 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
Apr 22, 2025Recent text-to-image diffusion models achieve impressive visual quality through extensive scaling of training data and model parameters, yet they often struggle with complex scenes and fine-grained details. Inspired by the self-reflection capabilities emergent in large language models, we propose ReflectionFlow, an inference-time framework enabling diffusion models to iteratively reflect upon and refine their outputs. ReflectionFlow introduces three complementary inference-time scaling axes: (1) noise-level scaling to optimize latent initialization; (2) prompt-level scaling for precise semantic guidance; and most notably, (3) reflection-level scaling, which explicitly provides actionable reflections to iteratively assess and correct previous generations. To facilitate reflection-level scaling, we construct GenRef, a large-scale dataset comprising 1 million triplets, each containing a reflection, a flawed image, and an enhanced image. Leveraging this dataset, we efficiently perform reflection tuning on state-of-the-art diffusion transformer, FLUX.1-dev, by jointly modeling multimodal inputs within a unified framework. Experimental results show that ReflectionFlow significantly outperforms naive noise-level scaling methods, offering a scalable and compute-efficient solution toward higher-quality image synthesis on challenging tasks.
WikiAutoGen: Towards Multi-Modal Wikipedia-Style Article Generation
Mar 24, 2025Knowledge discovery and collection are intelligence-intensive tasks that traditionally require significant human effort to ensure high-quality outputs. Recent research has explored multi-agent frameworks for automating Wikipedia-style article generation by retrieving and synthesizing information from the internet. However, these methods primarily focus on text-only generation, overlooking the importance of multimodal content in enhancing informativeness and engagement. In this work, we introduce WikiAutoGen, a novel system for automated multimodal Wikipedia-style article generation. Unlike prior approaches, WikiAutoGen retrieves and integrates relevant images alongside text, enriching both the depth and visual appeal of generated content. To further improve factual accuracy and comprehensiveness, we propose a multi-perspective self-reflection mechanism, which critically assesses retrieved content from diverse viewpoints to enhance reliability, breadth, and coherence, etc. Additionally, we introduce WikiSeek, a benchmark comprising Wikipedia articles with topics paired with both textual and image-based representations, designed to evaluate multimodal knowledge generation on more challenging topics. Experimental results show that WikiAutoGen outperforms previous methods by 8%-29% on our WikiSeek benchmark, producing more accurate, coherent, and visually enriched Wikipedia-style articles. We show some of our generated examples in https://wikiautogen.github.io/ .
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Nov 24, 2023

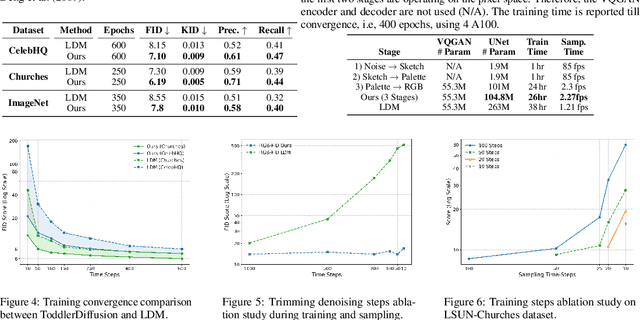

Diffusion-based generative models excel in perceptually impressive synthesis but face challenges in interpretability. This paper introduces ToddlerDiffusion, an interpretable 2D diffusion image-synthesis framework inspired by the human generation system. Unlike traditional diffusion models with opaque denoising steps, our approach decomposes the generation process into simpler, interpretable stages; generating contours, a palette, and a detailed colored image. This not only enhances overall performance but also enables robust editing and interaction capabilities. Each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM). Extensive experiments on datasets like LSUN-Churches and COCO validate our approach, consistently outperforming existing methods. ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating three times faster with a 3.76 times smaller architecture. Our source code is provided in the supplementary material and will be publicly accessible.