 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Autism from Crowdsourced Semi-Structured Speech Recordings: A Machine Learning Approach
Jan 04, 2022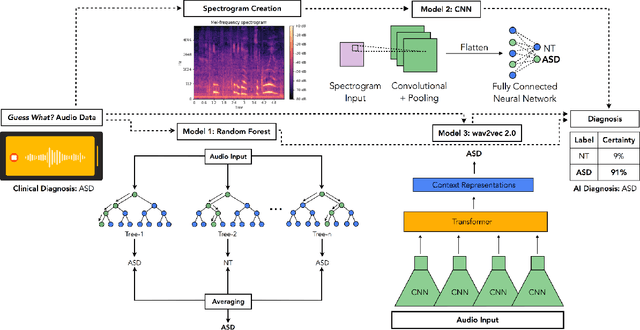

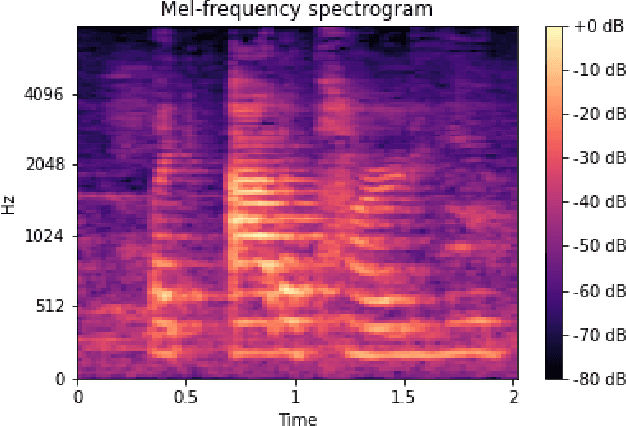
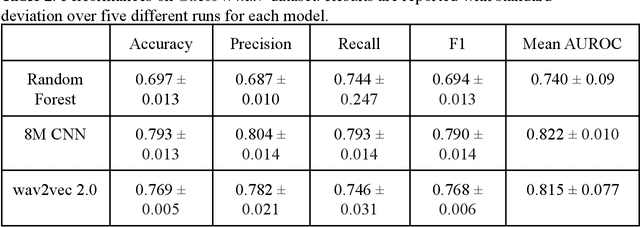
Autism spectrum disorder (ASD) is a neurodevelopmental disorder which results in altered behavior, social development, and communication patterns. In past years, autism prevalence has tripled, with 1 in 54 children now affected. Given that traditional diagnosis is a lengthy, labor-intensive process, significant attention has been given to developing systems that automatically screen for autism. Prosody abnormalities are among the clearest signs of autism, with affected children displaying speech idiosyncrasies including echolalia, monotonous intonation, atypical pitch, and irregular linguistic stress patterns. In this work, we present a suite of machine learning approaches to detect autism in self-recorded speech audio captured from autistic and neurotypical (NT) children in home environments. We consider three methods to detect autism in child speech: first, Random Forests trained on extracted audio features (including Mel-frequency cepstral coefficients); second, convolutional neural networks (CNNs) trained on spectrograms; and third, fine-tuned wav2vec 2.0--a state-of-the-art Transformer-based ASR model. We train our classifiers on our novel dataset of cellphone-recorded child speech audio curated from Stanford's Guess What? mobile game, an app designed to crowdsource videos of autistic and neurotypical children in a natural home environment. The Random Forest classifier achieves 70% accuracy, the fine-tuned wav2vec 2.0 model achieves 77% accuracy, and the CNN achieves 79% accuracy when classifying children's audio as either ASD or NT. Our models were able to predict autism status when training on a varied selection of home audio clips with inconsistent recording quality, which may be more generalizable to real world conditions. These results demonstrate that machine learning methods offer promise in detecting autism automatically from speech without specialized equipment.
Activity Recognition for Autism Diagnosis
Aug 25, 2021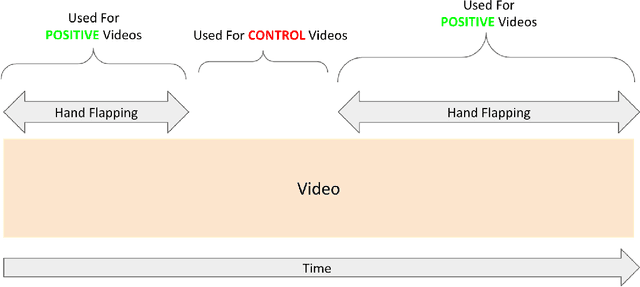
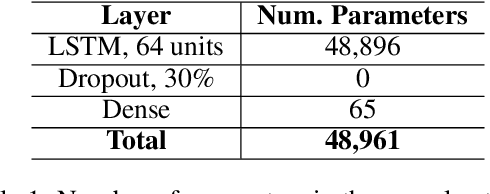


A formal autism diagnosis is an inefficient and lengthy process. Families often have to wait years before receiving a diagnosis for their child; some may not receive one at all due to this delay. One approach to this problem is to use digital technologies to detect the presence of behaviors related to autism, which in aggregate may lead to remote and automated diagnostics. One of the strongest indicators of autism is stimming, which is a set of repetitive, self-stimulatory behaviors such as hand flapping, headbanging, and spinning. Using computer vision to detect hand flapping is especially difficult due to the sparsity of public training data in this space and excessive shakiness and motion in such data. Our work demonstrates a novel method that overcomes these issues: we use hand landmark detection over time as a feature representation which is then fed into a Long Short-Term Memory (LSTM) model. We achieve a validation accuracy and F1 Score of about 72% on detecting whether videos from the Self-Stimulatory Behaviour Dataset (SSBD) contain hand flapping or not. Our best model also predicts accurately on external videos we recorded of ourselves outside of the dataset it was trained on. This model uses less than 26,000 parameters, providing promise for fast deployment into ubiquitous and wearable digital settings for a remote autism diagnosis.
Using Crowdsourcing to Train Facial Emotion Machine Learning Models with Ambiguous Labels
Jan 10, 2021
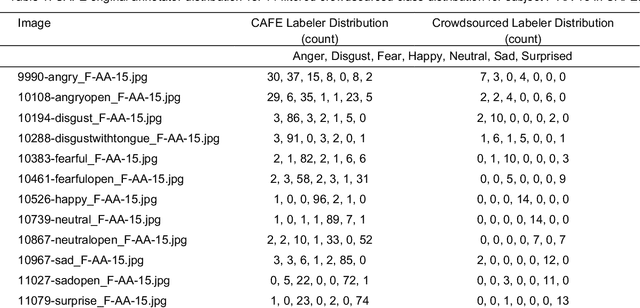
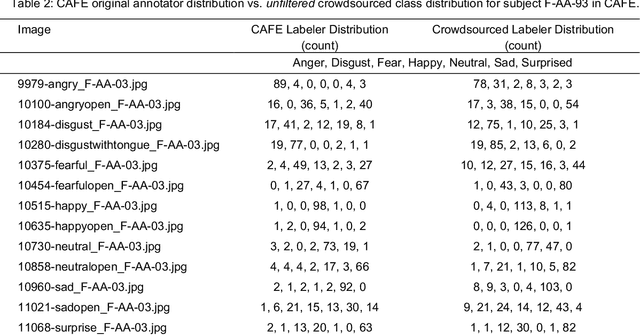
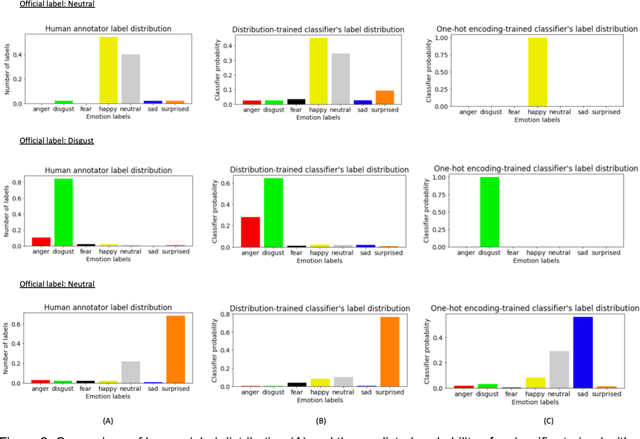
Current emotion detection classifiers predict discrete emotions. However, literature in psychology has documented that compound and ambiguous facial expressions are often evoked by humans. As a stride towards development of machine learning models that more accurately reflect compound and ambiguous emotions, we replace traditional one-hot encoded label representations with a crowd's distribution of labels. We center our study on the Child Affective Facial Expression (CAFE) dataset, a gold standard dataset of pediatric facial expressions which includes 100 human labels per image. We first acquire crowdsourced labels for 207 emotions from CAFE and demonstrate that the consensus labels from the crowd tend to match the consensus from the original CAFE raters, validating the utility of crowdsourcing. We then train two versions of a ResNet-152 classifier on CAFE images with two types of labels (1) traditional one-hot encoding and (2) vector labels representing the crowd distribution of responses. We compare the resulting output distributions of the two classifiers. While the traditional F1-score for the one-hot encoding classifier is much higher (94.33% vs. 78.68%), the output probability vector of the crowd-trained classifier much more closely resembles the distribution of human labels (t=3.2827, p=0.0014). For many applications of affective computing, reporting an emotion probability distribution that more closely resembles human interpretation can be more important than traditional machine learning metrics. This work is a first step for engineers of interactive systems to account for machine learning cases with ambiguous classes and we hope it will generate a discussion about machine learning with ambiguous labels and leveraging crowdsourcing as a potential solution.