 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Off-Policy to On-Policy: Enhancing GUI Agents via Bi-level Expert-to-Policy Assimilation
Jan 09, 2026Vision-language models are increasingly deployed as computer-use agents (CUAs) that operate desktops and browsers. Top-performing CUAs are framework-based systems that decompose planning and execution, while end-to-end screenshot-to-action policies are easier to deploy but lag behind on benchmarks such as OSWorld-Verified. GUI datasets like OSWorld pose two bottlenecks: they expose only a few hundred interactive, verifiable tasks and environments, and expert trajectories must be gathered by interacting with these environments, making such data hard to scale. We therefore ask how reinforcement learning from verifiable rewards (RLVR) can best exploit a small pool of exist expert trajectories to train end-to-end policies. Naively mixing these off-policy traces into on-policy RLVR is brittle: even after format conversion, expert trajectories exhibit structural mismatch and distribution shift from the learner. We propose BEPA (Bi-Level Expert-to-Policy Assimilation), which turns static expert traces into policy-aligned guidance via self-rolled reachable trajectories under the base policy (LEVEL-1) and a per-task, dynamically updated cache used in RLVR (LEVEL-2). On OSWorld-Verified, BEPA improves UITARS1.5-7B success from 22.87% to 32.13% and raises a held-out split from 5.74% to 10.30%, with consistent gains on MMBench-GUI and Online-Mind2Web. Our code and data are available at: https://github.com/LEON-gittech/Verl_GUI.git
InfiniteWeb: Scalable Web Environment Synthesis for GUI Agent Training
Jan 08, 2026GUI agents that interact with graphical interfaces on behalf of users represent a promising direction for practical AI assistants. However, training such agents is hindered by the scarcity of suitable environments. We present InfiniteWeb, a system that automatically generates functional web environments at scale for GUI agent training. While LLMs perform well on generating a single webpage, building a realistic and functional website with many interconnected pages faces challenges. We address these challenges through unified specification, task-centric test-driven development, and a combination of website seed with reference design image to ensure diversity. Our system also generates verifiable task evaluators enabling dense reward signals for reinforcement learning. Experiments show that InfiniteWeb surpasses commercial coding agents at realistic website construction, and GUI agents trained on our generated environments achieve significant performance improvements on OSWorld and Online-Mind2Web, demonstrating the effectiveness of proposed system.
UI-Evol: Automatic Knowledge Evolving for Computer Use Agents
May 28, 2025External knowledge has played a crucial role in the recent development of computer use agents. We identify a critical knowledge-execution gap: retrieved knowledge often fails to translate into effective real-world task execution. Our analysis shows even 90\% correct knowledge yields only 41\% execution success rate. To bridge this gap, we propose UI-Evol, a plug-and-play module for autonomous GUI knowledge evolution. UI-Evol consists of two stages: a Retrace Stage that extracts faithful objective action sequences from actual agent-environment interactions, and a Critique Stage that refines existing knowledge by comparing these sequences against external references. We conduct comprehensive experiments on the OSWorld benchmark with the state-of-the-art Agent S2. Our results demonstrate that UI-Evol not only significantly boosts task performance but also addresses a previously overlooked issue of high behavioral standard deviation in computer use agents, leading to superior performance on computer use tasks and substantially improved agent reliability.
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding
May 23, 2025Long-form video understanding presents significant challenges due to extensive temporal-spatial complexity and the difficulty of question answering under such extended contexts. While Large Language Models (LLMs) have demonstrated considerable advancements in video analysis capabilities and long context handling, they continue to exhibit limitations when processing information-dense hour-long videos. To overcome such limitations, we propose the Deep Video Discovery agent to leverage an agentic search strategy over segmented video clips. Different from previous video agents manually designing a rigid workflow, our approach emphasizes the autonomous nature of agents. By providing a set of search-centric tools on multi-granular video database, our DVD agent leverages the advanced reasoning capability of LLM to plan on its current observation state, strategically selects tools, formulates appropriate parameters for actions, and iteratively refines its internal reasoning in light of the gathered information. We perform comprehensive evaluation on multiple long video understanding benchmarks that demonstrates the advantage of the entire system design. Our DVD agent achieves SOTA performance, significantly surpassing prior works by a large margin on the challenging LVBench dataset. Comprehensive ablation studies and in-depth tool analyses are also provided, yielding insights to further advance intelligent agents tailored for long-form video understanding tasks. The code will be released later.
UI-E2I-Synth: Advancing GUI Grounding with Large-Scale Instruction Synthesis
Apr 16, 2025Recent advancements in Large Vision-Language Models are accelerating the development of Graphical User Interface (GUI) agents that utilize human-like vision perception capabilities to enhance productivity on digital devices. Compared to approaches predicated on GUI metadata, which are platform-dependent and vulnerable to implementation variations, vision-based approaches offer broader applicability. In this vision-based paradigm, the GUI instruction grounding, which maps user instruction to the location of corresponding element on the given screenshot, remains a critical challenge, particularly due to limited public training dataset and resource-intensive manual instruction data annotation. In this paper, we delve into unexplored challenges in this task including element-to-screen ratio, unbalanced element type, and implicit instruction. To address these challenges, we introduce a large-scale data synthesis pipeline UI-E2I-Synth for generating varying complex instruction datasets using GPT-4o instead of human annotators. Furthermore, we propose a new GUI instruction grounding benchmark UI-I2E-Bench, which is designed to address the limitations of existing benchmarks by incorporating diverse annotation aspects. Our model, trained on the synthesized data, achieves superior performance in GUI instruction grounding, demonstrating the advancements of proposed data synthesis pipeline. The proposed benchmark, accompanied by extensive analyses, provides practical insights for future research in GUI grounding. We will release corresponding artifacts at https://colmon46.github.io/i2e-bench-leaderboard/ .
Text Grouping Adapter: Adapting Pre-trained Text Detector for Layout Analysis
May 13, 2024



Significant progress has been made in scene text detection models since the rise of deep learning, but scene text layout analysis, which aims to group detected text instances as paragraphs, has not kept pace. Previous works either treated text detection and grouping using separate models, or train a model from scratch while using a unified one. All of them have not yet made full use of the already well-trained text detectors and easily obtainable detection datasets. In this paper, we present Text Grouping Adapter (TGA), a module that can enable the utilization of various pre-trained text detectors to learn layout analysis, allowing us to adopt a well-trained text detector right off the shelf or just fine-tune it efficiently. Designed to be compatible with various text detector architectures, TGA takes detected text regions and image features as universal inputs to assemble text instance features. To capture broader contextual information for layout analysis, we propose to predict text group masks from text instance features by one-to-many assignment. Our comprehensive experiments demonstrate that, even with frozen pre-trained models, incorporating our TGA into various pre-trained text detectors and text spotters can achieve superior layout analysis performance, simultaneously inheriting generalized text detection ability from pre-training. In the case of full parameter fine-tuning, we can further improve layout analysis performance.
Talaria: Interactively Optimizing Machine Learning Models for Efficient Inference
Apr 03, 2024
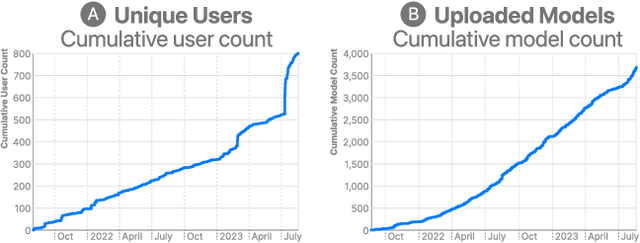
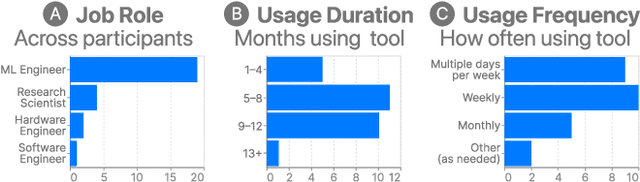
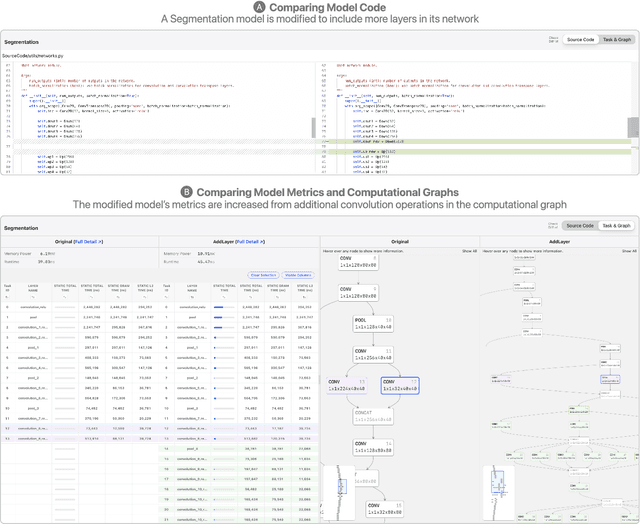
On-device machine learning (ML) moves computation from the cloud to personal devices, protecting user privacy and enabling intelligent user experiences. However, fitting models on devices with limited resources presents a major technical challenge: practitioners need to optimize models and balance hardware metrics such as model size, latency, and power. To help practitioners create efficient ML models, we designed and developed Talaria: a model visualization and optimization system. Talaria enables practitioners to compile models to hardware, interactively visualize model statistics, and simulate optimizations to test the impact on inference metrics. Since its internal deployment two years ago, we have evaluated Talaria using three methodologies: (1) a log analysis highlighting its growth of 800+ practitioners submitting 3,600+ models; (2) a usability survey with 26 users assessing the utility of 20 Talaria features; and (3) a qualitative interview with the 7 most active users about their experience using Talaria.
GO-FEAP: Global Optimal UAV Planner Using Frontier-Omission-Aware Exploration and Altitude-Stratified Planning
Oct 24, 2023Autonomous exploration is a fundamental problem for various applications of unmanned aerial vehicles(UAVs). Existing methods, however, are demonstrated to static local optima and two-dimensional exploration. To address these challenges, this paper introduces GO-FEAP (Global Optimal UAV Planner Using Frontier-Omission-Aware Exploration and Altitude-Stratified Planning), aiming to achieve efficient and complete three-dimensional exploration. Frontier-Omission-Aware Exploration module presented in this work takes into account multiple pivotal factors, encompassing frontier distance, nearby frontier count, frontier duration, and frontier categorization, for a comprehensive assessment of frontier importance. Furthermore, to tackle scenarios with substantial vertical variations, we introduce the Altitude-Stratified Planning strategy, which stratifies the three-dimensional space based on altitude, conducting global-local planning for each stratum. The objective of global planning is to identify the most optimal frontier for exploration, followed by viewpoint selection and local path optimization based on frontier type, ultimately generating dynamically feasible three-dimensional spatial exploration trajectories. We present extensive benchmark and real-world tests, in which our method completes the exploration tasks with unprecedented completeness compared to state-of-the-art approaches.
Reinforced UI Instruction Grounding: Towards a Generic UI Task Automation API
Oct 07, 2023Recent popularity of Large Language Models (LLMs) has opened countless possibilities in automating numerous AI tasks by connecting LLMs to various domain-specific models or APIs, where LLMs serve as dispatchers while domain-specific models or APIs are action executors. Despite the vast numbers of domain-specific models/APIs, they still struggle to comprehensively cover super diverse automation demands in the interaction between human and User Interfaces (UIs). In this work, we build a multimodal model to ground natural language instructions in given UI screenshots as a generic UI task automation executor. This metadata-free grounding model, consisting of a visual encoder and a language decoder, is first pretrained on well studied document understanding tasks and then learns to decode spatial information from UI screenshots in a promptable way. To facilitate the exploitation of image-to-text pretrained knowledge, we follow the pixel-to-sequence paradigm to predict geometric coordinates in a sequence of tokens using a language decoder. We further propose an innovative Reinforcement Learning (RL) based algorithm to supervise the tokens in such sequence jointly with visually semantic metrics, which effectively strengthens the spatial decoding capability of the pixel-to-sequence paradigm. Extensive experiments demonstrate our proposed reinforced UI instruction grounding model outperforms the state-of-the-art methods by a clear margin and shows the potential as a generic UI task automation API.
Responsible Task Automation: Empowering Large Language Models as Responsible Task Automators
Jun 02, 2023The recent success of Large Language Models (LLMs) signifies an impressive stride towards artificial general intelligence. They have shown a promising prospect in automatically completing tasks upon user instructions, functioning as brain-like coordinators. The associated risks will be revealed as we delegate an increasing number of tasks to machines for automated completion. A big question emerges: how can we make machines behave responsibly when helping humans automate tasks as personal copilots? In this paper, we explore this question in depth from the perspectives of feasibility, completeness and security. In specific, we present Responsible Task Automation (ResponsibleTA) as a fundamental framework to facilitate responsible collaboration between LLM-based coordinators and executors for task automation with three empowered capabilities: 1) predicting the feasibility of the commands for executors; 2) verifying the completeness of executors; 3) enhancing the security (e.g., the protection of users' privacy). We further propose and compare two paradigms for implementing the first two capabilities. One is to leverage the generic knowledge of LLMs themselves via prompt engineering while the other is to adopt domain-specific learnable models. Moreover, we introduce a local memory mechanism for achieving the third capability. We evaluate our proposed ResponsibleTA on UI task automation and hope it could bring more attentions to ensuring LLMs more responsible in diverse scenarios. The research project homepage is at https://task-automation-research.github.io/responsible_task_automation.