 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDP: Multidimensional Vision Model Pruning with Latency Constraint
Apr 02, 2025Current structural pruning methods face two significant limitations: (i) they often limit pruning to finer-grained levels like channels, making aggressive parameter reduction challenging, and (ii) they focus heavily on parameter and FLOP reduction, with existing latency-aware methods frequently relying on simplistic, suboptimal linear models that fail to generalize well to transformers, where multiple interacting dimensions impact latency. In this paper, we address both limitations by introducing Multi-Dimensional Pruning (MDP), a novel paradigm that jointly optimizes across a variety of pruning granularities-including channels, query, key, heads, embeddings, and blocks. MDP employs an advanced latency modeling technique to accurately capture latency variations across all prunable dimensions, achieving an optimal balance between latency and accuracy. By reformulating pruning as a Mixed-Integer Nonlinear Program (MINLP), MDP efficiently identifies the optimal pruned structure across all prunable dimensions while respecting latency constraints. This versatile framework supports both CNNs and transformers. Extensive experiments demonstrate that MDP significantly outperforms previous methods, especially at high pruning ratios. On ImageNet, MDP achieves a 28% speed increase with a +1.4 Top-1 accuracy improvement over prior work like HALP for ResNet50 pruning. Against the latest transformer pruning method, Isomorphic, MDP delivers an additional 37% acceleration with a +0.7 Top-1 accuracy improvement.
Exploring Camera Encoder Designs for Autonomous Driving Perception
Jul 09, 2024The cornerstone of autonomous vehicles (AV) is a solid perception system, where camera encoders play a crucial role. Existing works usually leverage pre-trained Convolutional Neural Networks (CNN) or Vision Transformers (ViTs) designed for general vision tasks, such as image classification, segmentation, and 2D detection. Although those well-known architectures have achieved state-of-the-art accuracy in AV-related tasks, e.g., 3D Object Detection, there remains significant potential for improvement in network design due to the nuanced complexities of industrial-level AV dataset. Moreover, existing public AV benchmarks usually contain insufficient data, which might lead to inaccurate evaluation of those architectures.To reveal the AV-specific model insights, we start from a standard general-purpose encoder, ConvNeXt and progressively transform the design. We adjust different design parameters including width and depth of the model, stage compute ratio, attention mechanisms, and input resolution, supported by systematic analysis to each modifications. This customization yields an architecture optimized for AV camera encoder achieving 8.79% mAP improvement over the baseline. We believe our effort could become a sweet cookbook of image encoders for AV and pave the way to the next-level drive system.
Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Jun 17, 2024As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
Anomalib: A Deep Learning Library for Anomaly Detection
Feb 16, 2022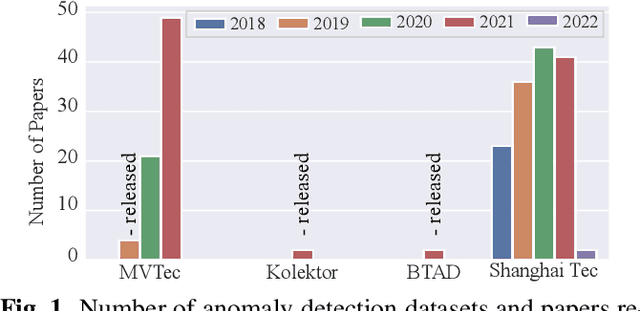

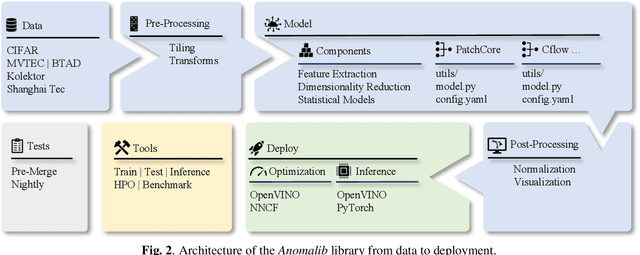

This paper introduces anomalib, a novel library for unsupervised anomaly detection and localization. With reproducibility and modularity in mind, this open-source library provides algorithms from the literature and a set of tools to design custom anomaly detection algorithms via a plug-and-play approach. Anomalib comprises state-of-the-art anomaly detection algorithms that achieve top performance on the benchmarks and that can be used off-the-shelf. In addition, the library provides components to design custom algorithms that could be tailored towards specific needs. Additional tools, including experiment trackers, visualizers, and hyper-parameter optimizers, make it simple to design and implement anomaly detection models. The library also supports OpenVINO model optimization and quantization for real-time deployment. Overall, anomalib is an extensive library for the design, implementation, and deployment of unsupervised anomaly detection models from data to the edge.