 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Family Discriminant Analysis: Generalizing LDA-Style Generative Classification to Non-Gaussian Models
Mar 21, 2026We introduce Exponential Family Discriminant Analysis (EFDA), a unified generative framework that extends classical Linear Discriminant Analysis (LDA) beyond the Gaussian setting to any member of the exponential family. Under the assumption that each class-conditional density belongs to a common exponential family, EFDA derives closed-form maximum-likelihood estimators for all natural parameters and yields a decision rule that is linear in the sufficient statistic, recovering LDA as a special case and capturing nonlinear decision boundaries in the original feature space. We prove that EFDA is asymptotically calibrated and statistically efficient under correct specification, and we generalise it to $K \geq 2$ classes and multivariate data. Through extensive simulation across five exponential-family distributions (Weibull, Gamma, Exponential, Poisson, Negative Binomial), EFDA matches the classification accuracy of LDA, QDA, and logistic regression while reducing Expected Calibration Error (ECE) by $2$--$6\times$, a gap that is \emph{structural}: it persists for all $n$ and across all class-imbalance levels, because misspecified models remain asymptotically miscalibrated. We further prove and empirically confirm that EFDA's log-odds estimator approaches the Cramér-Rao bound under correct specification, and is the only estimator in our comparison whose mean squared error converges to zero. Complete derivations are provided for nine distributions. Finally, we formally verify all four theoretical propositions in Lean 4, using Aristotle (Harmonic) and OpenGauss (Math, Inc.) as proof generators, with all outputs independently machine-checked by AXLE (Axiom).
Comprehensive OOD Detection Improvements
Jan 18, 2024As machine learning becomes increasingly prevalent in impactful decisions, recognizing when inference data is outside the model's expected input distribution is paramount for giving context to predictions. Out-of-distribution (OOD) detection methods have been created for this task. Such methods can be split into representation-based or logit-based methods from whether they respectively utilize the model's embeddings or predictions for OOD detection. In contrast to most papers which solely focus on one such group, we address both. We employ dimensionality reduction on feature embeddings in representation-based methods for both time speedups and improved performance. Additionally, we propose DICE-COL, a modification of the popular logit-based method Directed Sparsification (DICE) that resolves an unnoticed flaw. We demonstrate the effectiveness of our methods on the OpenOODv1.5 benchmark framework, where they significantly improve performance and set state-of-the-art results.
A Novel Explanation Against Linear Neural Networks
Dec 30, 2023Linear Regression and neural networks are widely used to model data. Neural networks distinguish themselves from linear regression with their use of activation functions that enable modeling nonlinear functions. The standard argument for these activation functions is that without them, neural networks only can model a line. However, a novel explanation we propose in this paper for the impracticality of neural networks without activation functions, or linear neural networks, is that they actually reduce both training and testing performance. Having more parameters makes LNNs harder to optimize, and thus they require more training iterations than linear regression to even potentially converge to the optimal solution. We prove this hypothesis through an analysis of the optimization of an LNN and rigorous testing comparing the performance between both LNNs and linear regression on synthethic, noisy datasets.
Mitigating Negative Transfer in Multi-Task Learning with Exponential Moving Average Loss Weighting Strategies
Nov 22, 2022



Multi-Task Learning (MTL) is a growing subject of interest in deep learning, due to its ability to train models more efficiently on multiple tasks compared to using a group of conventional single-task models. However, MTL can be impractical as certain tasks can dominate training and hurt performance in others, thus making some tasks perform better in a single-task model compared to a multi-task one. Such problems are broadly classified as negative transfer, and many prior approaches in the literature have been made to mitigate these issues. One such current approach to alleviate negative transfer is to weight each of the losses so that they are on the same scale. Whereas current loss balancing approaches rely on either optimization or complex numerical analysis, none directly scale the losses based on their observed magnitudes. We propose multiple techniques for loss balancing based on scaling by the exponential moving average and benchmark them against current best-performing methods on three established datasets. On these datasets, they achieve comparable, if not higher, performance compared to current best-performing methods.
Activity Recognition for Autism Diagnosis
Aug 25, 2021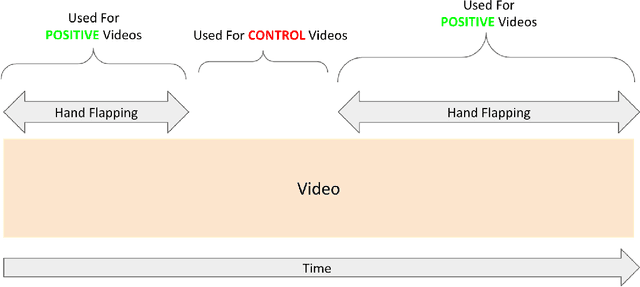
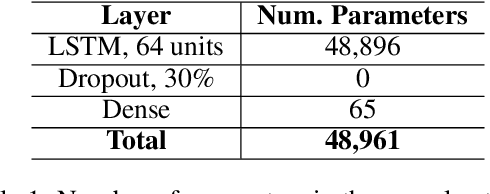


A formal autism diagnosis is an inefficient and lengthy process. Families often have to wait years before receiving a diagnosis for their child; some may not receive one at all due to this delay. One approach to this problem is to use digital technologies to detect the presence of behaviors related to autism, which in aggregate may lead to remote and automated diagnostics. One of the strongest indicators of autism is stimming, which is a set of repetitive, self-stimulatory behaviors such as hand flapping, headbanging, and spinning. Using computer vision to detect hand flapping is especially difficult due to the sparsity of public training data in this space and excessive shakiness and motion in such data. Our work demonstrates a novel method that overcomes these issues: we use hand landmark detection over time as a feature representation which is then fed into a Long Short-Term Memory (LSTM) model. We achieve a validation accuracy and F1 Score of about 72% on detecting whether videos from the Self-Stimulatory Behaviour Dataset (SSBD) contain hand flapping or not. Our best model also predicts accurately on external videos we recorded of ourselves outside of the dataset it was trained on. This model uses less than 26,000 parameters, providing promise for fast deployment into ubiquitous and wearable digital settings for a remote autism diagnosis.