 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIESTA: Fisher Information-based Efficient Selective Test-time Adaptation
Mar 29, 2025Robust facial expression recognition in unconstrained, "in-the-wild" environments remains challenging due to significant domain shifts between training and testing distributions. Test-time adaptation (TTA) offers a promising solution by adapting pre-trained models during inference without requiring labeled test data. However, existing TTA approaches typically rely on manually selecting which parameters to update, potentially leading to suboptimal adaptation and high computational costs. This paper introduces a novel Fisher-driven selective adaptation framework that dynamically identifies and updates only the most critical model parameters based on their importance as quantified by Fisher information. By integrating this principled parameter selection approach with temporal consistency constraints, our method enables efficient and effective adaptation specifically tailored for video-based facial expression recognition. Experiments on the challenging AffWild2 benchmark demonstrate that our approach significantly outperforms existing TTA methods, achieving a 7.7% improvement in F1 score over the base model while adapting only 22,000 parameters-more than 20 times fewer than comparable methods. Our ablation studies further reveal that parameter importance can be effectively estimated from minimal data, with sampling just 1-3 frames sufficient for substantial performance gains. The proposed approach not only enhances recognition accuracy but also dramatically reduces computational overhead, making test-time adaptation more practical for real-world affective computing applications.
Ensemble Modeling of Multiple Physical Indicators to Dynamically Phenotype Autism Spectrum Disorder
Aug 23, 2024



Early detection of autism, a neurodevelopmental disorder marked by social communication challenges, is crucial for timely intervention. Recent advancements have utilized naturalistic home videos captured via the mobile application GuessWhat. Through interactive games played between children and their guardians, GuessWhat has amassed over 3,000 structured videos from 382 children, both diagnosed with and without Autism Spectrum Disorder (ASD). This collection provides a robust dataset for training computer vision models to detect ASD-related phenotypic markers, including variations in emotional expression, eye contact, and head movements. We have developed a protocol to curate high-quality videos from this dataset, forming a comprehensive training set. Utilizing this set, we trained individual LSTM-based models using eye gaze, head positions, and facial landmarks as input features, achieving test AUCs of 86%, 67%, and 78%, respectively. To boost diagnostic accuracy, we applied late fusion techniques to create ensemble models, improving the overall AUC to 90%. This approach also yielded more equitable results across different genders and age groups. Our methodology offers a significant step forward in the early detection of ASD by potentially reducing the reliance on subjective assessments and making early identification more accessibly and equitable.
TikTokActions: A TikTok-Derived Video Dataset for Human Action Recognition
Feb 14, 2024



The increasing variety and quantity of tagged multimedia content on platforms such as TikTok provides an opportunity to advance computer vision modeling. We have curated a distinctive dataset of 283,582 unique video clips categorized under 386 hashtags relating to modern human actions. We release this dataset as a valuable resource for building domain-specific foundation models for human movement modeling tasks such as action recognition. To validate this dataset, which we name TikTokActions, we perform two sets of experiments. First, we pretrain the state-of-the-art VideoMAEv2 with a ViT-base backbone on TikTokActions subset, and then fine-tune and evaluate on popular datasets such as UCF101 and the HMDB51. We find that the performance of the model pre-trained using our Tik-Tok dataset is comparable to models trained on larger action recognition datasets (95.3% on UCF101 and 53.24% on HMDB51). Furthermore, our investigation into the relationship between pre-training dataset size and fine-tuning performance reveals that beyond a certain threshold, the incremental benefit of larger training sets diminishes. This work introduces a useful TikTok video dataset that is available for public use and provides insights into the marginal benefit of increasing pre-training dataset sizes for video-based foundation models.
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023



In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
Computer Vision Estimation of Emotion Reaction Intensity in the Wild
Mar 19, 2023

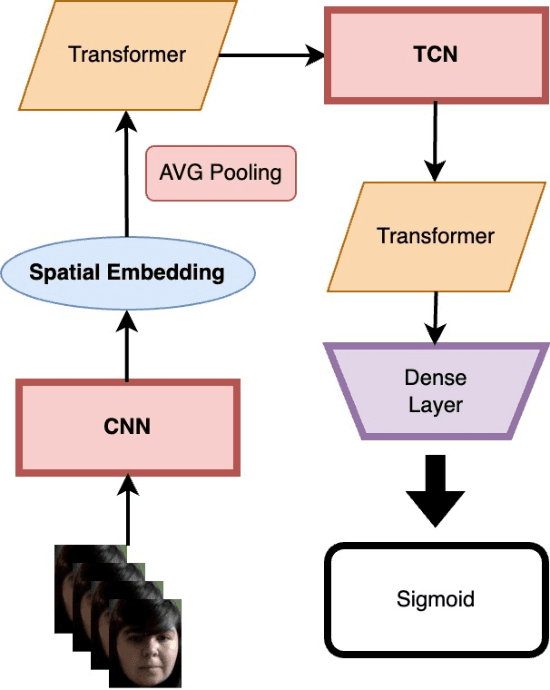
Emotions play an essential role in human communication. Developing computer vision models for automatic recognition of emotion expression can aid in a variety of domains, including robotics, digital behavioral healthcare, and media analytics. There are three types of emotional representations which are traditionally modeled in affective computing research: Action Units, Valence Arousal (VA), and Categorical Emotions. As part of an effort to move beyond these representations towards more fine-grained labels, we describe our submission to the newly introduced Emotional Reaction Intensity (ERI) Estimation challenge in the 5th competition for Affective Behavior Analysis in-the-Wild (ABAW). We developed four deep neural networks trained in the visual domain and a multimodal model trained with both visual and audio features to predict emotion reaction intensity. Our best performing model on the Hume-Reaction dataset achieved an average Pearson correlation coefficient of 0.4080 on the test set using a pre-trained ResNet50 model. This work provides a first step towards the development of production-grade models which predict emotion reaction intensities rather than discrete emotion categories.
Activity Recognition with Moving Cameras and Few Training Examples: Applications for Detection of Autism-Related Headbanging
Jan 10, 2021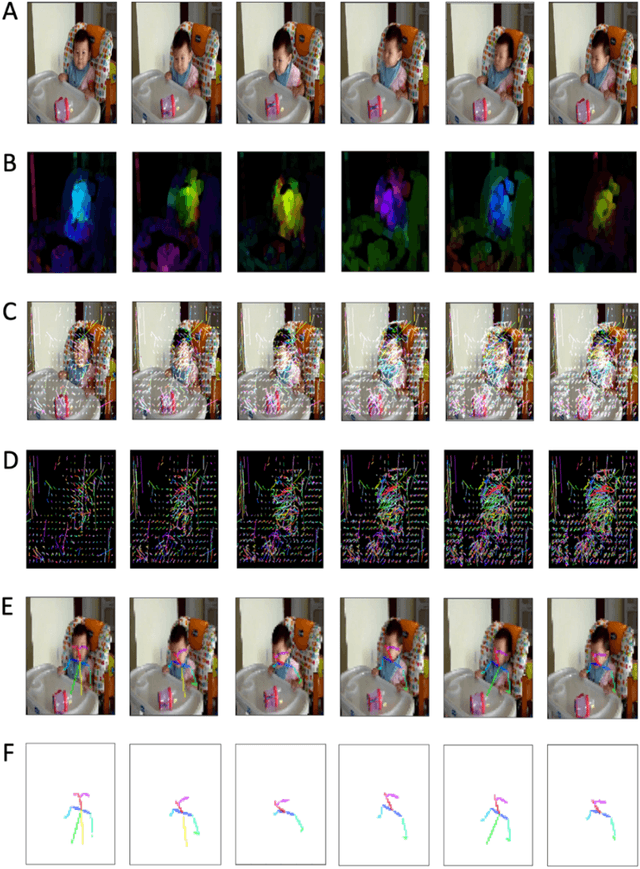

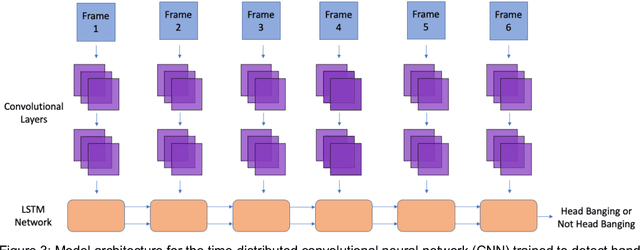
Activity recognition computer vision algorithms can be used to detect the presence of autism-related behaviors, including what are termed "restricted and repetitive behaviors", or stimming, by diagnostic instruments. The limited data that exist in this domain are usually recorded with a handheld camera which can be shaky or even moving, posing a challenge for traditional feature representation approaches for activity detection which mistakenly capture the camera's motion as a feature. To address these issues, we first document the advantages and limitations of current feature representation techniques for activity recognition when applied to head banging detection. We then propose a feature representation consisting exclusively of head pose keypoints. We create a computer vision classifier for detecting head banging in home videos using a time-distributed convolutional neural network (CNN) in which a single CNN extracts features from each frame in the input sequence, and these extracted features are fed as input to a long short-term memory (LSTM) network. On the binary task of predicting head banging and no head banging within videos from the Self Stimulatory Behaviour Dataset (SSBD), we reach a mean F1-score of 90.77% using 3-fold cross validation (with individual fold F1-scores of 83.3%, 89.0%, and 100.0%) when ensuring that no child who appeared in the train set was in the test set for all folds. This work documents a successful technique for training a computer vision classifier which can detect human motion with few training examples and even when the camera recording the source clips is unstable. The general methods described here can be applied by designers and developers of interactive systems towards other human motion and pose classification problems used in mobile and ubiquitous interactive systems.
Using Crowdsourcing to Train Facial Emotion Machine Learning Models with Ambiguous Labels
Jan 10, 2021
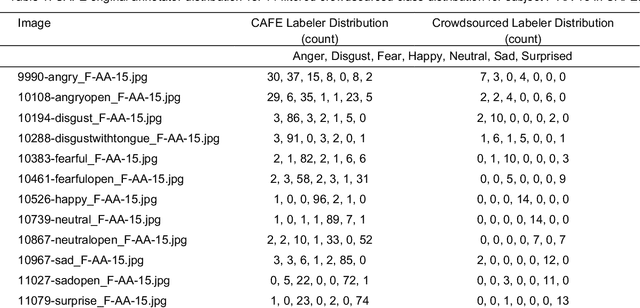
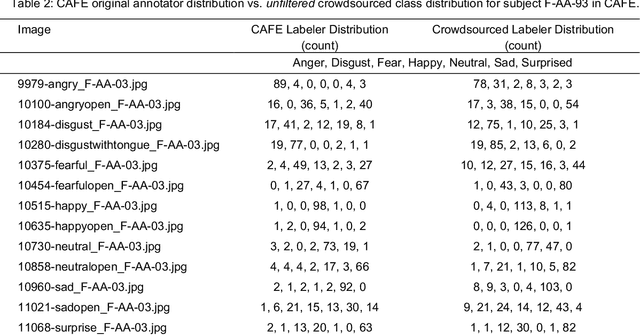
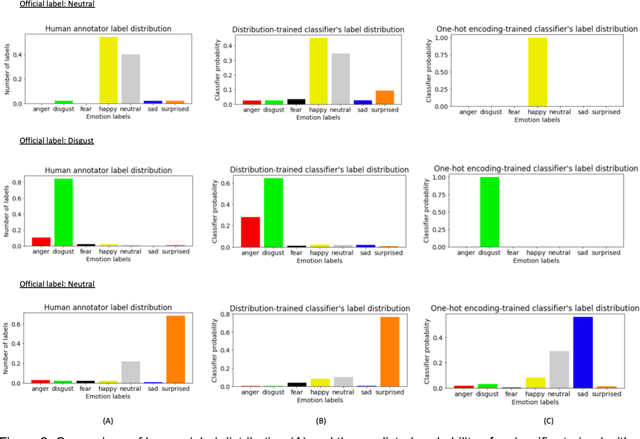
Current emotion detection classifiers predict discrete emotions. However, literature in psychology has documented that compound and ambiguous facial expressions are often evoked by humans. As a stride towards development of machine learning models that more accurately reflect compound and ambiguous emotions, we replace traditional one-hot encoded label representations with a crowd's distribution of labels. We center our study on the Child Affective Facial Expression (CAFE) dataset, a gold standard dataset of pediatric facial expressions which includes 100 human labels per image. We first acquire crowdsourced labels for 207 emotions from CAFE and demonstrate that the consensus labels from the crowd tend to match the consensus from the original CAFE raters, validating the utility of crowdsourcing. We then train two versions of a ResNet-152 classifier on CAFE images with two types of labels (1) traditional one-hot encoding and (2) vector labels representing the crowd distribution of responses. We compare the resulting output distributions of the two classifiers. While the traditional F1-score for the one-hot encoding classifier is much higher (94.33% vs. 78.68%), the output probability vector of the crowd-trained classifier much more closely resembles the distribution of human labels (t=3.2827, p=0.0014). For many applications of affective computing, reporting an emotion probability distribution that more closely resembles human interpretation can be more important than traditional machine learning metrics. This work is a first step for engineers of interactive systems to account for machine learning cases with ambiguous classes and we hope it will generate a discussion about machine learning with ambiguous labels and leveraging crowdsourcing as a potential solution.