 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Dec 30, 2025A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.
Value-guided action planning with JEPA world models
Dec 28, 2025Building deep learning models that can reason about their environment requires capturing its underlying dynamics. Joint-Embedded Predictive Architectures (JEPA) provide a promising framework to model such dynamics by learning representations and predictors through a self-supervised prediction objective. However, their ability to support effective action planning remains limited. We propose an approach to enhance planning with JEPA world models by shaping their representation space so that the negative goal-conditioned value function for a reaching cost in a given environment is approximated by a distance (or quasi-distance) between state embeddings. We introduce a practical method to enforce this constraint during training and show that it leads to significantly improved planning performance compared to standard JEPA models on simple control tasks.
Optimal transport unlocks end-to-end learning for single-molecule localization
Dec 11, 2025Single-molecule localization microscopy (SMLM) allows reconstructing biology-relevant structures beyond the diffraction limit by detecting and localizing individual fluorophores -- fluorescent molecules stained onto the observed specimen -- over time to reconstruct super-resolved images. Currently, efficient SMLM requires non-overlapping emitting fluorophores, leading to long acquisition times that hinders live-cell imaging. Recent deep-learning approaches can handle denser emissions, but they rely on variants of non-maximum suppression (NMS) layers, which are unfortunately non-differentiable and may discard true positives with their local fusion strategy. In this presentation, we reformulate the SMLM training objective as a set-matching problem, deriving an optimal-transport loss that eliminates the need for NMS during inference and enables end-to-end training. Additionally, we propose an iterative neural network that integrates knowledge of the microscope's optical system inside our model. Experiments on synthetic benchmarks and real biological data show that both our new loss function and architecture surpass the state of the art at moderate and high emitter densities. Code is available at https://github.com/RSLLES/SHOT.
Online 3D Scene Reconstruction Using Neural Object Priors
Mar 24, 2025This paper addresses the problem of reconstructing a scene online at the level of objects given an RGB-D video sequence. While current object-aware neural implicit representations hold promise, they are limited in online reconstruction efficiency and shape completion. Our main contributions to alleviate the above limitations are twofold. First, we propose a feature grid interpolation mechanism to continuously update grid-based object-centric neural implicit representations as new object parts are revealed. Second, we construct an object library with previously mapped objects in advance and leverage the corresponding shape priors to initialize geometric object models in new videos, subsequently completing them with novel views as well as synthesized past views to avoid losing original object details. Extensive experiments on synthetic environments from the Replica dataset, real-world ScanNet sequences and videos captured in our laboratory demonstrate that our approach outperforms state-of-the-art neural implicit models for this task in terms of reconstruction accuracy and completeness.
A New Statistical Model of Star Speckles for Learning to Detect and Characterize Exoplanets in Direct Imaging Observations
Mar 21, 2025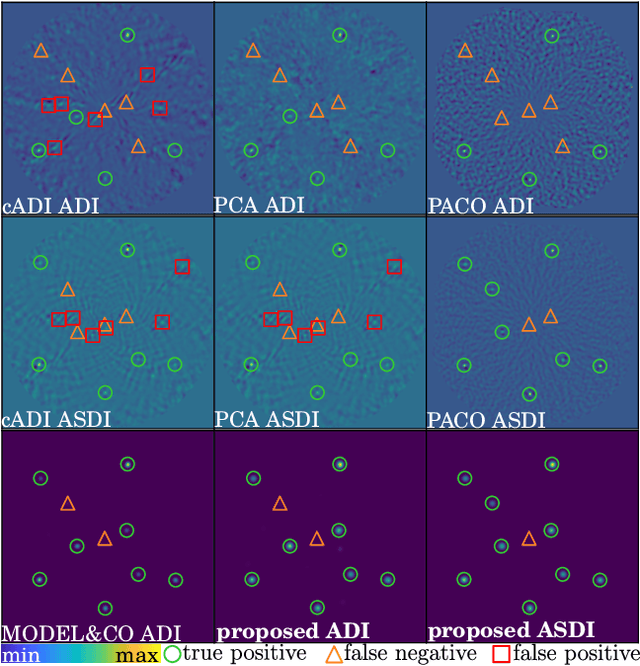
The search for exoplanets is an active field in astronomy, with direct imaging as one of the most challenging methods due to faint exoplanet signals buried within stronger residual starlight. Successful detection requires advanced image processing to separate the exoplanet signal from this nuisance component. This paper presents a novel statistical model that captures nuisance fluctuations using a multi-scale approach, leveraging problem symmetries and a joint spectral channel representation grounded in physical principles. Our model integrates into an interpretable, end-to-end learnable framework for simultaneous exoplanet detection and flux estimation. The proposed algorithm is evaluated against the state of the art using datasets from the SPHERE instrument operating at the Very Large Telescope (VLT). It significantly improves the precision-recall trade-off, notably on challenging datasets that are otherwise unusable by astronomers. The proposed approach is computationally efficient, robust to varying data quality, and well suited for large-scale observational surveys.
Detecting Looted Archaeological Sites from Satellite Image Time Series
Sep 14, 2024



Archaeological sites are the physical remains of past human activity and one of the main sources of information about past societies and cultures. However, they are also the target of malevolent human actions, especially in countries having experienced inner turmoil and conflicts. Because monitoring these sites from space is a key step towards their preservation, we introduce the DAFA Looted Sites dataset, \datasetname, a labeled multi-temporal remote sensing dataset containing 55,480 images acquired monthly over 8 years across 675 Afghan archaeological sites, including 135 sites looted during the acquisition period. \datasetname~is particularly challenging because of the limited number of training samples, the class imbalance, the weak binary annotations only available at the level of the time series, and the subtlety of relevant changes coupled with important irrelevant ones over a long time period. It is also an interesting playground to assess the performance of satellite image time series (SITS) classification methods on a real and important use case. We evaluate a large set of baselines, outline the substantial benefits of using foundation models and show the additional boost that can be provided by using complete time series instead of using a single image.
Satellite Image Time Series Semantic Change Detection: Novel Architecture and Analysis of Domain Shift
Jul 10, 2024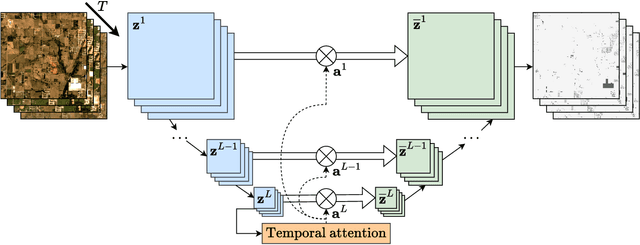
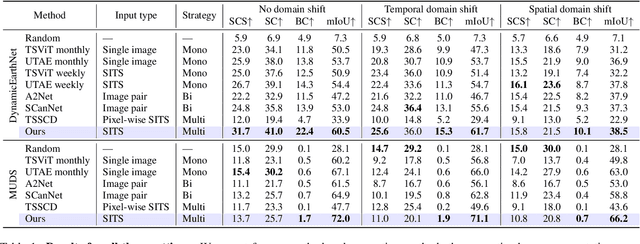
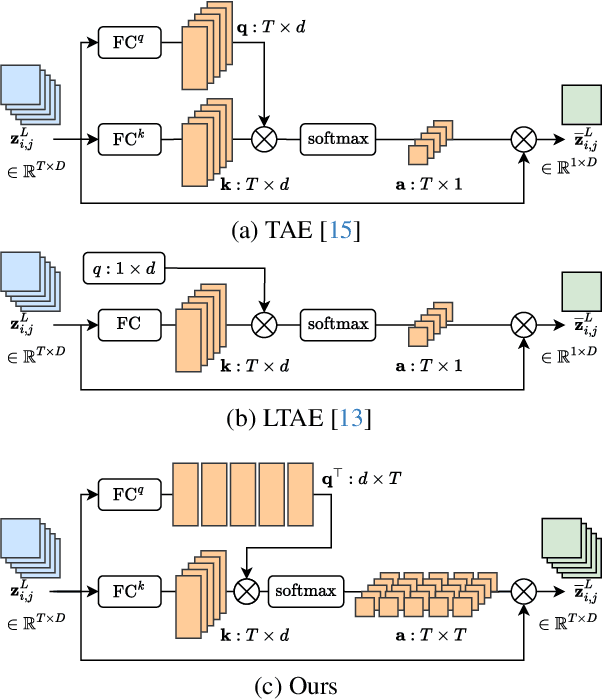
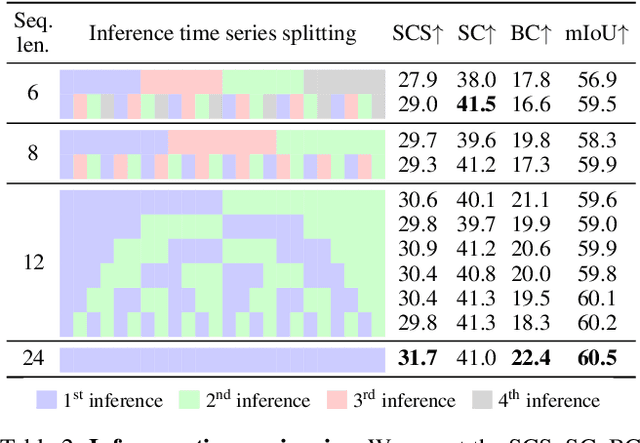
Satellite imagery plays a crucial role in monitoring changes happening on Earth's surface and aiding in climate analysis, ecosystem assessment, and disaster response. In this paper, we tackle semantic change detection with satellite image time series (SITS-SCD) which encompasses both change detection and semantic segmentation tasks. We propose a new architecture that improves over the state of the art, scales better with the number of parameters, and leverages long-term temporal information. However, for practical use cases, models need to adapt to spatial and temporal shifts, which remains a challenge. We investigate the impact of temporal and spatial shifts separately on global, multi-year SITS datasets using DynamicEarthNet and MUDS. We show that the spatial domain shift represents the most complex setting and that the impact of temporal shift on performance is more pronounced on change detection than on semantic segmentation, highlighting that it is a specific issue deserving further attention.
PICNIQ: Pairwise Comparisons for Natural Image Quality Assessment
Mar 13, 2024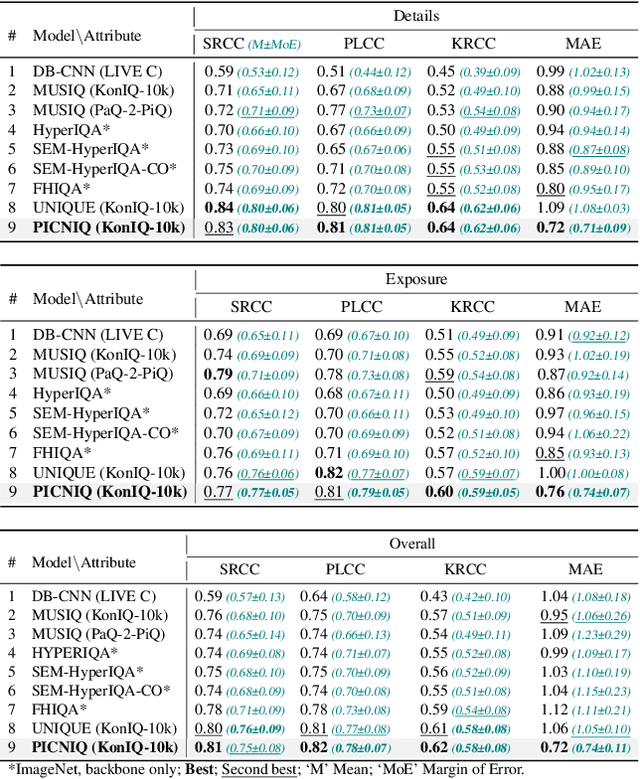


Blind image quality assessment (BIQA) approaches, while promising for automating image quality evaluation, often fall short in real-world scenarios due to their reliance on a generic quality standard applied uniformly across diverse images. This one-size-fits-all approach overlooks the crucial perceptual relationship between image content and quality, leading to a 'domain shift' challenge where a single quality metric inadequately represents various content types. Furthermore, BIQA techniques typically overlook the inherent differences in the human visual system among different observers. In response to these challenges, this paper introduces PICNIQ, an innovative pairwise comparison framework designed to bypass the limitations of conventional BIQA by emphasizing relative, rather than absolute, quality assessment. PICNIQ is specifically designed to assess the quality differences between image pairs. The proposed framework implements a carefully crafted deep learning architecture, a specialized loss function, and a training strategy optimized for sparse comparison settings. By employing psychometric scaling algorithms like TrueSkill, PICNIQ transforms pairwise comparisons into just-objectionable-difference (JOD) quality scores, offering a granular and interpretable measure of image quality. We conduct our research using comparison matrices from the PIQ23 dataset, which are published in this paper. Our extensive experimental analysis showcases PICNIQ's broad applicability and superior performance over existing models, highlighting its potential to set new standards in the field of BIQA.
Generalized Portrait Quality Assessment
Feb 14, 2024

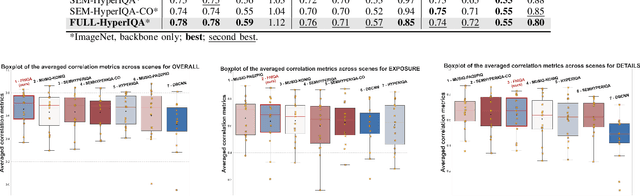
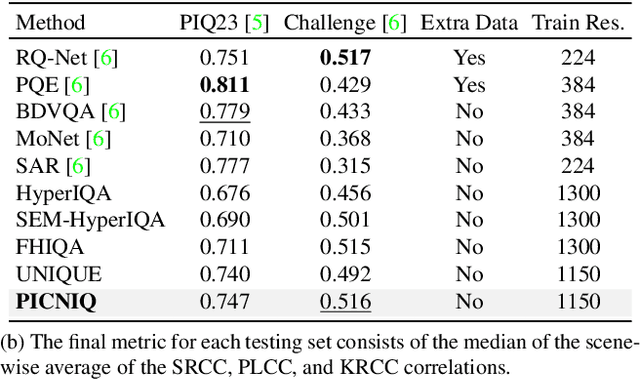
Automated and robust portrait quality assessment (PQA) is of paramount importance in high-impact applications such as smartphone photography. This paper presents FHIQA, a learning-based approach to PQA that introduces a simple but effective quality score rescaling method based on image semantics, to enhance the precision of fine-grained image quality metrics while ensuring robust generalization to various scene settings beyond the training dataset. The proposed approach is validated by extensive experiments on the PIQ23 benchmark and comparisons with the current state of the art. The source code of FHIQA will be made publicly available on the PIQ23 GitHub repository at https://github.com/DXOMARK-Research/PIQ2023.
Fine Dense Alignment of Image Bursts through Camera Pose and Depth Estimation
Dec 08, 2023This paper introduces a novel approach to the fine alignment of images in a burst captured by a handheld camera. In contrast to traditional techniques that estimate two-dimensional transformations between frame pairs or rely on discrete correspondences, the proposed algorithm establishes dense correspondences by optimizing both the camera motion and surface depth and orientation at every pixel. This approach improves alignment, particularly in scenarios with parallax challenges. Extensive experiments with synthetic bursts featuring small and even tiny baselines demonstrate that it outperforms the best optical flow methods available today in this setting, without requiring any training. Beyond enhanced alignment, our method opens avenues for tasks beyond simple image restoration, such as depth estimation and 3D reconstruction, as supported by promising preliminary results. This positions our approach as a versatile tool for various burst image processing applications.