 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: High-Resolution Industrial Anomaly Detection via Memory Efficient Tiled Ensemble
Mar 07, 2024Industrial anomaly detection is an important task within computer vision with a wide range of practical use cases. The small size of anomalous regions in many real-world datasets necessitates processing the images at a high resolution. This frequently poses significant challenges concerning memory consumption during the model training and inference stages, leaving some existing methods impractical for widespread adoption. To overcome this challenge, we present the tiled ensemble approach, which reduces memory consumption by dividing the input images into a grid of tiles and training a dedicated model for each tile location. The tiled ensemble is compatible with any existing anomaly detection model without the need for any modification of the underlying architecture. By introducing overlapping tiles, we utilize the benefits of traditional stacking ensembles, leading to further improvements in anomaly detection capabilities beyond high resolution alone. We perform a comprehensive analysis using diverse underlying architectures, including Padim, PatchCore, FastFlow, and Reverse Distillation, on two standard anomaly detection datasets: MVTec and VisA. Our method demonstrates a notable improvement across setups while remaining within GPU memory constraints, consuming only as much GPU memory as a single model needs to process a single tile.
AUPIMO: Redefining Visual Anomaly Detection Benchmarks with High Speed and Low Tolerance
Jan 03, 2024Recent advances in visual anomaly detection research have seen AUROC and AUPRO scores on public benchmark datasets such as MVTec and VisA converge towards perfect recall, giving the impression that these benchmarks are near-solved. However, high AUROC and AUPRO scores do not always reflect qualitative performance, which limits the validity of these metrics in real-world applications. We argue that the artificial ceiling imposed by the lack of an adequate evaluation metric restrains progression of the field, and it is crucial that we revisit the evaluation metrics used to rate our algorithms. In response, we introduce Per-IMage Overlap (PIMO), a novel metric that addresses the shortcomings of AUROC and AUPRO. PIMO retains the recall-based nature of the existing metrics but introduces two distinctions: the assignment of curves (and respective area under the curve) is per-image, and its X-axis relies solely on normal images. Measuring recall per image simplifies instance score indexing and is more robust to noisy annotations. As we show, it also accelerates computation and enables the usage of statistical tests to compare models. By imposing low tolerance for false positives on normal images, PIMO provides an enhanced model validation procedure and highlights performance variations across datasets. Our experiments demonstrate that PIMO offers practical advantages and nuanced performance insights that redefine anomaly detection benchmarks -- notably challenging the perception that MVTec AD and VisA datasets have been solved by contemporary models. Available on GitHub: https://github.com/jpcbertoldo/aupimo.
Exploring Racial Bias within Face Recognition via per-subject Adversarially-Enabled Data Augmentation
Apr 19, 2020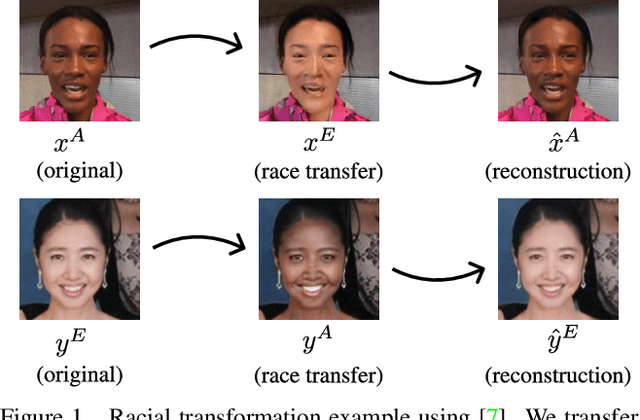
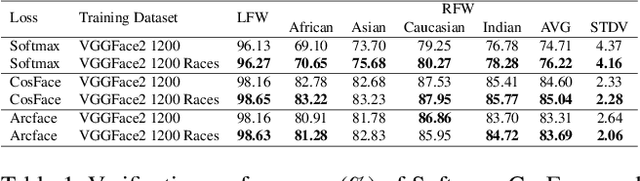
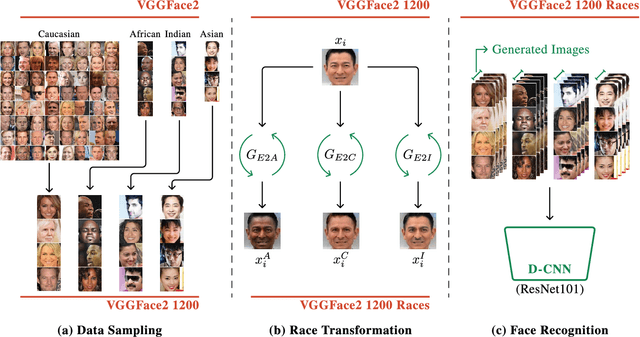

Whilst face recognition applications are becoming increasingly prevalent within our daily lives, leading approaches in the field still suffer from performance bias to the detriment of some racial profiles within society. In this study, we propose a novel adversarial derived data augmentation methodology that aims to enable dataset balance at a per-subject level via the use of image-to-image transformation for the transfer of sensitive racial characteristic facial features. Our aim is to automatically construct a synthesised dataset by transforming facial images across varying racial domains, while still preserving identity-related features, such that racially dependant features subsequently become irrelevant within the determination of subject identity. We construct our experiments on three significant face recognition variants: Softmax, CosFace and ArcFace loss over a common convolutional neural network backbone. In a side-by-side comparison, we show the positive impact our proposed technique can have on the recognition performance for (racial) minority groups within an originally imbalanced training dataset by reducing the pre-race variance in performance.
Multi-Task Learning for Automotive Foggy Scene Understanding via Domain Adaptation to an Illumination-Invariant Representation
Sep 17, 2019
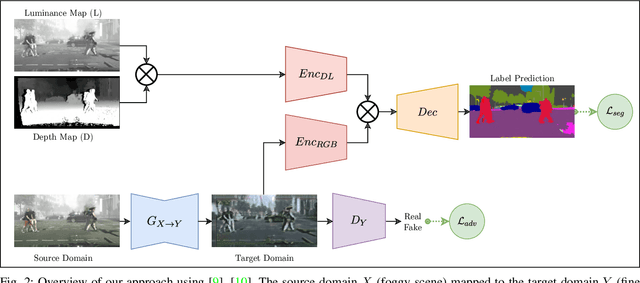
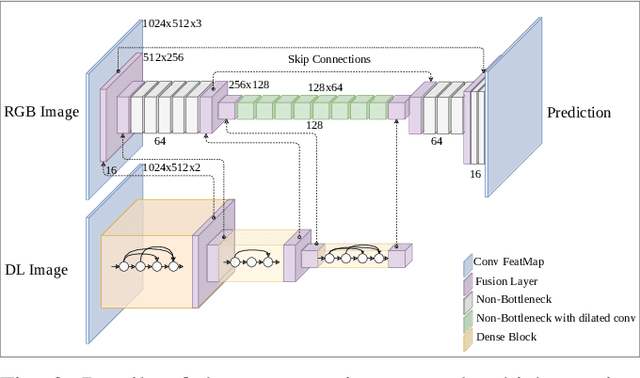

Joint scene understanding and segmentation for automotive applications is a challenging problem in two key aspects:- (1) classifying every pixel in the entire scene and (2) performing this task under unstable weather and illumination changes (e.g. foggy weather), which results in poor outdoor scene visibility. This poor outdoor scene visibility leads to a non-optimal performance of deep convolutional neural network-based scene understanding and segmentation. In this paper, we propose an efficient end-to-end contemporary automotive semantic scene understanding approach under foggy weather conditions, employing domain adaptation and illumination-invariant image per-transformation. As a multi-task pipeline, our proposed model provides:- (1) transferring images from extreme to clear-weather condition using domain transfer approach and (2) semantically segmenting a scene using a competitive encoder-decoder convolutional neural network (CNN) with dense connectivity, skip connections and fusion-based techniques. We evaluate our approach on challenging foggy datasets, including synthetic dataset (Foggy Cityscapes) as well as real-world datasets (Foggy Zurich and Foggy Driving). By incorporating RGB, depth, and illumination-invariant information, our approach outperforms the state-of-the-art within automotive scene understanding, under foggy weather condition.
Evaluation of a Dual Convolutional Neural Network Architecture for Object-wise Anomaly Detection in Cluttered X-ray Security Imagery
Apr 10, 2019
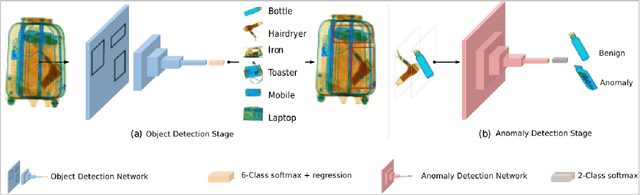
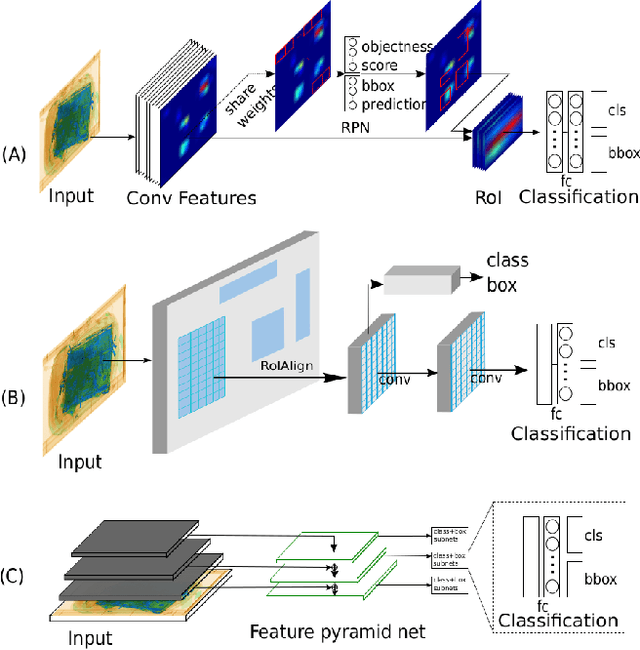
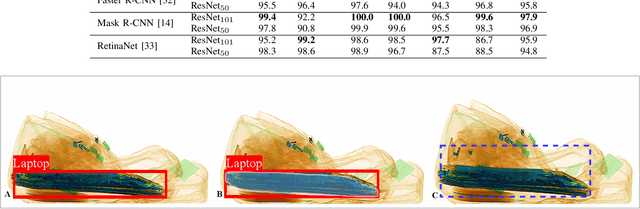
X-ray baggage security screening is widely used to maintain aviation and transport security. Of particular interest is the focus on automated security X-ray analysis for particular classes of object such as electronics, electrical items, and liquids. However, manual inspection of such items is challenging when dealing with potentially anomalous items. Here we present a dual convolutional neural network (CNN) architecture for automatic anomaly detection within complex security X-ray imagery. We leverage recent advances in region-based (R-CNN), mask-based CNN (Mask R-CNN) and detection architectures such as RetinaNet to provide object localisation variants for specific object classes of interest. Subsequently, leveraging a range of established CNN object and fine-grained category classification approaches we formulate within object anomaly detection as a two-class problem (anomalous or benign). While the best performing object localisation method is able to perform with 97.9% mean average precision (mAP) over a six-class X-ray object detection problem, subsequent two-class anomaly/benign classification is able to achieve 66% performance for within object anomaly detection. Overall, this performance illustrates both the challenge and promise of object-wise anomaly detection within the context of cluttered X-ray security imagery.
Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection
Jan 25, 2019
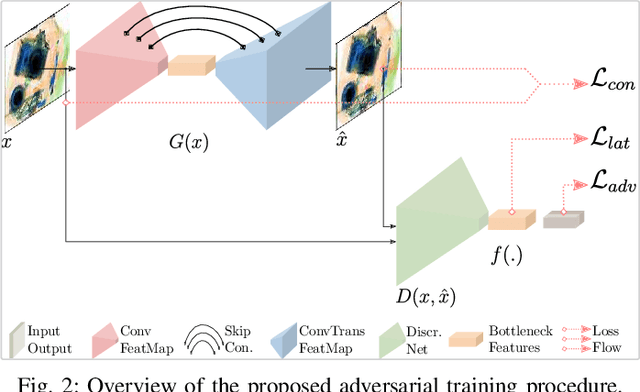
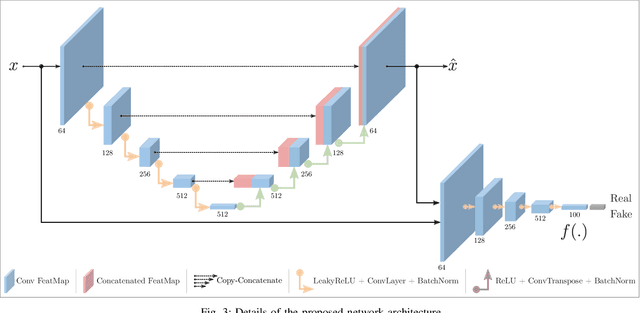
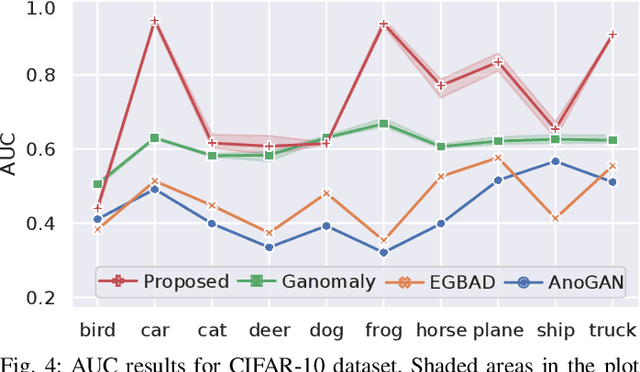
Despite inherent ill-definition, anomaly detection is a research endeavor of great interest within machine learning and visual scene understanding alike. Most commonly, anomaly detection is considered as the detection of outliers within a given data distribution based on some measure of normality. The most significant challenge in real-world anomaly detection problems is that available data is highly imbalanced towards normality (i.e. non-anomalous) and contains a most a subset of all possible anomalous samples - hence limiting the use of well-established supervised learning methods. By contrast, we introduce an unsupervised anomaly detection model, trained only on the normal (non-anomalous, plentiful) samples in order to learn the normality distribution of the domain and hence detect abnormality based on deviation from this model. Our proposed approach employs an encoder-decoder convolutional neural network with skip connections to thoroughly capture the multi-scale distribution of the normal data distribution in high-dimensional image space. Furthermore, utilizing an adversarial training scheme for this chosen architecture provides superior reconstruction both within high-dimensional image space and a lower-dimensional latent vector space encoding. Minimizing the reconstruction error metric within both the image and hidden vector spaces during training aids the model to learn the distribution of normality as required. Higher reconstruction metrics during subsequent test and deployment are thus indicative of a deviation from this normal distribution, hence indicative of an anomaly. Experimentation over established anomaly detection benchmarks and challenging real-world datasets, within the context of X-ray security screening, shows the unique promise of such a proposed approach.