 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Self-supervised 3D Scene Flows with Surface Awareness and Cyclic Consistency
Dec 12, 2023Learning without supervision how to predict 3D scene flows from point clouds is central to many vision systems. We propose a novel learning framework for this task which improves the necessary regularization. Relying on the assumption that scene elements are mostly rigid, current smoothness losses are built on the definition of ``rigid clusters" in the input point clouds. The definition of these clusters is challenging and has a major impact on the quality of predicted flows. We introduce two new consistency losses that enlarge clusters while preventing them from spreading over distinct objects. In particular, we enforce \emph{temporal} consistency with a forward-backward cyclic loss and \emph{spatial} consistency by considering surface orientation similarity in addition to spatial proximity. The proposed losses are model-independent and can thus be used in a plug-and-play fashion to significantly improve the performance of existing models, as demonstrated on two top-performing ones. We also showcase the effectiveness and generalization capability of our framework on four standard sensor-unique driving datasets, achieving state-of-the-art performance in 3D scene flow estimation. Our codes are available anonymously on \url{https://github.com/vacany/sac-flow}.
PointBeV: A Sparse Approach to BeV Predictions
Dec 01, 2023



Bird's-eye View (BeV) representations have emerged as the de-facto shared space in driving applications, offering a unified space for sensor data fusion and supporting various downstream tasks. However, conventional models use grids with fixed resolution and range and face computational inefficiencies due to the uniform allocation of resources across all cells. To address this, we propose PointBeV, a novel sparse BeV segmentation model operating on sparse BeV cells instead of dense grids. This approach offers precise control over memory usage, enabling the use of long temporal contexts and accommodating memory-constrained platforms. PointBeV employs an efficient two-pass strategy for training, enabling focused computation on regions of interest. At inference time, it can be used with various memory/performance trade-offs and flexibly adjusts to new specific use cases. PointBeV achieves state-of-the-art results on the nuScenes dataset for vehicle, pedestrian, and lane segmentation, showcasing superior performance in static and temporal settings despite being trained solely with sparse signals. We will release our code along with two new efficient modules used in the architecture: Sparse Feature Pulling, designed for the effective extraction of features from images to BeV, and Submanifold Attention, which enables efficient temporal modeling. Our code is available at https://github.com/valeoai/PointBeV.
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Nov 24, 2023

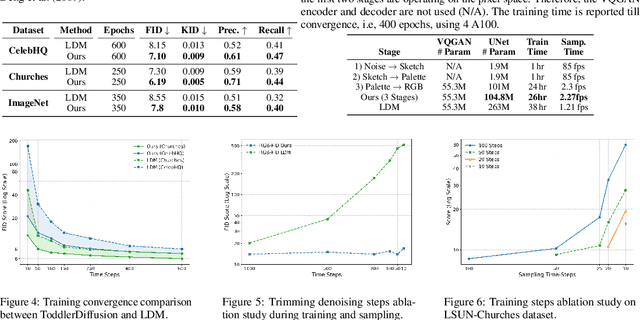

Diffusion-based generative models excel in perceptually impressive synthesis but face challenges in interpretability. This paper introduces ToddlerDiffusion, an interpretable 2D diffusion image-synthesis framework inspired by the human generation system. Unlike traditional diffusion models with opaque denoising steps, our approach decomposes the generation process into simpler, interpretable stages; generating contours, a palette, and a detailed colored image. This not only enhances overall performance but also enables robust editing and interaction capabilities. Each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM). Extensive experiments on datasets like LSUN-Churches and COCO validate our approach, consistently outperforming existing methods. ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating three times faster with a 3.76 times smaller architecture. Our source code is provided in the supplementary material and will be publicly accessible.
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022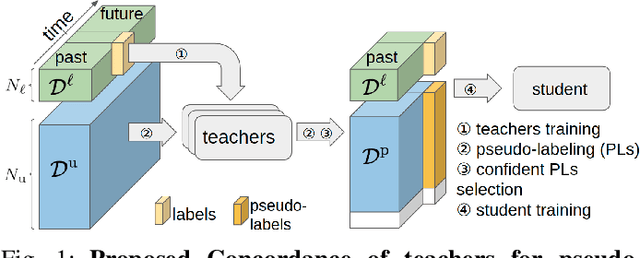
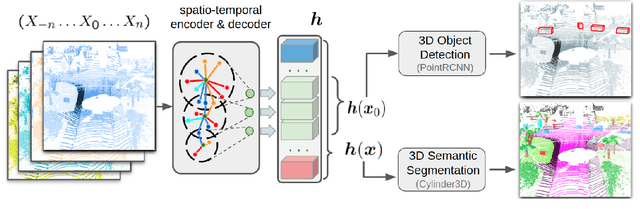

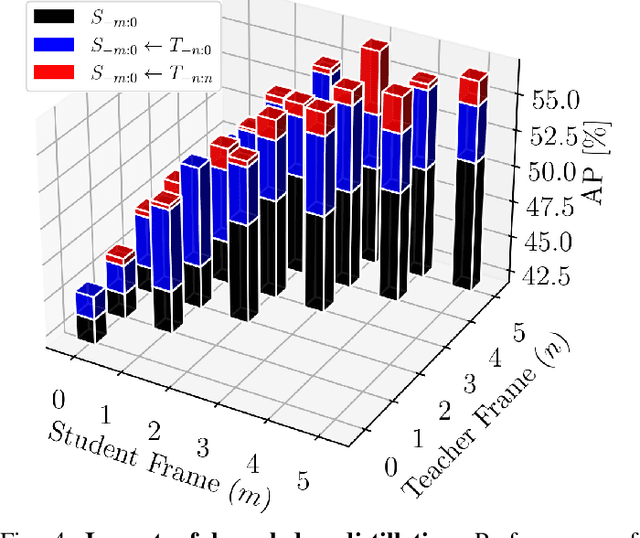
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
The Missing Data Encoder: Cross-Channel Image Completion\\with Hide-And-Seek Adversarial Network
May 06, 2019



Image completion is the problem of generating whole images from fragments only. It encompasses inpainting (generating a patch given its surrounding), reverse inpainting/extrapolation (generating the periphery given the central patch) as well as colorization (generating one or several channels given other ones). In this paper, we employ a deep network to perform image completion, with adversarial training as well as perceptual and completion losses, and call it the ``missing data encoder'' (MDE). We consider several configurations based on how the seed fragments are chosen. We show that training MDE for ``random extrapolation and colorization'' (MDE-REC), i.e. using random channel-independent fragments, allows a better capture of the image semantics and geometry. MDE training makes use of a novel ``hide-and-seek'' adversarial loss, where the discriminator seeks the original non-masked regions, while the generator tries to hide them. We validate our models both qualitatively and quantitatively on several datasets, showing their interest for image completion, unsupervised representation learning as well as face occlusion handling.
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
May 04, 2019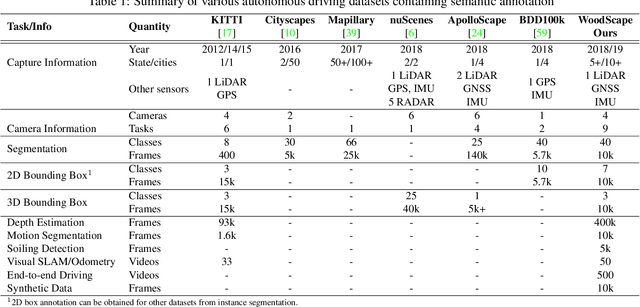
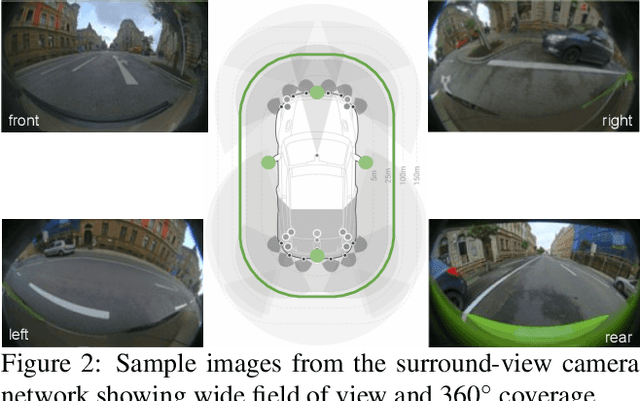
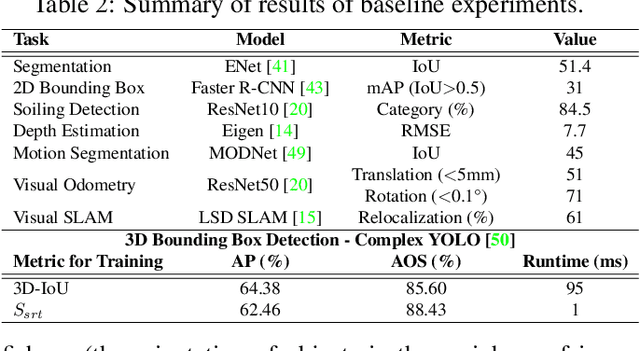
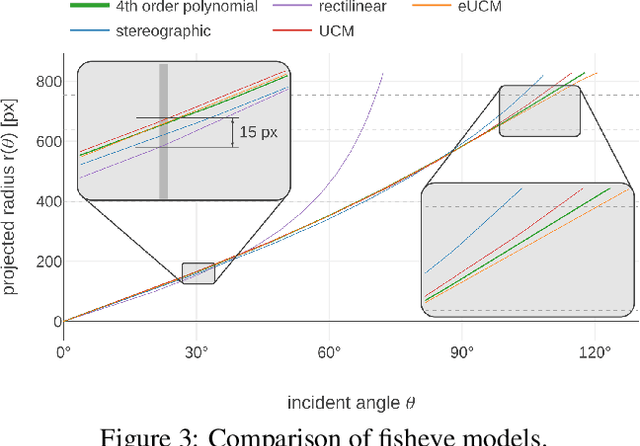
Fisheye cameras are commonly employed for obtaining a large field of view in surveillance, augmented reality and in particular automotive applications. In spite of its prevalence, there are few public datasets for detailed evaluation of computer vision algorithms on fisheye images. We release the first extensive fisheye automotive dataset, WoodScape, named after Robert Wood who invented the fisheye camera in 1906. WoodScape comprises of four surround view cameras and nine tasks including segmentation, depth estimation, 3D bounding box detection and soiling detection. Semantic annotation of 40 classes at the instance level is provided for over 10,000 images and annotation for other tasks are provided for over 100,000 images. We would like to encourage the community to adapt computer vision models for fisheye camera instead of naive rectification.
Unsupervised Image Matching and Object Discovery as Optimization
Apr 05, 2019


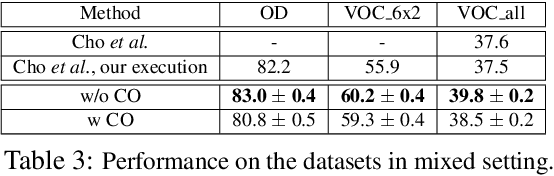
Learning with complete or partial supervision is powerful but relies on ever-growing human annotation efforts. As a way to mitigate this serious problem, as well as to serve specific applications, unsupervised learning has emerged as an important field of research. In computer vision, unsupervised learning comes in various guises. We focus here on the unsupervised discovery and matching of object categories among images in a collection, following the work of Cho et al. 2015. We show that the original approach can be reformulated and solved as a proper optimization problem. Experiments on several benchmarks establish the merit of our approach.
Exploring applications of deep reinforcement learning for real-world autonomous driving systems
Jan 16, 2019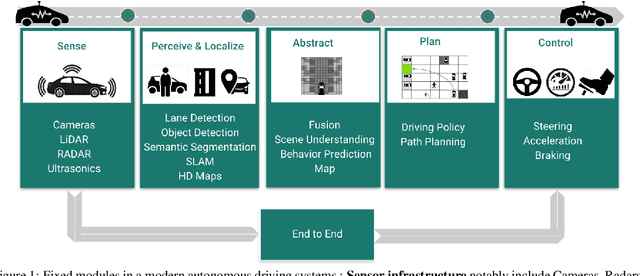
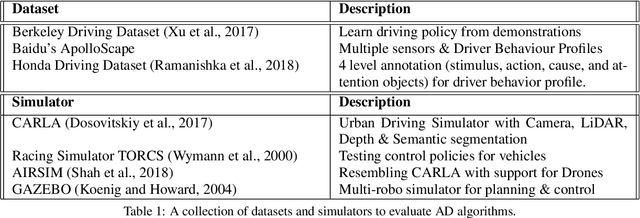
Deep Reinforcement Learning (DRL) has become increasingly powerful in recent years, with notable achievements such as Deepmind's AlphaGo. It has been successfully deployed in commercial vehicles like Mobileye's path planning system. However, a vast majority of work on DRL is focused on toy examples in controlled synthetic car simulator environments such as TORCS and CARLA. In general, DRL is still at its infancy in terms of usability in real-world applications. Our goal in this paper is to encourage real-world deployment of DRL in various autonomous driving (AD) applications. We first provide an overview of the tasks in autonomous driving systems, reinforcement learning algorithms and applications of DRL to AD systems. We then discuss the challenges which must be addressed to enable further progress towards real-world deployment.
Learning how to be robust: Deep polynomial regression
May 23, 2018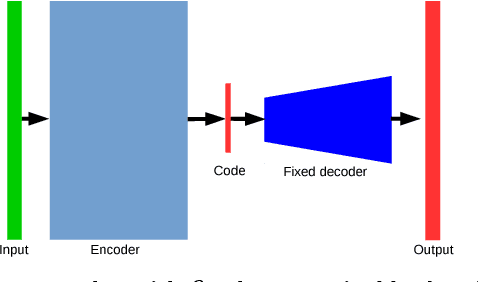


Polynomial regression is a recurrent problem with a large number of applications. In computer vision it often appears in motion analysis. Whatever the application, standard methods for regression of polynomial models tend to deliver biased results when the input data is heavily contaminated by outliers. Moreover, the problem is even harder when outliers have strong structure. Departing from problem-tailored heuristics for robust estimation of parametric models, we explore deep convolutional neural networks. Our work aims to find a generic approach for training deep regression models without the explicit need of supervised annotation. We bypass the need for a tailored loss function on the regression parameters by attaching to our model a differentiable hard-wired decoder corresponding to the polynomial operation at hand. We demonstrate the value of our findings by comparing with standard robust regression methods. Furthermore, we demonstrate how to use such models for a real computer vision problem, i.e., video stabilization. The qualitative and quantitative experiments show that neural networks are able to learn robustness for general polynomial regression, with results that well overpass scores of traditional robust estimation methods.
Structural inpainting
Mar 27, 2018


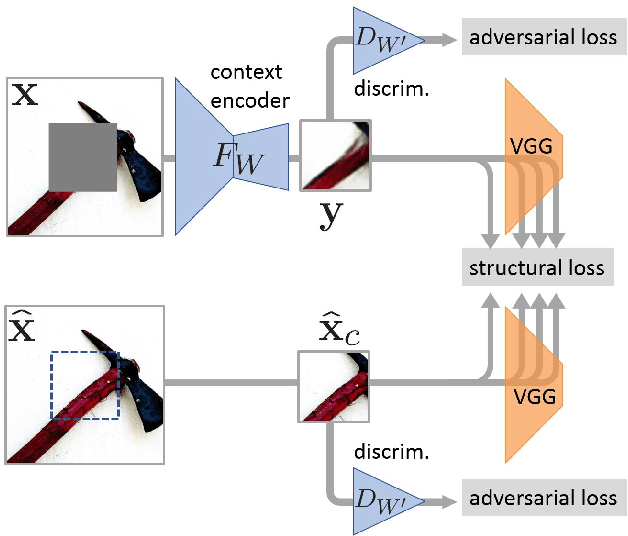
Scene-agnostic visual inpainting remains very challenging despite progress in patch-based methods. Recently, Pathak et al. 2016 have introduced convolutional "context encoders" (CEs) for unsupervised feature learning through image completion tasks. With the additional help of adversarial training, CEs turned out to be a promising tool to complete complex structures in real inpainting problems. In the present paper we propose to push further this key ability by relying on perceptual reconstruction losses at training time. We show on a wide variety of visual scenes the merit of the approach for structural inpainting, and confirm it through a user study. Combined with the optimization-based refinement of Yang et al. 2016 with neural patches, our context encoder opens up new opportunities for prior-free visual inpainting.