 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-fidelity power flow solver
May 26, 2022
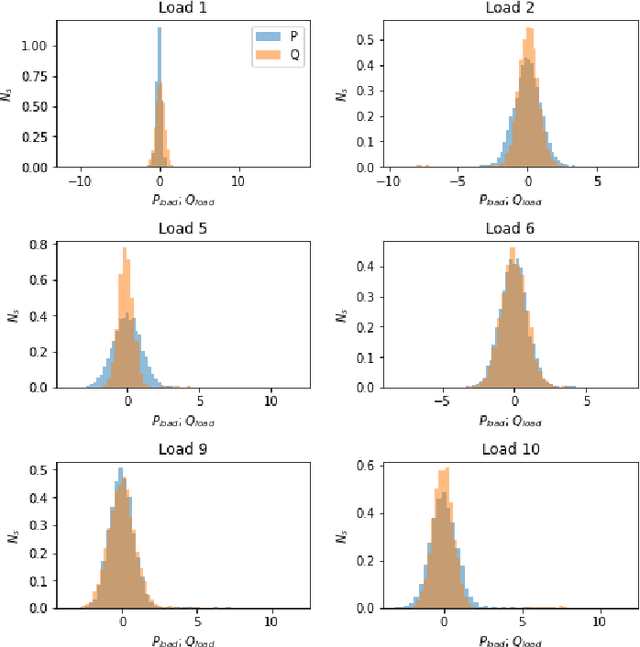
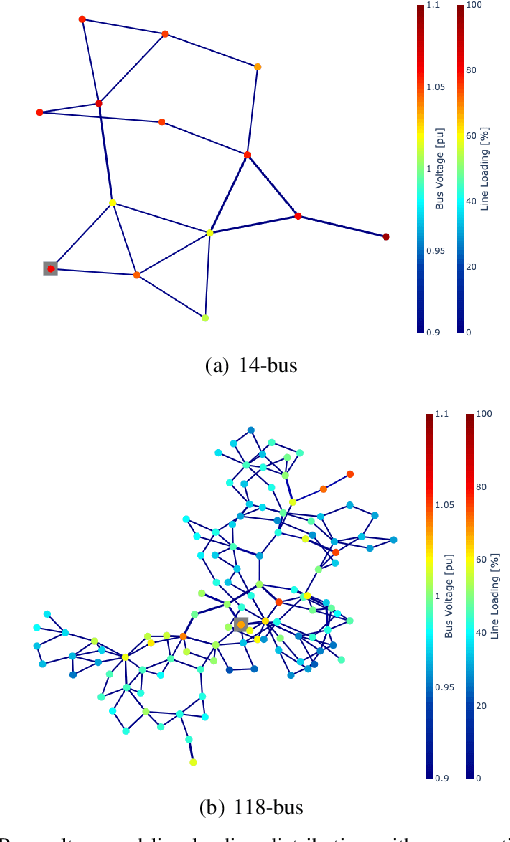
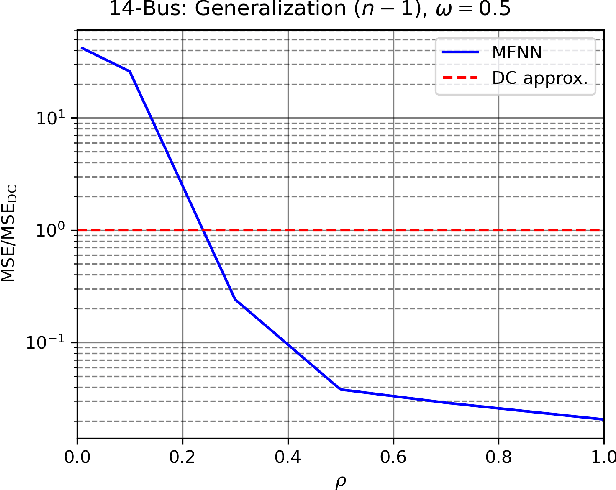
We propose a multi-fidelity neural network (MFNN) tailored for rapid high-dimensional grid power flow simulations and contingency analysis with scarce high-fidelity contingency data. The proposed model comprises two networks -- the first one trained on DC approximation as low-fidelity data and coupled to a high-fidelity neural net trained on both low- and high-fidelity power flow data. Each network features a latent module which parametrizes the model by a discrete grid topology vector for generalization (e.g., $n$ power lines with $k$ disconnections or contingencies, if any), and the targeted high-fidelity output is a weighted sum of linear and nonlinear functions. We tested the model on 14- and 118-bus test cases and evaluated its performance based on the $n-k$ power flow prediction accuracy with respect to imbalanced contingency data and high-to-low-fidelity sample ratio. The results presented herein demonstrate MFNN's potential and its limits with up to two orders of magnitude faster and more accurate power flow solutions than DC approximation.
MLPro: A System for Hosting Crowdsourced Machine Learning Challenges for Open-Ended Research Problems
Apr 04, 2022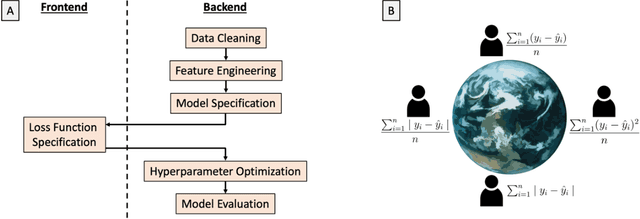

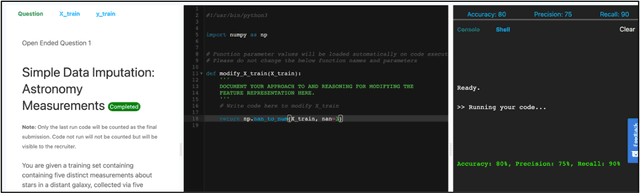
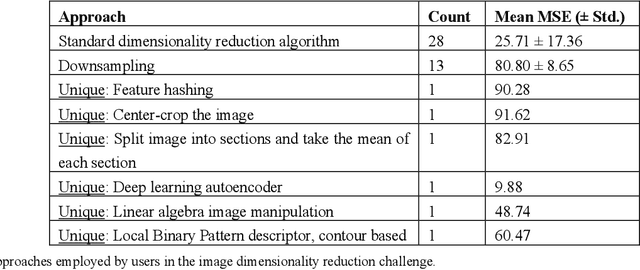
The task of developing a machine learning (ML) model for a particular problem is inherently open-ended, and there is an unbounded set of possible solutions. Steps of the ML development pipeline, such as feature engineering, loss function specification, data imputation, and dimensionality reduction, require the engineer to consider an extensive and often infinite array of possibilities. Successfully identifying high-performing solutions for an unfamiliar dataset or problem requires a mix of mathematical prowess and creativity applied towards inventing and repurposing novel ML methods. Here, we explore the feasibility of hosting crowdsourced ML challenges to facilitate a breadth-first exploration of open-ended research problems, thereby expanding the search space of problem solutions beyond what a typical ML team could viably investigate. We develop MLPro, a system which combines the notion of open-ended ML coding problems with the concept of an automatic online code judging platform. To conduct a pilot evaluation of this paradigm, we crowdsource several open-ended ML challenges to ML and data science practitioners. We describe results from two separate challenges. We find that for sufficiently unconstrained and complex problems, many experts submit similar solutions, but some experts provide unique solutions which outperform the "typical" solution class. We suggest that automated expert crowdsourcing systems such as MLPro have the potential to accelerate ML engineering creativity.
Understanding Mobile GUI: from Pixel-Words to Screen-Sentences
May 25, 2021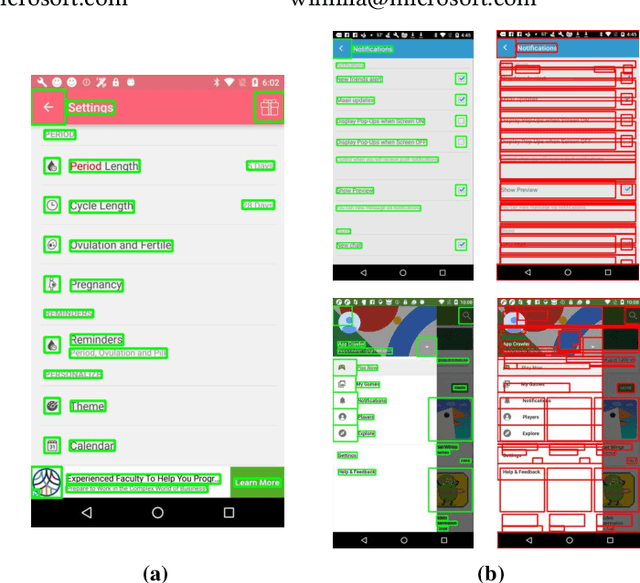
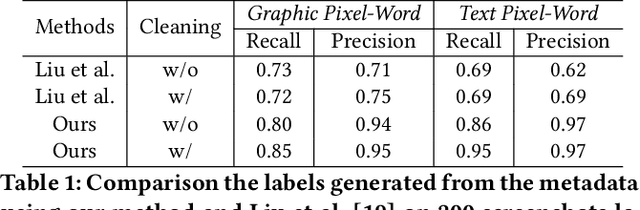
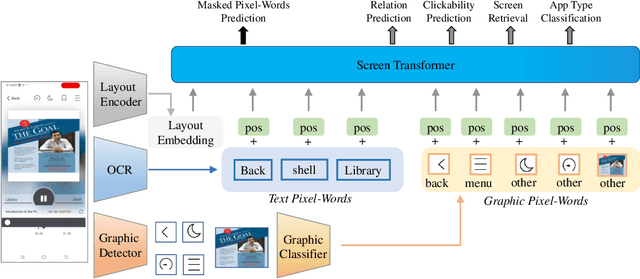
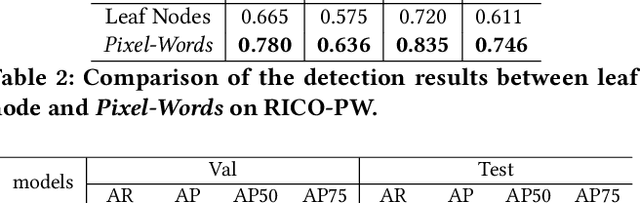
The ubiquity of mobile phones makes mobile GUI understanding an important task. Most previous works in this domain require human-created metadata of screens (e.g. View Hierarchy) during inference, which unfortunately is often not available or reliable enough for GUI understanding. Inspired by the impressive success of Transformers in NLP tasks, targeting for purely vision-based GUI understanding, we extend the concepts of Words/Sentence to Pixel-Words/Screen-Sentence, and propose a mobile GUI understanding architecture: Pixel-Words to Screen-Sentence (PW2SS). In analogy to the individual Words, we define the Pixel-Words as atomic visual components (text and graphic components), which are visually consistent and semantically clear across screenshots of a large variety of design styles. The Pixel-Words extracted from a screenshot are aggregated into Screen-Sentence with a Screen Transformer proposed to model their relations. Since the Pixel-Words are defined as atomic visual components, the ambiguity between their visual appearance and semantics is dramatically reduced. We are able to make use of metadata available in training data to auto-generate high-quality annotations for Pixel-Words. A dataset, RICO-PW, of screenshots with Pixel-Words annotations is built based on the public RICO dataset, which will be released to help to address the lack of high-quality training data in this area. We train a detector to extract Pixel-Words from screenshots on this dataset and achieve metadata-free GUI understanding during inference. We conduct experiments and show that Pixel-Words can be well extracted on RICO-PW and well generalized to a new dataset, P2S-UI, collected by ourselves. The effectiveness of PW2SS is further verified in the GUI understanding tasks including relation prediction, clickability prediction, screen retrieval, and app type classification.