 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in the Differential Classification of Individual Diagnoses from Co-Occurring Autism and ADHD Using Survey Data
Nov 13, 2024



Autism and Attention-Deficit Hyperactivity Disorder (ADHD) are two of the most commonly observed neurodevelopmental conditions in childhood. Providing a specific computational assessment to distinguish between the two can prove difficult and time intensive. Given the high prevalence of their co-occurrence, there is a need for scalable and accessible methods for distinguishing the co-occurrence of autism and ADHD from individual diagnoses. The first step is to identify a core set of features that can serve as the basis for behavioral feature extraction. We trained machine learning models on data from the National Survey of Children's Health to identify behaviors to target as features in automated clinical decision support systems. A model trained on the binary task of distinguishing either developmental delay (autism or ADHD) vs. neither achieved sensitivity >92% and specificity >94%, while a model trained on the 4-way classification task of autism vs. ADHD vs. both vs. none demonstrated >65% sensitivity and >66% specificity. While the performance of the binary model was respectable, the relatively low performance in the differential classification of autism and ADHD highlights the challenges that persist in achieving specificity within clinical decision support tools for developmental delays. Nevertheless, this study demonstrates the potential of applying behavioral questionnaires not traditionally used for clinical purposes towards supporting digital screening assessments for pediatric developmental delays.
Ensemble Modeling of Multiple Physical Indicators to Dynamically Phenotype Autism Spectrum Disorder
Aug 23, 2024



Early detection of autism, a neurodevelopmental disorder marked by social communication challenges, is crucial for timely intervention. Recent advancements have utilized naturalistic home videos captured via the mobile application GuessWhat. Through interactive games played between children and their guardians, GuessWhat has amassed over 3,000 structured videos from 382 children, both diagnosed with and without Autism Spectrum Disorder (ASD). This collection provides a robust dataset for training computer vision models to detect ASD-related phenotypic markers, including variations in emotional expression, eye contact, and head movements. We have developed a protocol to curate high-quality videos from this dataset, forming a comprehensive training set. Utilizing this set, we trained individual LSTM-based models using eye gaze, head positions, and facial landmarks as input features, achieving test AUCs of 86%, 67%, and 78%, respectively. To boost diagnostic accuracy, we applied late fusion techniques to create ensemble models, improving the overall AUC to 90%. This approach also yielded more equitable results across different genders and age groups. Our methodology offers a significant step forward in the early detection of ASD by potentially reducing the reliance on subjective assessments and making early identification more accessibly and equitable.
Evaluating Large Language Models for Anxiety and Depression Classification using Counseling and Psychotherapy Transcripts
Jul 18, 2024


We aim to evaluate the efficacy of traditional machine learning and large language models (LLMs) in classifying anxiety and depression from long conversational transcripts. We fine-tune both established transformer models (BERT, RoBERTa, Longformer) and more recent large models (Mistral-7B), trained a Support Vector Machine with feature engineering, and assessed GPT models through prompting. We observe that state-of-the-art models fail to enhance classification outcomes compared to traditional machine learning methods.
Evaluating Fair Feature Selection in Machine Learning for Healthcare
Apr 01, 2024
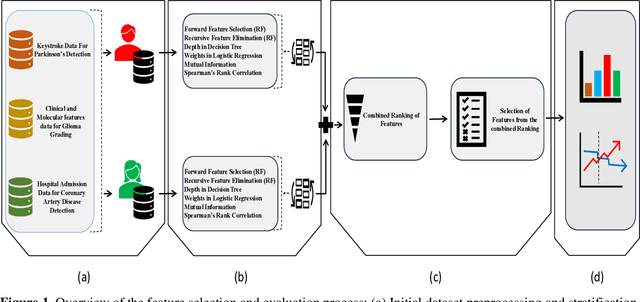
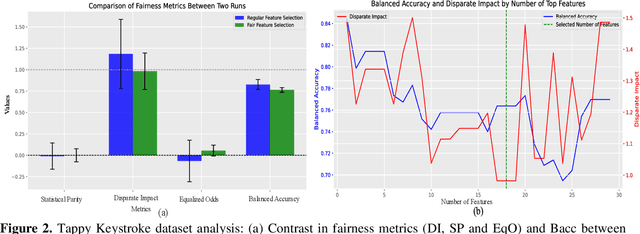
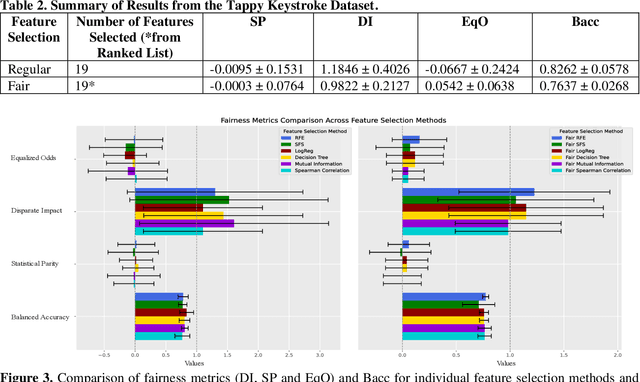
With the universal adoption of machine learning in healthcare, the potential for the automation of societal biases to further exacerbate health disparities poses a significant risk. We explore algorithmic fairness from the perspective of feature selection. Traditional feature selection methods identify features for better decision making by removing resource-intensive, correlated, or non-relevant features but overlook how these factors may differ across subgroups. To counter these issues, we evaluate a fair feature selection method that considers equal importance to all demographic groups. We jointly considered a fairness metric and an error metric within the feature selection process to ensure a balance between minimizing both bias and global classification error. We tested our approach on three publicly available healthcare datasets. On all three datasets, we observed improvements in fairness metrics coupled with a minimal degradation of balanced accuracy. Our approach addresses both distributive and procedural fairness within the fair machine learning context.
TikTokActions: A TikTok-Derived Video Dataset for Human Action Recognition
Feb 14, 2024



The increasing variety and quantity of tagged multimedia content on platforms such as TikTok provides an opportunity to advance computer vision modeling. We have curated a distinctive dataset of 283,582 unique video clips categorized under 386 hashtags relating to modern human actions. We release this dataset as a valuable resource for building domain-specific foundation models for human movement modeling tasks such as action recognition. To validate this dataset, which we name TikTokActions, we perform two sets of experiments. First, we pretrain the state-of-the-art VideoMAEv2 with a ViT-base backbone on TikTokActions subset, and then fine-tune and evaluate on popular datasets such as UCF101 and the HMDB51. We find that the performance of the model pre-trained using our Tik-Tok dataset is comparable to models trained on larger action recognition datasets (95.3% on UCF101 and 53.24% on HMDB51). Furthermore, our investigation into the relationship between pre-training dataset size and fine-tuning performance reveals that beyond a certain threshold, the incremental benefit of larger training sets diminishes. This work introduces a useful TikTok video dataset that is available for public use and provides insights into the marginal benefit of increasing pre-training dataset sizes for video-based foundation models.
A Comparison of Personalized and Generalized Approaches to Emotion Recognition Using Consumer Wearable Devices: Machine Learning Study
Aug 28, 2023



Background: Studies have shown the potential adverse health effects, ranging from headaches to cardiovascular disease, associated with long-term negative emotions and chronic stress. Since many indicators of stress are imperceptible to observers, the early detection and intervention of stress remains a pressing medical need. Physiological signals offer a non-invasive method of monitoring emotions and are easily collected by smartwatches. Existing research primarily focuses on developing generalized machine learning-based models for emotion classification. Objective: We aim to study the differences between personalized and generalized machine learning models for three-class emotion classification (neutral, stress, and amusement) using wearable biosignal data. Methods: We developed a convolutional encoder for the three-class emotion classification problem using data from WESAD, a multimodal dataset with physiological signals for 15 subjects. We compared the results between a subject-exclusive generalized, subject-inclusive generalized, and personalized model. Results: For the three-class classification problem, our personalized model achieved an average accuracy of 95.06% and F1-score of 91.71, our subject-inclusive generalized model achieved an average accuracy of 66.95% and F1-score of 42.50, and our subject-exclusive generalized model achieved an average accuracy of 67.65% and F1-score of 43.05. Conclusions: Our results emphasize the need for increased research in personalized emotion recognition models given that they outperform generalized models in certain contexts. We also demonstrate that personalized machine learning models for emotion classification are viable and can achieve high performance.
Addressing Racial Bias in Facial Emotion Recognition
Aug 09, 2023Fairness in deep learning models trained with high-dimensional inputs and subjective labels remains a complex and understudied area. Facial emotion recognition, a domain where datasets are often racially imbalanced, can lead to models that yield disparate outcomes across racial groups. This study focuses on analyzing racial bias by sub-sampling training sets with varied racial distributions and assessing test performance across these simulations. Our findings indicate that smaller datasets with posed faces improve on both fairness and performance metrics as the simulations approach racial balance. Notably, the F1-score increases by $27.2\%$ points, and demographic parity increases by $15.7\%$ points on average across the simulations. However, in larger datasets with greater facial variation, fairness metrics generally remain constant, suggesting that racial balance by itself is insufficient to achieve parity in test performance across different racial groups.
Personalization of Stress Mobile Sensing using Self-Supervised Learning
Aug 04, 2023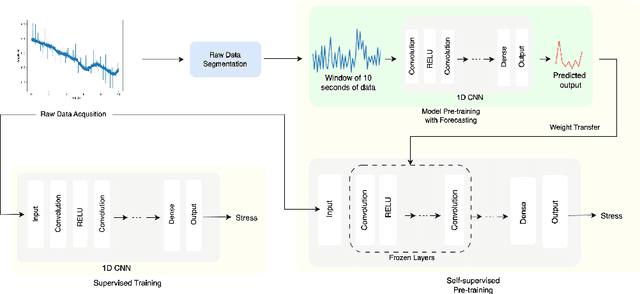
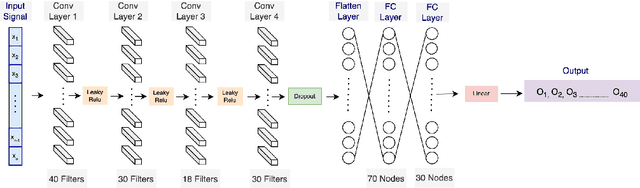
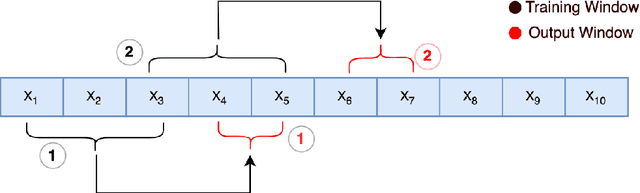
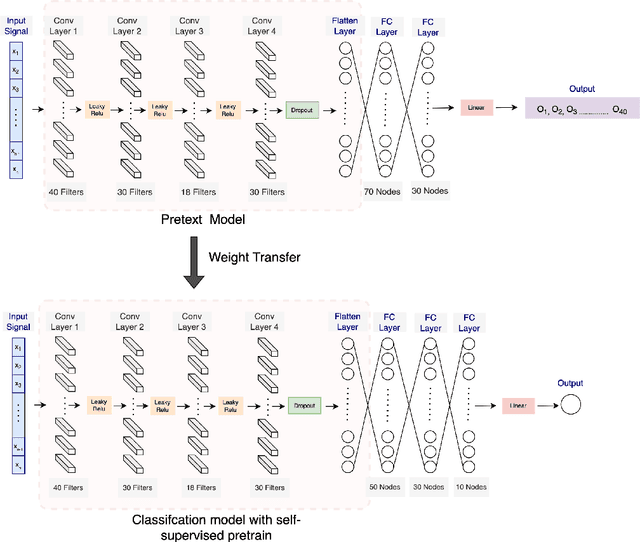
Stress is widely recognized as a major contributor to a variety of health issues. Stress prediction using biosignal data recorded by wearables is a key area of study in mobile sensing research because real-time stress prediction can enable digital interventions to immediately react at the onset of stress, helping to avoid many psychological and physiological symptoms such as heart rhythm irregularities. Electrodermal activity (EDA) is often used to measure stress. However, major challenges with the prediction of stress using machine learning include the subjectivity and sparseness of the labels, a large feature space, relatively few labels, and a complex nonlinear and subjective relationship between the features and outcomes. To tackle these issues, we examine the use of model personalization: training a separate stress prediction model for each user. To allow the neural network to learn the temporal dynamics of each individual's baseline biosignal patterns, thus enabling personalization with very few labels, we pre-train a 1-dimensional convolutional neural network (CNN) using self-supervised learning (SSL). We evaluate our method using the Wearable Stress and Affect prediction (WESAD) dataset. We fine-tune the pre-trained networks to the stress prediction task and compare against equivalent models without any self-supervised pre-training. We discover that embeddings learned using our pre-training method outperform supervised baselines with significantly fewer labeled data points: the models trained with SSL require less than 30% of the labels to reach equivalent performance without personalized SSL. This personalized learning method can enable precision health systems which are tailored to each subject and require few annotations by the end user, thus allowing for the mobile sensing of increasingly complex, heterogeneous, and subjective outcomes such as stress.
Self-Supervised Learning for Audio-Based Emotion Recognition
Jul 23, 2023



Emotion recognition models using audio input data can enable the development of interactive systems with applications in mental healthcare, marketing, gaming, and social media analysis. While the field of affective computing using audio data is rich, a major barrier to achieve consistently high-performance models is the paucity of available training labels. Self-supervised learning (SSL) is a family of methods which can learn despite a scarcity of supervised labels by predicting properties of the data itself. To understand the utility of self-supervised learning for audio-based emotion recognition, we have applied self-supervised learning pre-training to the classification of emotions from the CMU- MOSEI's acoustic modality. Unlike prior papers that have experimented with raw acoustic data, our technique has been applied to encoded acoustic data. Our model is first pretrained to uncover the randomly-masked timestamps of the acoustic data. The pre-trained model is then fine-tuned using a small sample of annotated data. The performance of the final model is then evaluated via several evaluation metrics against a baseline deep learning model with an identical backbone architecture. We find that self-supervised learning consistently improves the performance of the model across all metrics. This work shows the utility of self-supervised learning for affective computing, demonstrating that self-supervised learning is most useful when the number of training examples is small, and that the effect is most pronounced for emotions which are easier to classify such as happy, sad and anger. This work further demonstrates that self-supervised learning works when applied to embedded feature representations rather than the traditional approach of pre-training on the raw input space.
Personalized Prediction of Recurrent Stress Events Using Self-Supervised Learning on Multimodal Time-Series Data
Jul 07, 2023



Chronic stress can significantly affect physical and mental health. The advent of wearable technology allows for the tracking of physiological signals, potentially leading to innovative stress prediction and intervention methods. However, challenges such as label scarcity and data heterogeneity render stress prediction difficult in practice. To counter these issues, we have developed a multimodal personalized stress prediction system using wearable biosignal data. We employ self-supervised learning (SSL) to pre-train the models on each subject's data, allowing the models to learn the baseline dynamics of the participant's biosignals prior to fine-tuning the stress prediction task. We test our model on the Wearable Stress and Affect Detection (WESAD) dataset, demonstrating that our SSL models outperform non-SSL models while utilizing less than 5% of the annotations. These results suggest that our approach can personalize stress prediction to each user with minimal annotations. This paradigm has the potential to enable personalized prediction of a variety of recurring health events using complex multimodal data streams.