 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Modeling of Multiple Physical Indicators to Dynamically Phenotype Autism Spectrum Disorder
Aug 23, 2024



Early detection of autism, a neurodevelopmental disorder marked by social communication challenges, is crucial for timely intervention. Recent advancements have utilized naturalistic home videos captured via the mobile application GuessWhat. Through interactive games played between children and their guardians, GuessWhat has amassed over 3,000 structured videos from 382 children, both diagnosed with and without Autism Spectrum Disorder (ASD). This collection provides a robust dataset for training computer vision models to detect ASD-related phenotypic markers, including variations in emotional expression, eye contact, and head movements. We have developed a protocol to curate high-quality videos from this dataset, forming a comprehensive training set. Utilizing this set, we trained individual LSTM-based models using eye gaze, head positions, and facial landmarks as input features, achieving test AUCs of 86%, 67%, and 78%, respectively. To boost diagnostic accuracy, we applied late fusion techniques to create ensemble models, improving the overall AUC to 90%. This approach also yielded more equitable results across different genders and age groups. Our methodology offers a significant step forward in the early detection of ASD by potentially reducing the reliance on subjective assessments and making early identification more accessibly and equitable.
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022
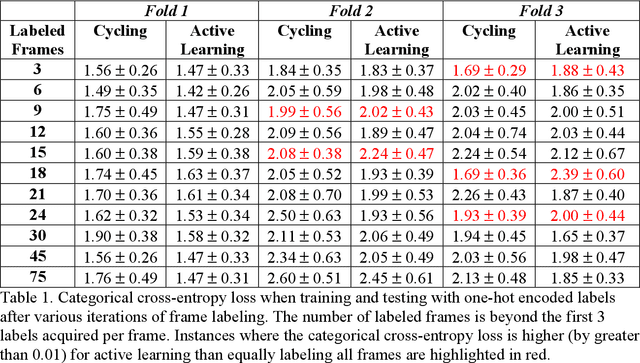
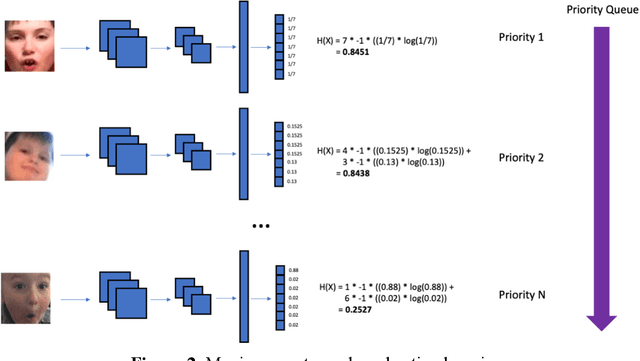
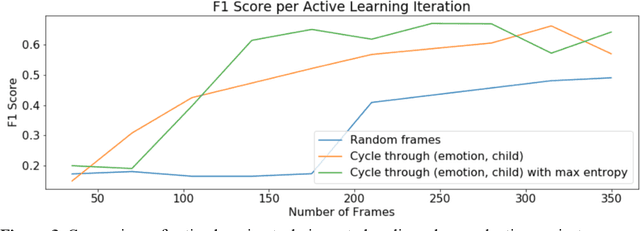
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
Classifying Autism from Crowdsourced Semi-Structured Speech Recordings: A Machine Learning Approach
Jan 04, 2022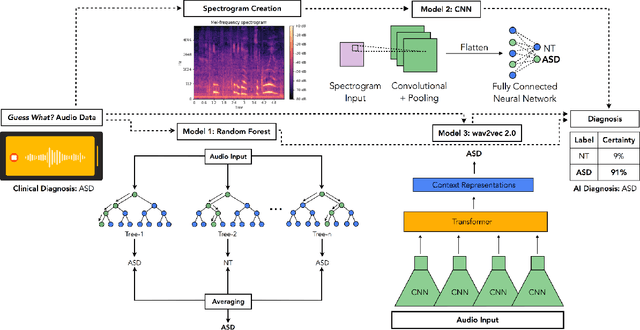

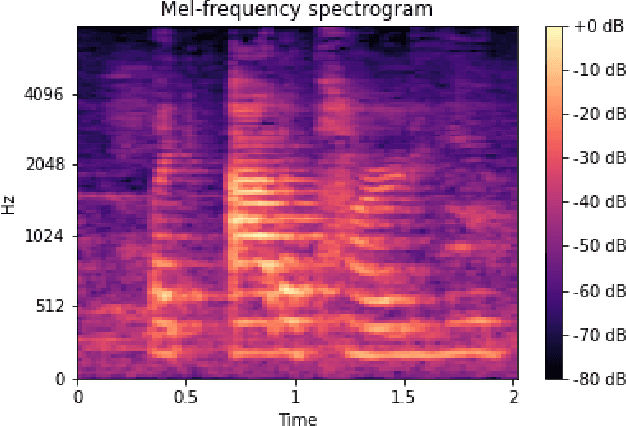
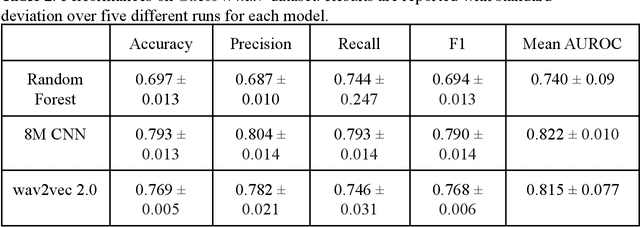
Autism spectrum disorder (ASD) is a neurodevelopmental disorder which results in altered behavior, social development, and communication patterns. In past years, autism prevalence has tripled, with 1 in 54 children now affected. Given that traditional diagnosis is a lengthy, labor-intensive process, significant attention has been given to developing systems that automatically screen for autism. Prosody abnormalities are among the clearest signs of autism, with affected children displaying speech idiosyncrasies including echolalia, monotonous intonation, atypical pitch, and irregular linguistic stress patterns. In this work, we present a suite of machine learning approaches to detect autism in self-recorded speech audio captured from autistic and neurotypical (NT) children in home environments. We consider three methods to detect autism in child speech: first, Random Forests trained on extracted audio features (including Mel-frequency cepstral coefficients); second, convolutional neural networks (CNNs) trained on spectrograms; and third, fine-tuned wav2vec 2.0--a state-of-the-art Transformer-based ASR model. We train our classifiers on our novel dataset of cellphone-recorded child speech audio curated from Stanford's Guess What? mobile game, an app designed to crowdsource videos of autistic and neurotypical children in a natural home environment. The Random Forest classifier achieves 70% accuracy, the fine-tuned wav2vec 2.0 model achieves 77% accuracy, and the CNN achieves 79% accuracy when classifying children's audio as either ASD or NT. Our models were able to predict autism status when training on a varied selection of home audio clips with inconsistent recording quality, which may be more generalizable to real world conditions. These results demonstrate that machine learning methods offer promise in detecting autism automatically from speech without specialized equipment.
Training an Emotion Detection Classifier using Frames from a Mobile Therapeutic Game for Children with Developmental Disorders
Dec 16, 2020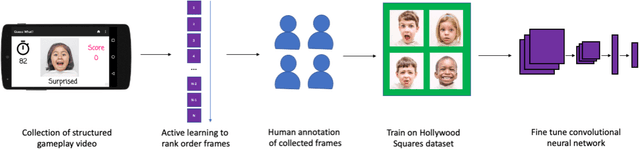
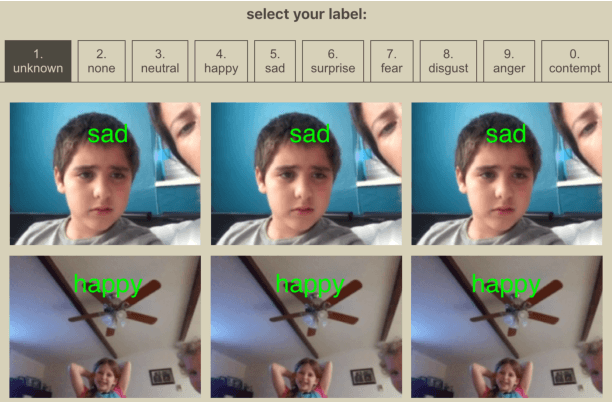

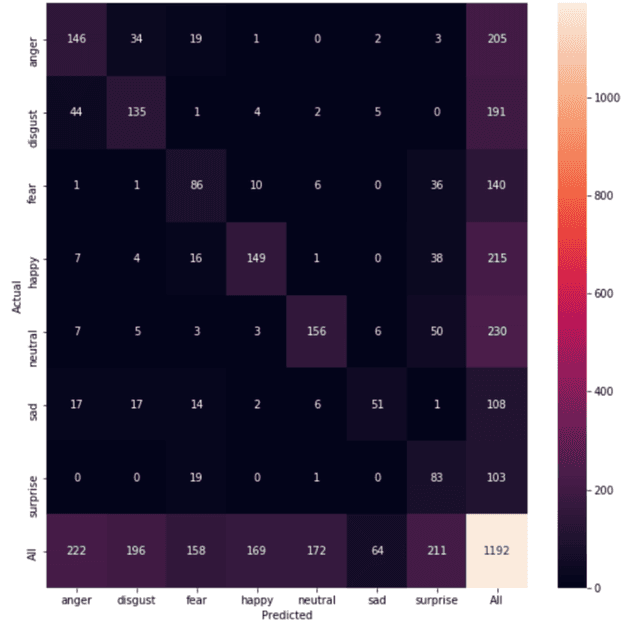
Automated emotion classification could aid those who struggle to recognize emotion, including children with developmental behavioral conditions such as autism. However, most computer vision emotion models are trained on adult affect and therefore underperform on child faces. In this study, we designed a strategy to gamify the collection and the labeling of child affect data in an effort to boost the performance of automatic child emotion detection to a level closer to what will be needed for translational digital healthcare. We leveraged our therapeutic smartphone game, GuessWhat, which was designed in large part for children with developmental and behavioral conditions, to gamify the secure collection of video data of children expressing a variety of emotions prompted by the game. Through a secure web interface gamifying the human labeling effort, we gathered and labeled 2,155 videos, 39,968 emotion frames, and 106,001 labels on all images. With this drastically expanded pediatric emotion centric database (>30x larger than existing public pediatric affect datasets), we trained a pediatric emotion classification convolutional neural network (CNN) classifier of happy, sad, surprised, fearful, angry, disgust, and neutral expressions in children. The classifier achieved 66.9% balanced accuracy and 67.4% F1-score on the entirety of CAFE as well as 79.1% balanced accuracy and 78.0% F1-score on CAFE Subset A, a subset containing at least 60% human agreement on emotions labels. This performance is at least 10% higher than all previously published classifiers, the best of which reached 56.% balanced accuracy even when combining "anger" and "disgust" into a single class. This work validates that mobile games designed for pediatric therapies can generate high volumes of domain-relevant datasets to train state of the art classifiers to perform tasks highly relevant to precision health efforts.