 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveJudge: Rethinking Autonomous Driving Evaluation with Vision-Language Models
Jun 15, 2026Autonomous driving has shifted towards end-to-end policy learning, where reliable, interpretable policy evaluation is a fundamental challenge as driving quality is highly context-dependent. Commonly used rule-based driving metrics like EPDMS are interpretable but lack context-awareness, while recent VLMbased evaluations are context-aware but limited by ambiguous VLM outputs and weak physical grounding. To evaluate driving in a manner that is both interpretable and context-aware, we introduce DriveJudge. DriveJudge is a driving evaluation agent that combines rule-grounded evaluation with Vision-Language Model (VLM) reasoning and selectively invokes physically-grounded deterministic rule functions after interpreting the environmental context. To train and evaluate DriveJudge, we curate a large-scale dataset of 33,577 challenging driving samples with human annotations on whether the driving behavior is reasonable in the given scenario. With this dataset, we address the underexplored problem of driving metric evaluation, and introduce two human-aligned benchmark tasks: Driving Quality Classification and Trajectory Preference Selection. DriveJudge outperforms EPDMS for driving quality classification by 21.23 AUC, and the recent VLM-based DriveCritic for trajectory preference selection by 6.5%, setting a new standard for interpretable and precise driving evaluation.
HAD: Combining Hierarchical Diffusion with Metric-Decoupled RL for End-to-End Driving
Apr 04, 2026End-to-end planning has emerged as a dominant paradigm for autonomous driving, where recent models often adopt a scoring-selection framework to choose trajectories from a large set of candidates, with diffusion-based decoding showing strong promise. However, directly selecting from the entire candidate space remains difficult to optimize, and Gaussian perturbations used in diffusion often introduce unrealistic trajectories that complicate the denoising process. In addition, for training these models, reinforcement learning (RL) has shown promise, but existing end-to-end RL approaches typically rely on a single coupled reward without structured signals, limiting optimization effectiveness. To address these challenges, we propose HAD, an end-to-end planning framework with a Hierarchical Diffusion Policy that decomposes planning into a coarse-to-fine process. To improve trajectory generation, we introduce Structure-Preserved Trajectory Expansion, which produces realistic candidates while maintaining kinematic structure. For policy learning, we develop Metric-Decoupled Policy Optimization (MDPO) to enable structured RL optimization across multiple driving objectives. Extensive experiments show that HAD achieves new state-of-the-art performance on both NAVSIM and HUGSIM, outperforming prior arts by a huge margin: +2.3 EPDMS on NAVSIM and +4.9 Route Completion on HUGSIM.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
Generalized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025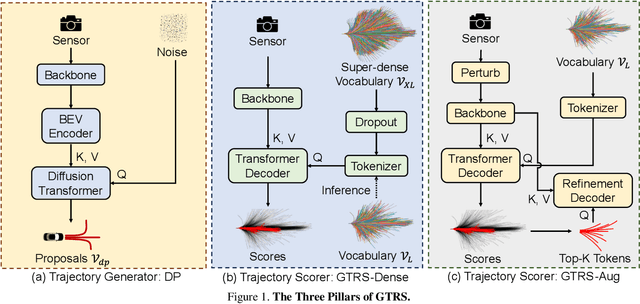

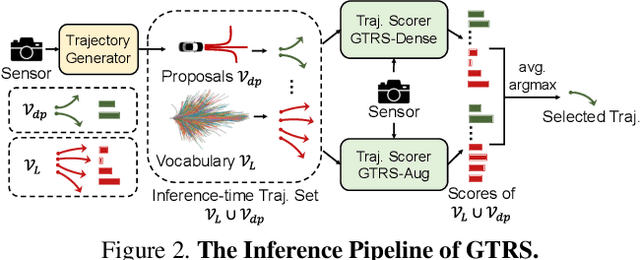
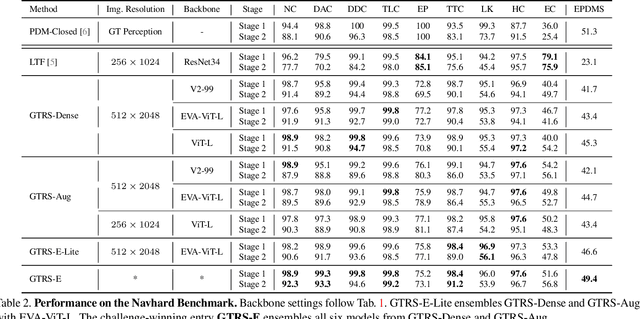
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
DriveSuprim: Towards Precise Trajectory Selection for End-to-End Planning
Jun 07, 2025In complex driving environments, autonomous vehicles must navigate safely. Relying on a single predicted path, as in regression-based approaches, usually does not explicitly assess the safety of the predicted trajectory. Selection-based methods address this by generating and scoring multiple trajectory candidates and predicting the safety score for each, but face optimization challenges in precisely selecting the best option from thousands of possibilities and distinguishing subtle but safety-critical differences, especially in rare or underrepresented scenarios. We propose DriveSuprim to overcome these challenges and advance the selection-based paradigm through a coarse-to-fine paradigm for progressive candidate filtering, a rotation-based augmentation method to improve robustness in out-of-distribution scenarios, and a self-distillation framework to stabilize training. DriveSuprim achieves state-of-the-art performance, reaching 93.5% PDMS in NAVSIM v1 and 87.1% EPDMS in NAVSIM v2 without extra data, demonstrating superior safetycritical capabilities, including collision avoidance and compliance with rules, while maintaining high trajectory quality in various driving scenarios.
MDP: Multidimensional Vision Model Pruning with Latency Constraint
Apr 02, 2025Current structural pruning methods face two significant limitations: (i) they often limit pruning to finer-grained levels like channels, making aggressive parameter reduction challenging, and (ii) they focus heavily on parameter and FLOP reduction, with existing latency-aware methods frequently relying on simplistic, suboptimal linear models that fail to generalize well to transformers, where multiple interacting dimensions impact latency. In this paper, we address both limitations by introducing Multi-Dimensional Pruning (MDP), a novel paradigm that jointly optimizes across a variety of pruning granularities-including channels, query, key, heads, embeddings, and blocks. MDP employs an advanced latency modeling technique to accurately capture latency variations across all prunable dimensions, achieving an optimal balance between latency and accuracy. By reformulating pruning as a Mixed-Integer Nonlinear Program (MINLP), MDP efficiently identifies the optimal pruned structure across all prunable dimensions while respecting latency constraints. This versatile framework supports both CNNs and transformers. Extensive experiments demonstrate that MDP significantly outperforms previous methods, especially at high pruning ratios. On ImageNet, MDP achieves a 28% speed increase with a +1.4 Top-1 accuracy improvement over prior work like HALP for ResNet50 pruning. Against the latest transformer pruning method, Isomorphic, MDP delivers an additional 37% acceleration with a +0.7 Top-1 accuracy improvement.
Target-aware Bidirectional Fusion Transformer for Aerial Object Tracking
Mar 13, 2025The trackers based on lightweight neural networks have achieved great success in the field of aerial remote sensing, most of which aggregate multi-stage deep features to lift the tracking quality. However, existing algorithms usually only generate single-stage fusion features for state decision, which ignore that diverse kinds of features are required for identifying and locating the object, limiting the robustness and precision of tracking. In this paper, we propose a novel target-aware Bidirectional Fusion transformer (BFTrans) for UAV tracking. Specifically, we first present a two-stream fusion network based on linear self and cross attentions, which can combine the shallow and the deep features from both forward and backward directions, providing the adjusted local details for location and global semantics for recognition. Besides, a target-aware positional encoding strategy is designed for the above fusion model, which is helpful to perceive the object-related attributes during the fusion phase. Finally, the proposed method is evaluated on several popular UAV benchmarks, including UAV-123, UAV20L and UAVTrack112. Massive experimental results demonstrate that our approach can exceed other state-of-the-art trackers and run with an average speed of 30.5 FPS on embedded platform, which is appropriate for practical drone deployments.
Enhancing Autonomous Driving Safety with Collision Scenario Integration
Mar 05, 2025Autonomous vehicle safety is crucial for the successful deployment of self-driving cars. However, most existing planning methods rely heavily on imitation learning, which limits their ability to leverage collision data effectively. Moreover, collecting collision or near-collision data is inherently challenging, as it involves risks and raises ethical and practical concerns. In this paper, we propose SafeFusion, a training framework to learn from collision data. Instead of over-relying on imitation learning, SafeFusion integrates safety-oriented metrics during training to enable collision avoidance learning. In addition, to address the scarcity of collision data, we propose CollisionGen, a scalable data generation pipeline to generate diverse, high-quality scenarios using natural language prompts, generative models, and rule-based filtering. Experimental results show that our approach improves planning performance in collision-prone scenarios by 56\% over previous state-of-the-art planners while maintaining effectiveness in regular driving situations. Our work provides a scalable and effective solution for advancing the safety of autonomous driving systems.
Advancing Weight and Channel Sparsification with Enhanced Saliency
Feb 05, 2025



Pruning aims to accelerate and compress models by removing redundant parameters, identified by specifically designed importance scores which are usually imperfect. This removal is irreversible, often leading to subpar performance in pruned models. Dynamic sparse training, while attempting to adjust sparse structures during training for continual reassessment and refinement, has several limitations including criterion inconsistency between pruning and growth, unsuitability for structured sparsity, and short-sighted growth strategies. Our paper introduces an efficient, innovative paradigm to enhance a given importance criterion for either unstructured or structured sparsity. Our method separates the model into an active structure for exploitation and an exploration space for potential updates. During exploitation, we optimize the active structure, whereas in exploration, we reevaluate and reintegrate parameters from the exploration space through a pruning and growing step consistently guided by the same given importance criterion. To prepare for exploration, we briefly "reactivate" all parameters in the exploration space and train them for a few iterations while keeping the active part frozen, offering a preview of the potential performance gains from reintegrating these parameters. We show on various datasets and configurations that existing importance criterion even simple as magnitude can be enhanced with ours to achieve state-of-the-art performance and training cost reductions. Notably, on ImageNet with ResNet50, ours achieves an +1.3 increase in Top-1 accuracy over prior art at 90% ERK sparsity. Compared with the SOTA latency pruning method HALP, we reduced its training cost by over 70% while attaining a faster and more accurate pruned model.
Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Jun 17, 2024As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.