 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoldfish: Vision-Language Understanding of Arbitrarily Long Videos
Jul 17, 2024Most current LLM-based models for video understanding can process videos within minutes. However, they struggle with lengthy videos due to challenges such as "noise and redundancy", as well as "memory and computation" constraints. In this paper, we present Goldfish, a methodology tailored for comprehending videos of arbitrary lengths. We also introduce the TVQA-long benchmark, specifically designed to evaluate models' capabilities in understanding long videos with questions in both vision and text content. Goldfish approaches these challenges with an efficient retrieval mechanism that initially gathers the top-k video clips relevant to the instruction before proceeding to provide the desired response. This design of the retrieval mechanism enables the Goldfish to efficiently process arbitrarily long video sequences, facilitating its application in contexts such as movies or television series. To facilitate the retrieval process, we developed MiniGPT4-Video that generates detailed descriptions for the video clips. In addressing the scarcity of benchmarks for long video evaluation, we adapted the TVQA short video benchmark for extended content analysis by aggregating questions from entire episodes, thereby shifting the evaluation from partial to full episode comprehension. We attained a 41.78% accuracy rate on the TVQA-long benchmark, surpassing previous methods by 14.94%. Our MiniGPT4-Video also shows exceptional performance in short video comprehension, exceeding existing state-of-the-art methods by 3.23%, 2.03%, 16.5% and 23.59% on the MSVD, MSRVTT, TGIF, and TVQA short video benchmarks, respectively. These results indicate that our models have significant improvements in both long and short-video understanding. Our models and code have been made publicly available at https://vision-cair.github.io/Goldfish_website/
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Apr 04, 2024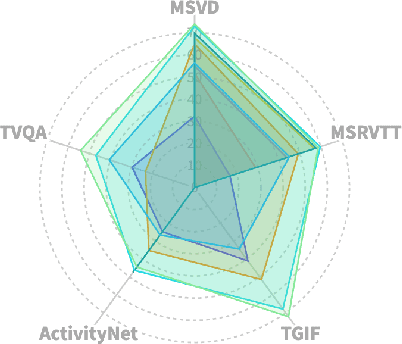

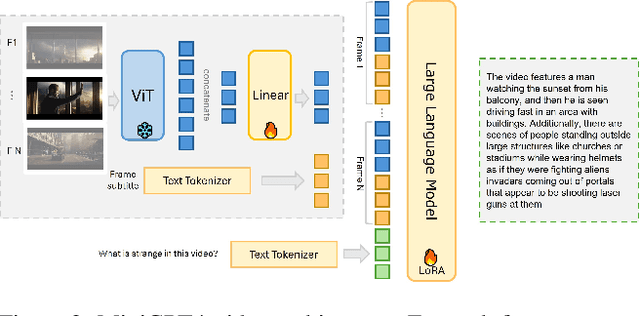

This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
SlowFormer: Universal Adversarial Patch for Attack on Compute and Energy Efficiency of Inference Efficient Vision Transformers
Oct 04, 2023Recently, there has been a lot of progress in reducing the computation of deep models at inference time. These methods can reduce both the computational needs and power usage of deep models. Some of these approaches adaptively scale the compute based on the input instance. We show that such models can be vulnerable to a universal adversarial patch attack, where the attacker optimizes for a patch that when pasted on any image, can increase the compute and power consumption of the model. We run experiments with three different efficient vision transformer methods showing that in some cases, the attacker can increase the computation to the maximum possible level by simply pasting a patch that occupies only 8\% of the image area. We also show that a standard adversarial training defense method can reduce some of the attack's success. We believe adaptive efficient methods will be necessary for the future to lower the power usage of deep models, so we hope our paper encourages the community to study the robustness of these methods and develop better defense methods for the proposed attack.
Mitigating Negative Transfer in Multi-Task Learning with Exponential Moving Average Loss Weighting Strategies
Nov 22, 2022



Multi-Task Learning (MTL) is a growing subject of interest in deep learning, due to its ability to train models more efficiently on multiple tasks compared to using a group of conventional single-task models. However, MTL can be impractical as certain tasks can dominate training and hurt performance in others, thus making some tasks perform better in a single-task model compared to a multi-task one. Such problems are broadly classified as negative transfer, and many prior approaches in the literature have been made to mitigate these issues. One such current approach to alleviate negative transfer is to weight each of the losses so that they are on the same scale. Whereas current loss balancing approaches rely on either optimization or complex numerical analysis, none directly scale the losses based on their observed magnitudes. We propose multiple techniques for loss balancing based on scaling by the exponential moving average and benchmark them against current best-performing methods on three established datasets. On these datasets, they achieve comparable, if not higher, performance compared to current best-performing methods.