 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Zoom-Zero: Reinforced Coarse-to-Fine Video Understanding via Temporal Zoom-in
Dec 16, 2025Grounded video question answering (GVQA) aims to localize relevant temporal segments in videos and generate accurate answers to a given question; however, large video-language models (LVLMs) exhibit limited temporal awareness. Although existing approaches based on Group Relative Policy Optimization (GRPO) attempt to improve temporal grounding, they still struggle to faithfully ground their answers in the relevant video evidence, leading to temporal mislocalization and hallucinations. In this work, we present Zoom-Zero, a coarse-to-fine framework that first localizes query-relevant segments and then temporally zooms into the most salient frames for finer-grained visual verification. Our method addresses the limits of GRPO for the GVQA task with two key innovations: (i) a zoom-in accuracy reward that validates the fidelity of temporal grounding prediction and facilitates fine-grained visual verification on grounded frames; (ii) token-selective credit assignment, which attributes rewards to the tokens responsible for temporal localization or answer generation, mitigating GRPO's issue in handling multi-faceted reward signals. Our proposed method advances grounded video question answering, improving temporal grounding by 5.2\% on NExT-GQA and 4.6\% on ReXTime, while also enhancing average answer accuracy by 2.4\%. Additionally, the coarse-to-fine zoom-in during inference further benefits long-form video understanding by preserving critical visual details without compromising global context, yielding an average improvement of 6.4\% on long-video benchmarks.
WikiAutoGen: Towards Multi-Modal Wikipedia-Style Article Generation
Mar 24, 2025Knowledge discovery and collection are intelligence-intensive tasks that traditionally require significant human effort to ensure high-quality outputs. Recent research has explored multi-agent frameworks for automating Wikipedia-style article generation by retrieving and synthesizing information from the internet. However, these methods primarily focus on text-only generation, overlooking the importance of multimodal content in enhancing informativeness and engagement. In this work, we introduce WikiAutoGen, a novel system for automated multimodal Wikipedia-style article generation. Unlike prior approaches, WikiAutoGen retrieves and integrates relevant images alongside text, enriching both the depth and visual appeal of generated content. To further improve factual accuracy and comprehensiveness, we propose a multi-perspective self-reflection mechanism, which critically assesses retrieved content from diverse viewpoints to enhance reliability, breadth, and coherence, etc. Additionally, we introduce WikiSeek, a benchmark comprising Wikipedia articles with topics paired with both textual and image-based representations, designed to evaluate multimodal knowledge generation on more challenging topics. Experimental results show that WikiAutoGen outperforms previous methods by 8%-29% on our WikiSeek benchmark, producing more accurate, coherent, and visually enriched Wikipedia-style articles. We show some of our generated examples in https://wikiautogen.github.io/ .
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.
Openstory++: A Large-scale Dataset and Benchmark for Instance-aware Open-domain Visual Storytelling
Aug 07, 2024



Recent image generation models excel at creating high-quality images from brief captions. However, they fail to maintain consistency of multiple instances across images when encountering lengthy contexts. This inconsistency is largely due to in existing training datasets the absence of granular instance feature labeling in existing training datasets. To tackle these issues, we introduce Openstory++, a large-scale dataset combining additional instance-level annotations with both images and text. Furthermore, we develop a training methodology that emphasizes entity-centric image-text generation, ensuring that the models learn to effectively interweave visual and textual information. Specifically, Openstory++ streamlines the process of keyframe extraction from open-domain videos, employing vision-language models to generate captions that are then polished by a large language model for narrative continuity. It surpasses previous datasets by offering a more expansive open-domain resource, which incorporates automated captioning, high-resolution imagery tailored for instance count, and extensive frame sequences for temporal consistency. Additionally, we present Cohere-Bench, a pioneering benchmark framework for evaluating the image generation tasks when long multimodal context is provided, including the ability to keep the background, style, instances in the given context coherent. Compared to existing benchmarks, our work fills critical gaps in multi-modal generation, propelling the development of models that can adeptly generate and interpret complex narratives in open-domain environments. Experiments conducted within Cohere-Bench confirm the superiority of Openstory++ in nurturing high-quality visual storytelling models, enhancing their ability to address open-domain generation tasks. More details can be found at https://openstorypp.github.io/
Goldfish: Vision-Language Understanding of Arbitrarily Long Videos
Jul 17, 2024Most current LLM-based models for video understanding can process videos within minutes. However, they struggle with lengthy videos due to challenges such as "noise and redundancy", as well as "memory and computation" constraints. In this paper, we present Goldfish, a methodology tailored for comprehending videos of arbitrary lengths. We also introduce the TVQA-long benchmark, specifically designed to evaluate models' capabilities in understanding long videos with questions in both vision and text content. Goldfish approaches these challenges with an efficient retrieval mechanism that initially gathers the top-k video clips relevant to the instruction before proceeding to provide the desired response. This design of the retrieval mechanism enables the Goldfish to efficiently process arbitrarily long video sequences, facilitating its application in contexts such as movies or television series. To facilitate the retrieval process, we developed MiniGPT4-Video that generates detailed descriptions for the video clips. In addressing the scarcity of benchmarks for long video evaluation, we adapted the TVQA short video benchmark for extended content analysis by aggregating questions from entire episodes, thereby shifting the evaluation from partial to full episode comprehension. We attained a 41.78% accuracy rate on the TVQA-long benchmark, surpassing previous methods by 14.94%. Our MiniGPT4-Video also shows exceptional performance in short video comprehension, exceeding existing state-of-the-art methods by 3.23%, 2.03%, 16.5% and 23.59% on the MSVD, MSRVTT, TGIF, and TVQA short video benchmarks, respectively. These results indicate that our models have significant improvements in both long and short-video understanding. Our models and code have been made publicly available at https://vision-cair.github.io/Goldfish_website/
iMotion-LLM: Motion Prediction Instruction Tuning
Jun 11, 2024
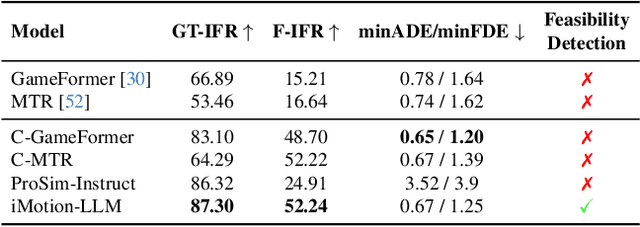
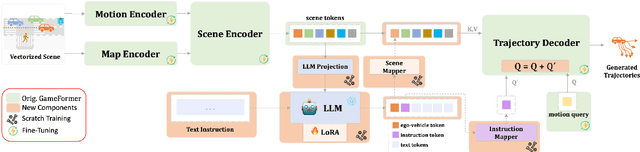

We introduce iMotion-LLM: a Multimodal Large Language Models (LLMs) with trajectory prediction, tailored to guide interactive multi-agent scenarios. Different from conventional motion prediction approaches, iMotion-LLM capitalizes on textual instructions as key inputs for generating contextually relevant trajectories. By enriching the real-world driving scenarios in the Waymo Open Dataset with textual motion instructions, we created InstructWaymo. Leveraging this dataset, iMotion-LLM integrates a pretrained LLM, fine-tuned with LoRA, to translate scene features into the LLM input space. iMotion-LLM offers significant advantages over conventional motion prediction models. First, it can generate trajectories that align with the provided instructions if it is a feasible direction. Second, when given an infeasible direction, it can reject the instruction, thereby enhancing safety. These findings act as milestones in empowering autonomous navigation systems to interpret and predict the dynamics of multi-agent environments, laying the groundwork for future advancements in this field.
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Apr 04, 2024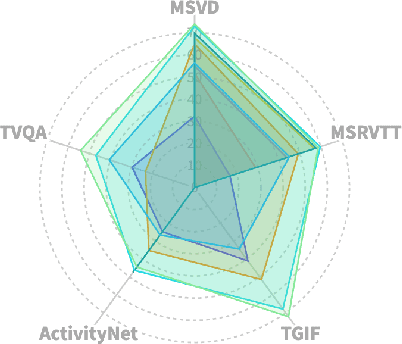

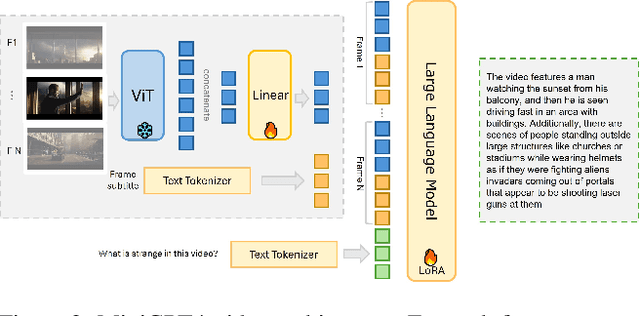

This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
Large Language Models as Consistent Story Visualizers
Dec 04, 2023



Recent generative models have demonstrated impressive capabilities in generating realistic and visually pleasing images grounded on textual prompts. Nevertheless, a significant challenge remains in applying these models for the more intricate task of story visualization. Since it requires resolving pronouns (he, she, they) in the frame descriptions, i.e., anaphora resolution, and ensuring consistent characters and background synthesis across frames. Yet, the emerging Large Language Model (LLM) showcases robust reasoning abilities to navigate through ambiguous references and process extensive sequences. Therefore, we introduce \textbf{StoryGPT-V}, which leverages the merits of the latent diffusion (LDM) and LLM to produce images with consistent and high-quality characters grounded on given story descriptions. First, we train a character-aware LDM, which takes character-augmented semantic embedding as input and includes the supervision of the cross-attention map using character segmentation masks, aiming to enhance character generation accuracy and faithfulness. In the second stage, we enable an alignment between the output of LLM and the character-augmented embedding residing in the input space of the first-stage model. This harnesses the reasoning ability of LLM to address ambiguous references and the comprehension capability to memorize the context. We conduct comprehensive experiments on two visual story visualization benchmarks. Our model reports superior quantitative results and consistently generates accurate characters of remarkable quality with low memory consumption. Our code will be made publicly available.
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Oct 26, 2023



Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, we introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question-answering and visual grounding benchmarks compared to other vision-language generalist models. Our model and codes are available at https://minigpt-v2.github.io/