 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKDU at De-Factify 4.0: Vision Transformer with Data Augmentation for AI-Generated Image Detection
Mar 24, 2025The aim of this work is to explore the potential of pre-trained vision-language models, e.g. Vision Transformers (ViT), enhanced with advanced data augmentation strategies for the detection of AI-generated images. Our approach leverages a fine-tuned ViT model trained on the Defactify-4.0 dataset, which includes images generated by state-of-the-art models such as Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and MidJourney. We employ perturbation techniques like flipping, rotation, Gaussian noise injection, and JPEG compression during training to improve model robustness and generalisation. The experimental results demonstrate that our ViT-based pipeline achieves state-of-the-art performance, significantly outperforming competing methods on both validation and test datasets.
Towards Open-World Object-based Anomaly Detection via Self-Supervised Outlier Synthesis
Jul 22, 2024Object detection is a pivotal task in computer vision that has received significant attention in previous years. Nonetheless, the capability of a detector to localise objects out of the training distribution remains unexplored. Whilst recent approaches in object-level out-of-distribution (OoD) detection heavily rely on class labels, such approaches contradict truly open-world scenarios where the class distribution is often unknown. In this context, anomaly detection focuses on detecting unseen instances rather than classifying detections as OoD. This work aims to bridge this gap by leveraging an open-world object detector and an OoD detector via virtual outlier synthesis. This is achieved by using the detector backbone features to first learn object pseudo-classes via self-supervision. These pseudo-classes serve as the basis for class-conditional virtual outlier sampling of anomalous features that are classified by an OoD head. Our approach empowers our overall object detector architecture to learn anomaly-aware feature representations without relying on class labels, hence enabling truly open-world object anomaly detection. Empirical validation of our approach demonstrates its effectiveness across diverse datasets encompassing various imaging modalities (visible, infrared, and X-ray). Moreover, our method establishes state-of-the-art performance on object-level anomaly detection, achieving an average recall score improvement of over 5.4% for natural images and 23.5% for a security X-ray dataset compared to the current approaches. In addition, our method detects anomalies in datasets where current approaches fail. Code available at https://github.com/KostadinovShalon/oln-ssos.
Performance Evaluation of Segment Anything Model with Variational Prompting for Application to Non-Visible Spectrum Imagery
Apr 18, 2024



The Segment Anything Model (SAM) is a deep neural network foundational model designed to perform instance segmentation which has gained significant popularity given its zero-shot segmentation ability. SAM operates by generating masks based on various input prompts such as text, bounding boxes, points, or masks, introducing a novel methodology to overcome the constraints posed by dataset-specific scarcity. While SAM is trained on an extensive dataset, comprising ~11M images, it mostly consists of natural photographic images with only very limited images from other modalities. Whilst the rapid progress in visual infrared surveillance and X-ray security screening imaging technologies, driven forward by advances in deep learning, has significantly enhanced the ability to detect, classify and segment objects with high accuracy, it is not evident if the SAM zero-shot capabilities can be transferred to such modalities. This work assesses SAM capabilities in segmenting objects of interest in the X-ray/infrared modalities. Our approach reuses the pre-trained SAM with three different prompts: bounding box, centroid and random points. We present quantitative/qualitative results to showcase the performance on selected datasets. Our results show that SAM can segment objects in the X-ray modality when given a box prompt, but its performance varies for point prompts. Specifically, SAM performs poorly in segmenting slender objects and organic materials, such as plastic bottles. We find that infrared objects are also challenging to segment with point prompts given the low-contrast nature of this modality. This study shows that while SAM demonstrates outstanding zero-shot capabilities with box prompts, its performance ranges from moderate to poor for point prompts, indicating that special consideration on the cross-modal generalisation of SAM is needed when considering use on X-ray/infrared imagery.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023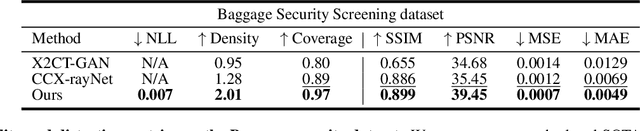
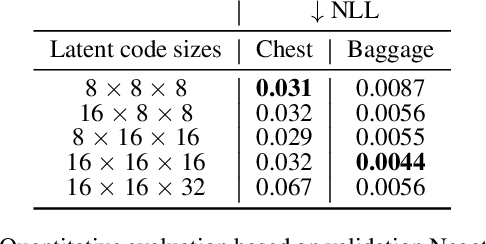

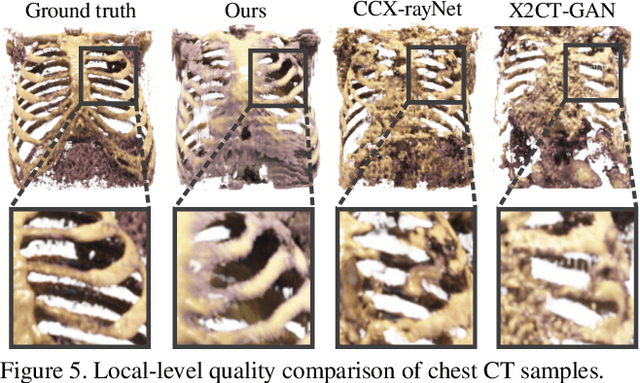
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
Robust Semi-Supervised Anomaly Detection via Adversarially Learned Continuous Noise Corruption
Mar 02, 2023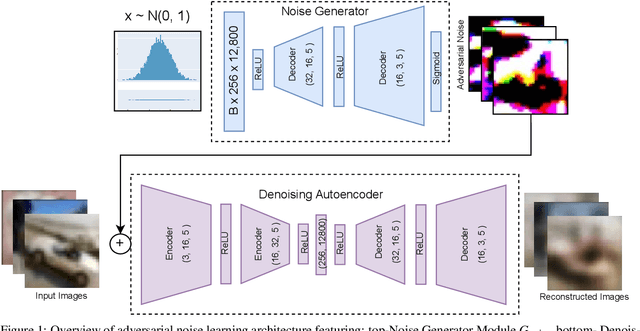
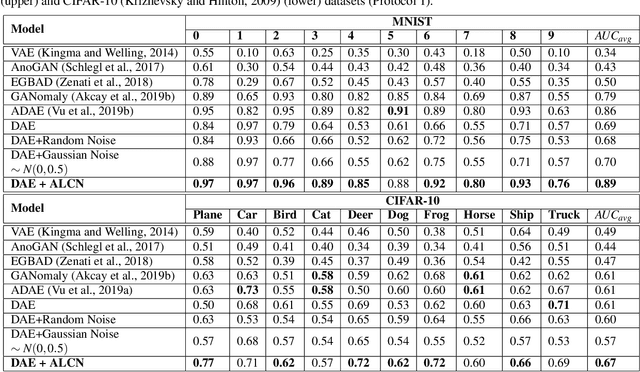
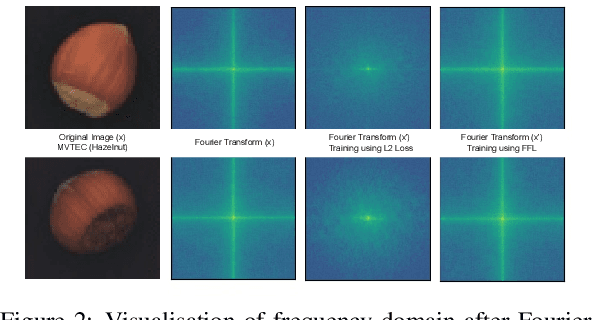
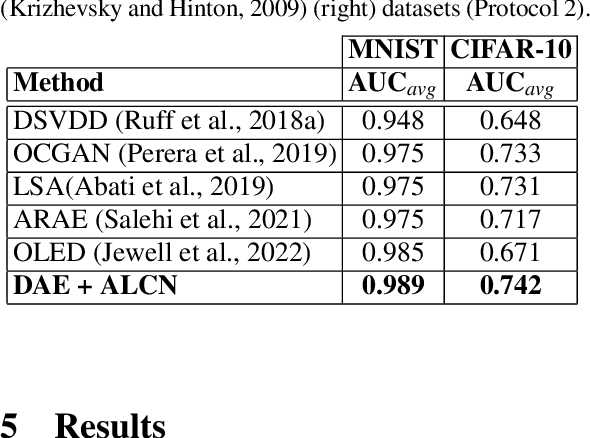
Anomaly detection is the task of recognising novel samples which deviate significantly from pre-establishednormality. Abnormal classes are not present during training meaning that models must learn effective rep-resentations solely across normal class data samples. Deep Autoencoders (AE) have been widely used foranomaly detection tasks, but suffer from overfitting to a null identity function. To address this problem, weimplement a training scheme applied to a Denoising Autoencoder (DAE) which introduces an efficient methodof producing Adversarially Learned Continuous Noise (ALCN) to maximally globally corrupt the input priorto denoising. Prior methods have applied similar approaches of adversarial training to increase the robustnessof DAE, however they exhibit limitations such as slow inference speed reducing their real-world applicabilityor producing generalised obfuscation which is more trivial to denoise. We show through rigorous evaluationthat our ALCN method of regularisation during training improves AUC performance during inference whileremaining efficient over both classical, leave-one-out novelty detection tasks with the variations-: 9 (normal)vs. 1 (abnormal) & 1 (normal) vs. 9 (abnormal); MNIST - AUCavg: 0.890 & 0.989, CIFAR-10 - AUCavg: 0.670& 0.742, in addition to challenging real-world anomaly detection tasks: industrial inspection (MVTEC-AD -AUCavg: 0.780) and plant disease detection (Plant Village - AUC: 0.770) when compared to prior approaches.
* 18th International Conference on Computer Vision Theory and Applications
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

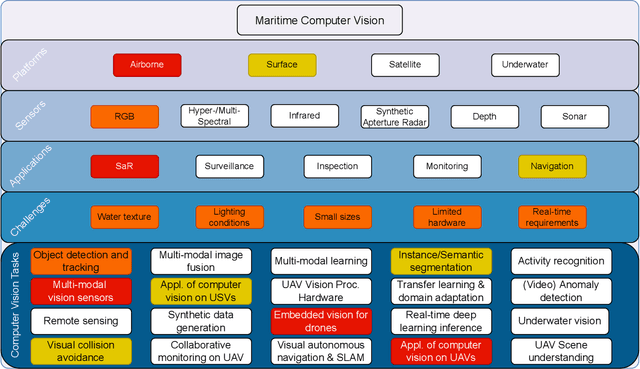
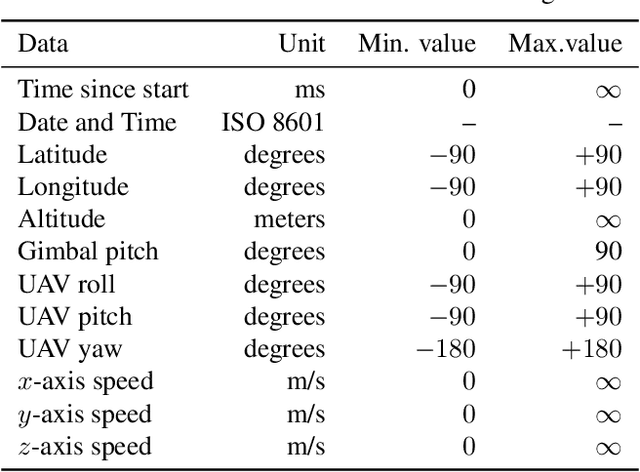
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Detecting Anomalies using Generative Adversarial Networks on Images
Nov 24, 2022

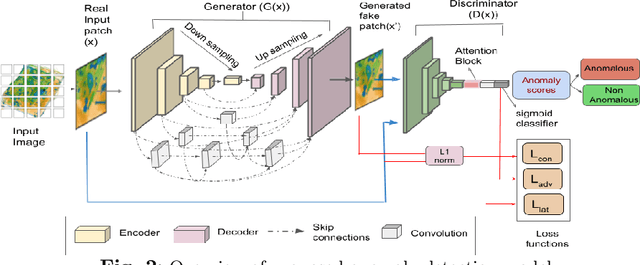
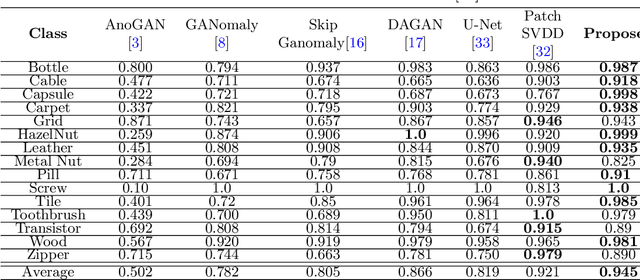
Automatic detection of anomalies such as weapons or threat objects in baggage security, or detecting impaired items in industrial production is an important computer vision task demanding high efficiency and accuracy. Most of the available data in the anomaly detection task is imbalanced as the number of positive/anomalous instances is sparse. Inadequate availability of the data makes training of a deep neural network architecture for anomaly detection challenging. This paper proposes a novel Generative Adversarial Network (GAN) based model for anomaly detection. It uses normal (non-anomalous) images to learn about the normality based on which it detects if an input image contains an anomalous/threat object. The proposed model uses a generator with an encoder-decoder network having dense convolutional skip connections for enhanced reconstruction and to capture the data distribution. A self-attention augmented discriminator is used having the ability to check the consistency of detailed features even in distant portions. We use spectral normalisation to facilitate stable and improved training of the GAN. Experiments are performed on three datasets, viz. CIFAR-10, MVTec AD (for industrial applications) and SIXray (for X-ray baggage security). On the MVTec AD and SIXray datasets, our model achieves an improvement of upto 21% and 4.6%, respectively
Joint Sub-component Level Segmentation and Classification for Anomaly Detection within Dual-Energy X-Ray Security Imagery
Oct 29, 2022X-ray baggage security screening is in widespread use and crucial to maintaining transport security for threat/anomaly detection tasks. The automatic detection of anomaly, which is concealed within cluttered and complex electronics/electrical items, using 2D X-ray imagery is of primary interest in recent years. We address this task by introducing joint object sub-component level segmentation and classification strategy using deep Convolution Neural Network architecture. The performance is evaluated over a dataset of cluttered X-ray baggage security imagery, consisting of consumer electrical and electronics items using variants of dual-energy X-ray imagery (pseudo-colour, high, low, and effective-Z). The proposed joint sub-component level segmentation and classification approach achieve ~99% true positive and ~5% false positive for anomaly detection task.
Lost in Compression: the Impact of Lossy Image Compression on Variable Size Object Detection within Infrared Imagery
May 16, 2022



Lossy image compression strategies allow for more efficient storage and transmission of data by encoding data to a reduced form. This is essential enable training with larger datasets on less storage-equipped environments. However, such compression can cause severe decline in performance of deep Convolution Neural Network (CNN) architectures even when mild compression is applied and the resulting compressed imagery is visually identical. In this work, we apply the lossy JPEG compression method with six discrete levels of increasing compression {95, 75, 50, 15, 10, 5} to infrared band (thermal) imagery. Our study quantitatively evaluates the affect that increasing levels of lossy compression has upon the performance of characteristically diverse object detection architectures (Cascade-RCNN, FSAF and Deformable DETR) with respect to varying sizes of objects present in the dataset. When training and evaluating on uncompressed data as a baseline, we achieve maximal mean Average Precision (mAP) of 0.823 with Cascade R-CNN across the FLIR dataset, outperforming prior work. The impact of the lossy compression is more extreme at higher compression levels (15, 10, 5) across all three CNN architectures. However, re-training models on lossy compressed imagery notably ameliorated performances for all three CNN models with an average increment of ~76% (at higher compression level 5). Additionally, we demonstrate the relative sensitivity of differing object areas {tiny, small, medium, large} with respect to the compression level. We show that tiny and small objects are more sensitive to compression than medium and large objects. Overall, Cascade R-CNN attains the maximal mAP across most of the object area categories.
Semi-Supervised Surface Anomaly Detection of Composite Wind Turbine Blades From Drone Imagery
Dec 01, 2021
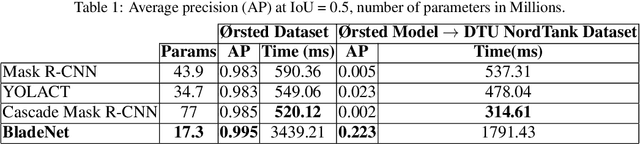
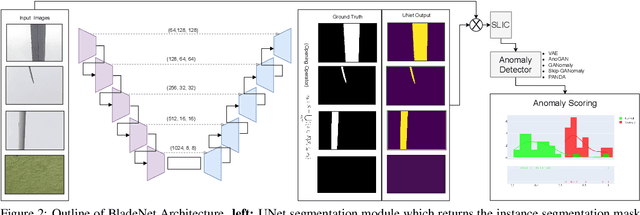

Within commercial wind energy generation, the monitoring and predictive maintenance of wind turbine blades in-situ is a crucial task, for which remote monitoring via aerial survey from an Unmanned Aerial Vehicle (UAV) is commonplace. Turbine blades are susceptible to both operational and weather-based damage over time, reducing the energy efficiency output of turbines. In this study, we address automating the otherwise time-consuming task of both blade detection and extraction, together with fault detection within UAV-captured turbine blade inspection imagery. We propose BladeNet, an application-based, robust dual architecture to perform both unsupervised turbine blade detection and extraction, followed by super-pixel generation using the Simple Linear Iterative Clustering (SLIC) method to produce regional clusters. These clusters are then processed by a suite of semi-supervised detection methods. Our dual architecture detects surface faults of glass fibre composite material blades with high aptitude while requiring minimal prior manual image annotation. BladeNet produces an Average Precision (AP) of 0.995 across our {\O}rsted blade inspection dataset for offshore wind turbines and 0.223 across the Danish Technical University (DTU) NordTank turbine blade inspection dataset. BladeNet also obtains an AUC of 0.639 for surface anomaly detection across the {\O}rsted blade inspection dataset.