 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivity Recognition with Moving Cameras and Few Training Examples: Applications for Detection of Autism-Related Headbanging
Jan 10, 2021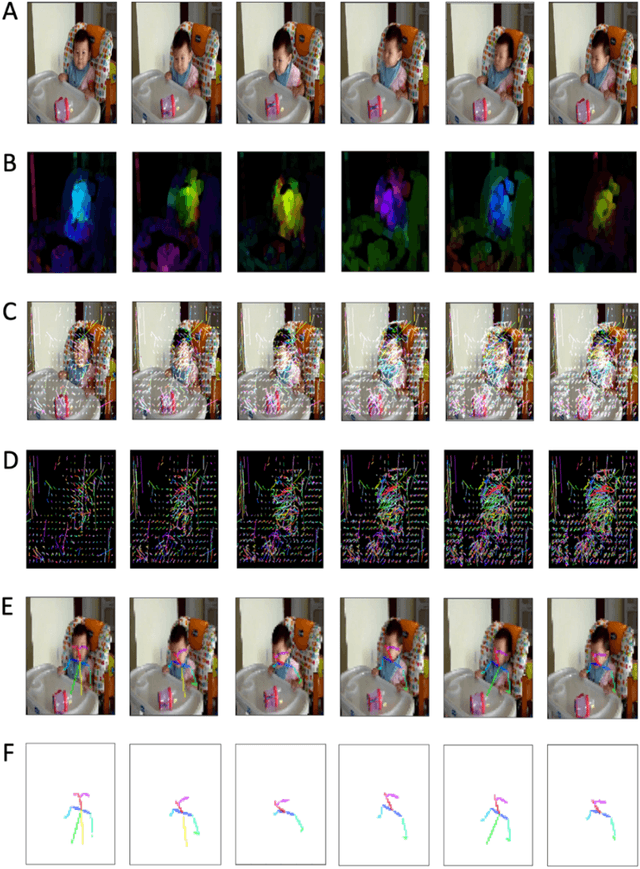

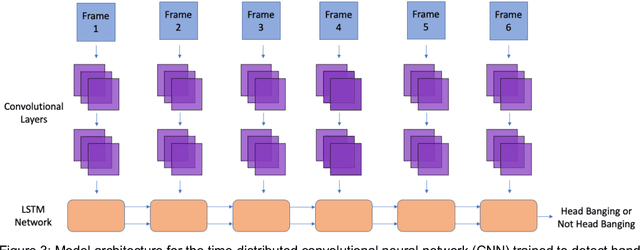
Activity recognition computer vision algorithms can be used to detect the presence of autism-related behaviors, including what are termed "restricted and repetitive behaviors", or stimming, by diagnostic instruments. The limited data that exist in this domain are usually recorded with a handheld camera which can be shaky or even moving, posing a challenge for traditional feature representation approaches for activity detection which mistakenly capture the camera's motion as a feature. To address these issues, we first document the advantages and limitations of current feature representation techniques for activity recognition when applied to head banging detection. We then propose a feature representation consisting exclusively of head pose keypoints. We create a computer vision classifier for detecting head banging in home videos using a time-distributed convolutional neural network (CNN) in which a single CNN extracts features from each frame in the input sequence, and these extracted features are fed as input to a long short-term memory (LSTM) network. On the binary task of predicting head banging and no head banging within videos from the Self Stimulatory Behaviour Dataset (SSBD), we reach a mean F1-score of 90.77% using 3-fold cross validation (with individual fold F1-scores of 83.3%, 89.0%, and 100.0%) when ensuring that no child who appeared in the train set was in the test set for all folds. This work documents a successful technique for training a computer vision classifier which can detect human motion with few training examples and even when the camera recording the source clips is unstable. The general methods described here can be applied by designers and developers of interactive systems towards other human motion and pose classification problems used in mobile and ubiquitous interactive systems.
Using Crowdsourcing to Train Facial Emotion Machine Learning Models with Ambiguous Labels
Jan 10, 2021
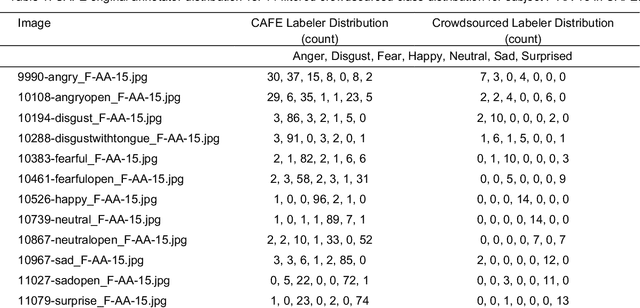
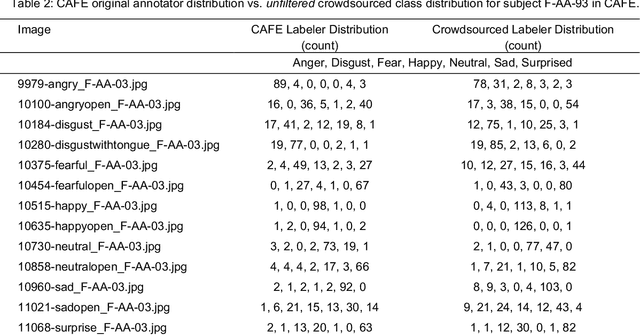
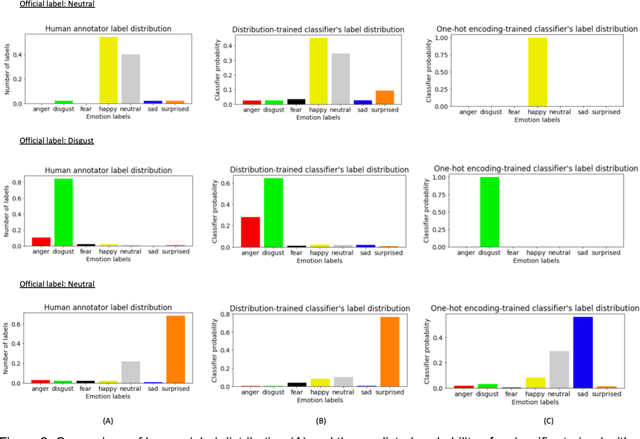
Current emotion detection classifiers predict discrete emotions. However, literature in psychology has documented that compound and ambiguous facial expressions are often evoked by humans. As a stride towards development of machine learning models that more accurately reflect compound and ambiguous emotions, we replace traditional one-hot encoded label representations with a crowd's distribution of labels. We center our study on the Child Affective Facial Expression (CAFE) dataset, a gold standard dataset of pediatric facial expressions which includes 100 human labels per image. We first acquire crowdsourced labels for 207 emotions from CAFE and demonstrate that the consensus labels from the crowd tend to match the consensus from the original CAFE raters, validating the utility of crowdsourcing. We then train two versions of a ResNet-152 classifier on CAFE images with two types of labels (1) traditional one-hot encoding and (2) vector labels representing the crowd distribution of responses. We compare the resulting output distributions of the two classifiers. While the traditional F1-score for the one-hot encoding classifier is much higher (94.33% vs. 78.68%), the output probability vector of the crowd-trained classifier much more closely resembles the distribution of human labels (t=3.2827, p=0.0014). For many applications of affective computing, reporting an emotion probability distribution that more closely resembles human interpretation can be more important than traditional machine learning metrics. This work is a first step for engineers of interactive systems to account for machine learning cases with ambiguous classes and we hope it will generate a discussion about machine learning with ambiguous labels and leveraging crowdsourcing as a potential solution.
Training an Emotion Detection Classifier using Frames from a Mobile Therapeutic Game for Children with Developmental Disorders
Dec 16, 2020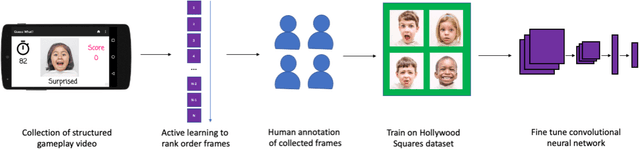
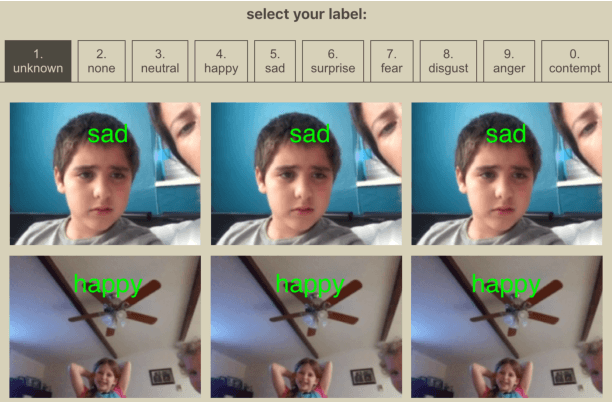

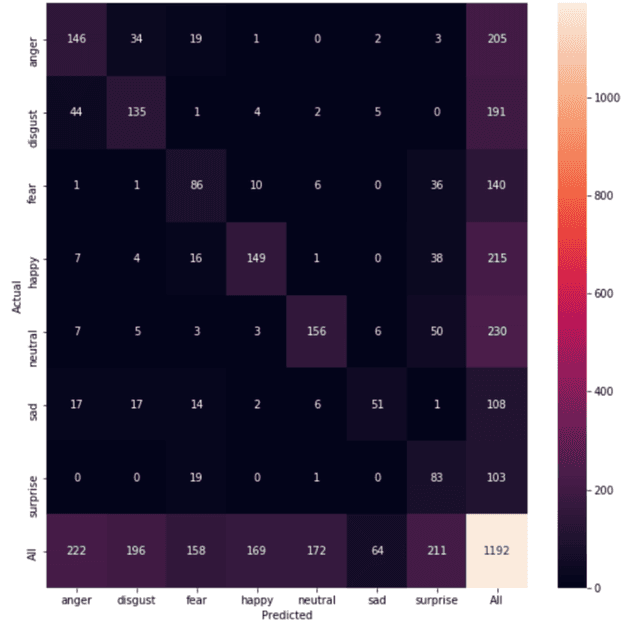
Automated emotion classification could aid those who struggle to recognize emotion, including children with developmental behavioral conditions such as autism. However, most computer vision emotion models are trained on adult affect and therefore underperform on child faces. In this study, we designed a strategy to gamify the collection and the labeling of child affect data in an effort to boost the performance of automatic child emotion detection to a level closer to what will be needed for translational digital healthcare. We leveraged our therapeutic smartphone game, GuessWhat, which was designed in large part for children with developmental and behavioral conditions, to gamify the secure collection of video data of children expressing a variety of emotions prompted by the game. Through a secure web interface gamifying the human labeling effort, we gathered and labeled 2,155 videos, 39,968 emotion frames, and 106,001 labels on all images. With this drastically expanded pediatric emotion centric database (>30x larger than existing public pediatric affect datasets), we trained a pediatric emotion classification convolutional neural network (CNN) classifier of happy, sad, surprised, fearful, angry, disgust, and neutral expressions in children. The classifier achieved 66.9% balanced accuracy and 67.4% F1-score on the entirety of CAFE as well as 79.1% balanced accuracy and 78.0% F1-score on CAFE Subset A, a subset containing at least 60% human agreement on emotions labels. This performance is at least 10% higher than all previously published classifiers, the best of which reached 56.% balanced accuracy even when combining "anger" and "disgust" into a single class. This work validates that mobile games designed for pediatric therapies can generate high volumes of domain-relevant datasets to train state of the art classifiers to perform tasks highly relevant to precision health efforts.