 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Academic Benchmarks: Critical Analysis and Best Practices for Visual Industrial Anomaly Detection
Mar 30, 2025Anomaly detection (AD) is essential for automating visual inspection in manufacturing. This field of computer vision is rapidly evolving, with increasing attention towards real-world applications. Meanwhile, popular datasets are typically produced in controlled lab environments with artificially created defects, unable to capture the diversity of real production conditions. New methods often fail in production settings, showing significant performance degradation or requiring impractical computational resources. This disconnect between academic results and industrial viability threatens to misdirect visual anomaly detection research. This paper makes three key contributions: (1) we demonstrate the importance of real-world datasets and establish benchmarks using actual production data, (2) we provide a fair comparison of existing SOTA methods across diverse tasks by utilizing metrics that are valuable for practical applications, and (3) we present a comprehensive analysis of recent advancements in this field by discussing important challenges and new perspectives for bridging the academia-industry gap. The code is publicly available at https://github.com/abc-125/viad-benchmark
Divide and Conquer: High-Resolution Industrial Anomaly Detection via Memory Efficient Tiled Ensemble
Mar 07, 2024Industrial anomaly detection is an important task within computer vision with a wide range of practical use cases. The small size of anomalous regions in many real-world datasets necessitates processing the images at a high resolution. This frequently poses significant challenges concerning memory consumption during the model training and inference stages, leaving some existing methods impractical for widespread adoption. To overcome this challenge, we present the tiled ensemble approach, which reduces memory consumption by dividing the input images into a grid of tiles and training a dedicated model for each tile location. The tiled ensemble is compatible with any existing anomaly detection model without the need for any modification of the underlying architecture. By introducing overlapping tiles, we utilize the benefits of traditional stacking ensembles, leading to further improvements in anomaly detection capabilities beyond high resolution alone. We perform a comprehensive analysis using diverse underlying architectures, including Padim, PatchCore, FastFlow, and Reverse Distillation, on two standard anomaly detection datasets: MVTec and VisA. Our method demonstrates a notable improvement across setups while remaining within GPU memory constraints, consuming only as much GPU memory as a single model needs to process a single tile.
AUPIMO: Redefining Visual Anomaly Detection Benchmarks with High Speed and Low Tolerance
Jan 03, 2024Recent advances in visual anomaly detection research have seen AUROC and AUPRO scores on public benchmark datasets such as MVTec and VisA converge towards perfect recall, giving the impression that these benchmarks are near-solved. However, high AUROC and AUPRO scores do not always reflect qualitative performance, which limits the validity of these metrics in real-world applications. We argue that the artificial ceiling imposed by the lack of an adequate evaluation metric restrains progression of the field, and it is crucial that we revisit the evaluation metrics used to rate our algorithms. In response, we introduce Per-IMage Overlap (PIMO), a novel metric that addresses the shortcomings of AUROC and AUPRO. PIMO retains the recall-based nature of the existing metrics but introduces two distinctions: the assignment of curves (and respective area under the curve) is per-image, and its X-axis relies solely on normal images. Measuring recall per image simplifies instance score indexing and is more robust to noisy annotations. As we show, it also accelerates computation and enables the usage of statistical tests to compare models. By imposing low tolerance for false positives on normal images, PIMO provides an enhanced model validation procedure and highlights performance variations across datasets. Our experiments demonstrate that PIMO offers practical advantages and nuanced performance insights that redefine anomaly detection benchmarks -- notably challenging the perception that MVTec AD and VisA datasets have been solved by contemporary models. Available on GitHub: https://github.com/jpcbertoldo/aupimo.
Anomalib: A Deep Learning Library for Anomaly Detection
Feb 16, 2022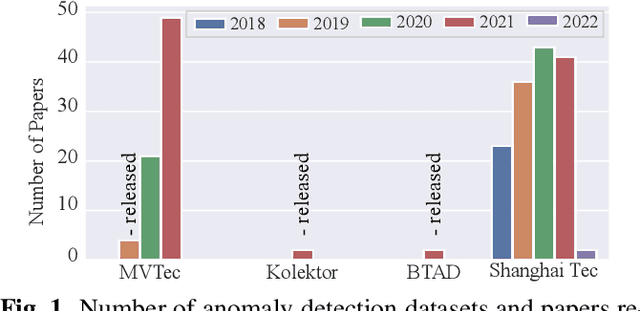

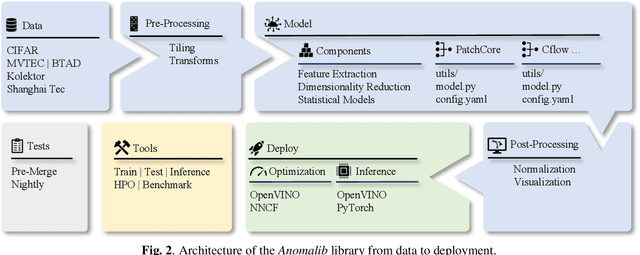

This paper introduces anomalib, a novel library for unsupervised anomaly detection and localization. With reproducibility and modularity in mind, this open-source library provides algorithms from the literature and a set of tools to design custom anomaly detection algorithms via a plug-and-play approach. Anomalib comprises state-of-the-art anomaly detection algorithms that achieve top performance on the benchmarks and that can be used off-the-shelf. In addition, the library provides components to design custom algorithms that could be tailored towards specific needs. Additional tools, including experiment trackers, visualizers, and hyper-parameter optimizers, make it simple to design and implement anomaly detection models. The library also supports OpenVINO model optimization and quantization for real-time deployment. Overall, anomalib is an extensive library for the design, implementation, and deployment of unsupervised anomaly detection models from data to the edge.