 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Feature Scaling of Recursive Feature Machines
Mar 28, 2023

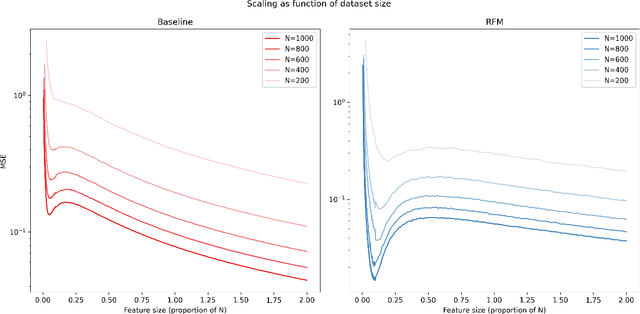

In this technical report, we explore the behavior of Recursive Feature Machines (RFMs), a type of novel kernel machine that recursively learns features via the average gradient outer product, through a series of experiments on regression datasets. When successively adding random noise features to a dataset, we observe intriguing patterns in the Mean Squared Error (MSE) curves with the test MSE exhibiting a decrease-increase-decrease pattern. This behavior is consistent across different dataset sizes, noise parameters, and target functions. Interestingly, the observed MSE curves show similarities to the "double descent" phenomenon observed in deep neural networks, hinting at new connection between RFMs and neural network behavior. This report lays the groundwork for future research into this peculiar behavior.
Structural Analysis of Hindi Phonetics and A Method for Extraction of Phonetically Rich Sentences from a Very Large Hindi Text Corpus
Feb 07, 2017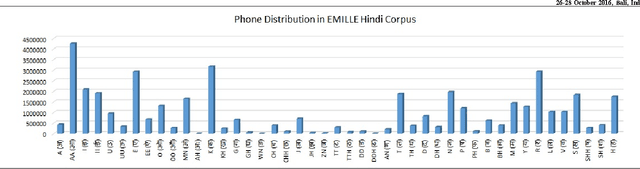



Automatic speech recognition (ASR) and Text to speech (TTS) are two prominent area of research in human computer interaction nowadays. A set of phonetically rich sentences is in a matter of importance in order to develop these two interactive modules of HCI. Essentially, the set of phonetically rich sentences has to cover all possible phone units distributed uniformly. Selecting such a set from a big corpus with maintaining phonetic characteristic based similarity is still a challenging problem. The major objective of this paper is to devise a criteria in order to select a set of sentences encompassing all phonetic aspects of a corpus with size as minimum as possible. First, this paper presents a statistical analysis of Hindi phonetics by observing the structural characteristics. Further a two stage algorithm is proposed to extract phonetically rich sentences with a high variety of triphones from the EMILLE Hindi corpus. The algorithm consists of a distance measuring criteria to select a sentence in order to improve the triphone distribution. Moreover, a special preprocessing method is proposed to score each triphone in terms of inverse probability in order to fasten the algorithm. The results show that the approach efficiently build uniformly distributed phonetically-rich corpus with optimum number of sentences.