-preserving capability. However, as the fine-tuning round increases, the risk of privacy leakage reduces or converges.