 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKDU at De-Factify 4.0: Natural Language Features for AI-Generated Text-Detection
Mar 28, 2025



The rapid advancement of large language models (LLMs) has introduced new challenges in distinguishing human-written text from AI-generated content. In this work, we explored a pipelined approach for AI-generated text detection that includes a feature extraction step (i.e. prompt-based rewriting features inspired by RAIDAR and content-based features derived from the NELA toolkit) followed by a classification module. Comprehensive experiments were conducted on the Defactify4.0 dataset, evaluating two tasks: binary classification to differentiate human-written and AI-generated text, and multi-class classification to identify the specific generative model used to generate the input text. Our findings reveal that NELA features significantly outperform RAIDAR features in both tasks, demonstrating their ability to capture nuanced linguistic, stylistic, and content-based differences. Combining RAIDAR and NELA features provided minimal improvement, highlighting the redundancy introduced by less discriminative features. Among the classifiers tested, XGBoost emerged as the most effective, leveraging the rich feature sets to achieve high accuracy and generalisation.
SKDU at De-Factify 4.0: Vision Transformer with Data Augmentation for AI-Generated Image Detection
Mar 24, 2025The aim of this work is to explore the potential of pre-trained vision-language models, e.g. Vision Transformers (ViT), enhanced with advanced data augmentation strategies for the detection of AI-generated images. Our approach leverages a fine-tuned ViT model trained on the Defactify-4.0 dataset, which includes images generated by state-of-the-art models such as Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and MidJourney. We employ perturbation techniques like flipping, rotation, Gaussian noise injection, and JPEG compression during training to improve model robustness and generalisation. The experimental results demonstrate that our ViT-based pipeline achieves state-of-the-art performance, significantly outperforming competing methods on both validation and test datasets.
Structural Analysis of Hindi Phonetics and A Method for Extraction of Phonetically Rich Sentences from a Very Large Hindi Text Corpus
Feb 07, 2017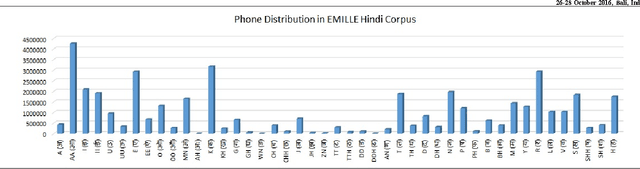



Automatic speech recognition (ASR) and Text to speech (TTS) are two prominent area of research in human computer interaction nowadays. A set of phonetically rich sentences is in a matter of importance in order to develop these two interactive modules of HCI. Essentially, the set of phonetically rich sentences has to cover all possible phone units distributed uniformly. Selecting such a set from a big corpus with maintaining phonetic characteristic based similarity is still a challenging problem. The major objective of this paper is to devise a criteria in order to select a set of sentences encompassing all phonetic aspects of a corpus with size as minimum as possible. First, this paper presents a statistical analysis of Hindi phonetics by observing the structural characteristics. Further a two stage algorithm is proposed to extract phonetically rich sentences with a high variety of triphones from the EMILLE Hindi corpus. The algorithm consists of a distance measuring criteria to select a sentence in order to improve the triphone distribution. Moreover, a special preprocessing method is proposed to score each triphone in terms of inverse probability in order to fasten the algorithm. The results show that the approach efficiently build uniformly distributed phonetically-rich corpus with optimum number of sentences.
A Hybrid Approach For Hindi-English Machine Translation
Feb 06, 2017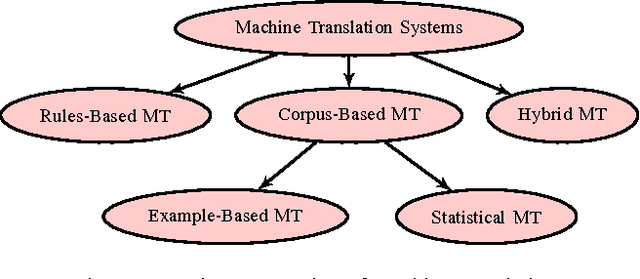
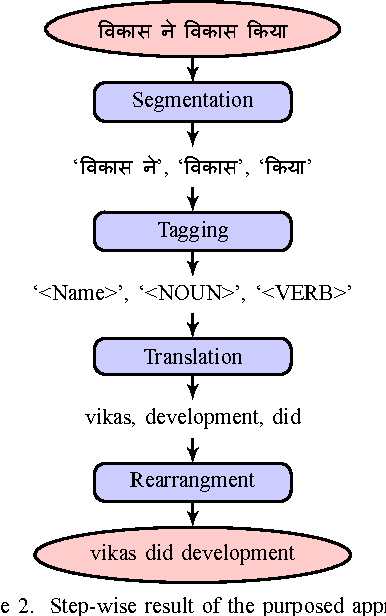
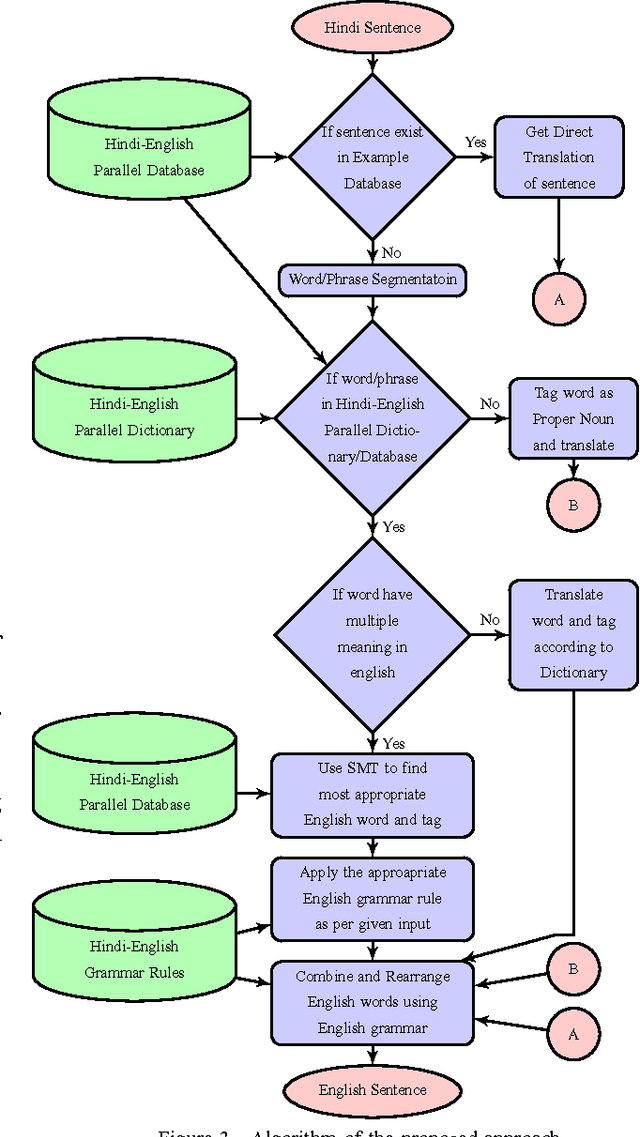

In this paper, an extended combined approach of phrase based statistical machine translation (SMT), example based MT (EBMT) and rule based MT (RBMT) is proposed to develop a novel hybrid data driven MT system capable of outperforming the baseline SMT, EBMT and RBMT systems from which it is derived. In short, the proposed hybrid MT process is guided by the rule based MT after getting a set of partial candidate translations provided by EBMT and SMT subsystems. Previous works have shown that EBMT systems are capable of outperforming the phrase-based SMT systems and RBMT approach has the strength of generating structurally and morphologically more accurate results. This hybrid approach increases the fluency, accuracy and grammatical precision which improve the quality of a machine translation system. A comparison of the proposed hybrid machine translation (HTM) model with renowned translators i.e. Google, BING and Babylonian is also presented which shows that the proposed model works better on sentences with ambiguity as well as comprised of idioms than others.