 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Emotion Tracker: AI-Driven Continuous Mood and Emotion Monitoring
Jan 24, 2024This research project aims to tackle the growing mental health challenges in today's digital age. It employs a modified pre-trained BERT model to detect depressive text within social media and users' web browsing data, achieving an impressive 93% test accuracy. Simultaneously, the project aims to incorporate physiological signals from wearable devices, such as smartwatches and EEG sensors, to provide long-term tracking and prognosis of mood disorders and emotional states. This comprehensive approach holds promise for enhancing early detection of depression and advancing overall mental health outcomes.
Inter Subject Emotion Recognition Using Spatio-Temporal Features From EEG Signal
May 27, 2023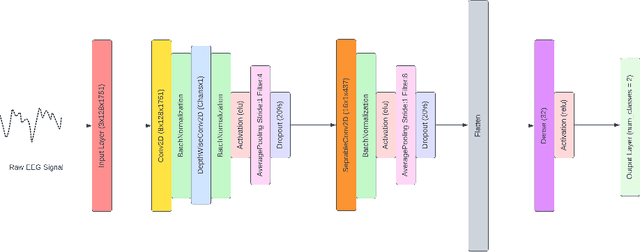

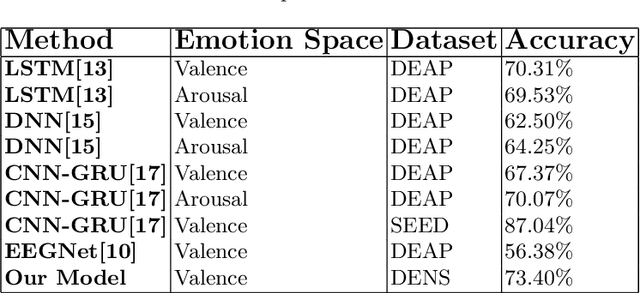
Inter-subject or subject-independent emotion recognition has been a challenging task in affective computing. This work is about an easy-to-implement emotion recognition model that classifies emotions from EEG signals subject independently. It is based on the famous EEGNet architecture, which is used in EEG-related BCIs. We used the Dataset on Emotion using Naturalistic Stimuli (DENS) dataset. The dataset contains the Emotional Events -- the precise information of the emotion timings that participants felt. The model is a combination of regular, depthwise and separable convolution layers of CNN to classify the emotions. The model has the capacity to learn the spatial features of the EEG channels and the temporal features of the EEG signals variability with time. The model is evaluated for the valence space ratings. The model achieved an accuracy of 73.04%.
Emotion Recognition With Temporarily Localized 'Emotional Events' in Naturalistic Context
Oct 25, 2022



Emotion recognition using EEG signals is an emerging area of research due to its broad applicability in BCI. Emotional feelings are hard to stimulate in the lab. Emotions do not last long, yet they need enough context to be perceived and felt. However, most EEG-related emotion databases either suffer from emotionally irrelevant details (due to prolonged duration stimulus) or have minimal context doubting the feeling of any emotion using the stimulus. We tried to reduce the impact of this trade-off by designing an experiment in which participants are free to report their emotional feelings simultaneously watching the emotional stimulus. We called these reported emotional feelings "Emotional Events" in our Dataset on Emotion with Naturalistic Stimuli (DENS). We used EEG signals to classify emotional events on different combinations of Valence(V) and Arousal(A) dimensions and compared the results with benchmark datasets of DEAP and SEED. STFT is used for feature extraction and used in the classification model consisting of CNN-LSTM hybrid layers. We achieved significantly higher accuracy with our data compared to DEEP and SEED data. We conclude that having precise information about emotional feelings improves the classification accuracy compared to long-duration EEG signals which might be contaminated by mind-wandering.
An Affective Video Database using Multimedia Content Analysis rated on Indian samples
Oct 18, 2022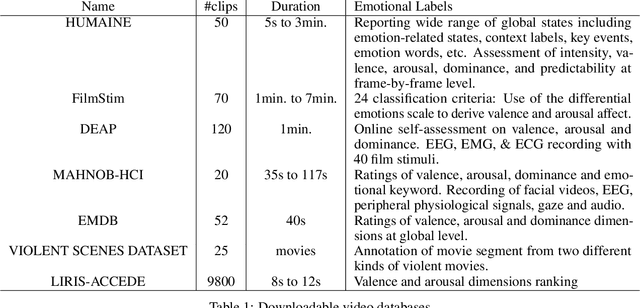
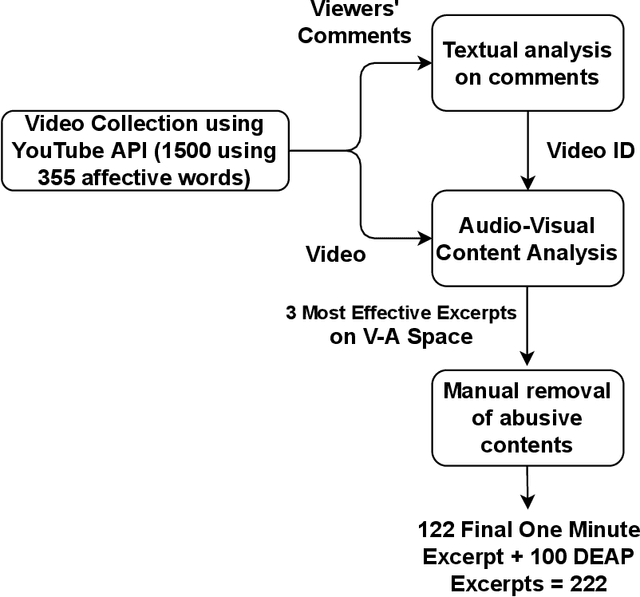
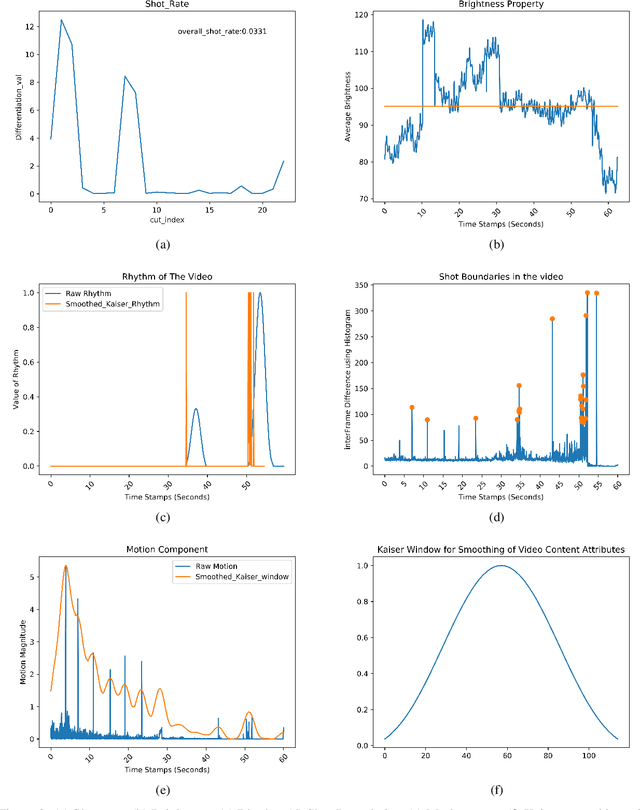
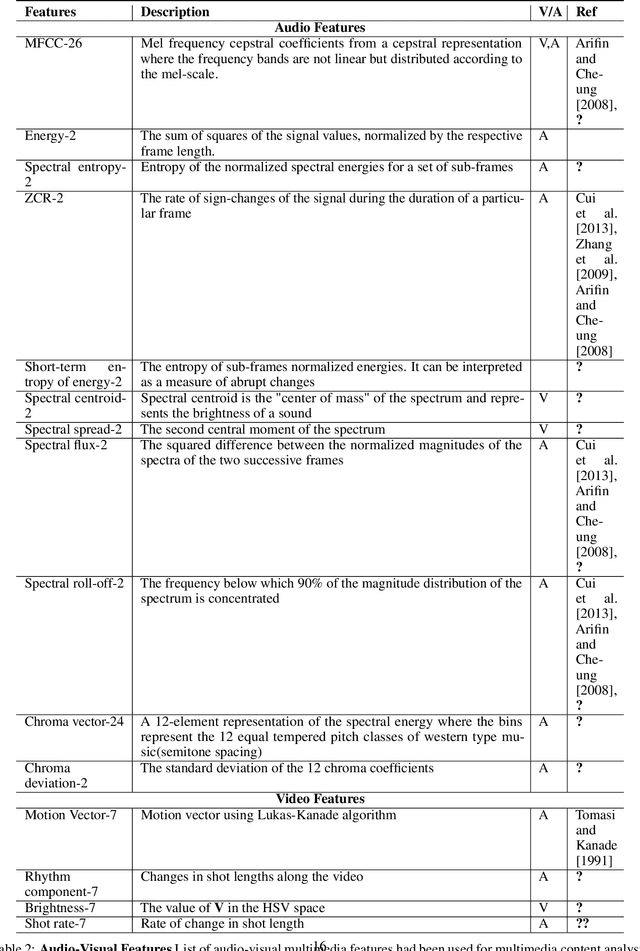
Availability of naturalistic affective stimuli is needed for creating the affective technological solution as well as making progress in affective science. Although a lot of progress in the collection of affective multimedia stimuli has been made in western countries, the technology and findings based on such monocultural datasets may not be scalable to other cultures. Moreover, the available dataset on affective multimedia content has some experimenter bias in the initial manual selection of affective multimedia content. Hence, in this work, we mainly tried to address two problems. The first problem relates to the experimenter's subjective bias, and the second relates to the non-availability of affective multimedia dataset validated on Indian population. We tried to address both problems by reducing the experimenter's bias as much as possible. We adopted the data science and multimedia content analysis techniques to perform our initial collection and a further selection of stimuli. Our method resulted in a dataset with a wide variety in content, stimuli from Western and Indian cinema, and symmetric presence of stimuli along valence, arousal and dominance dimensions. We conclude that using our method, more cross-cultural affective stimuli datasets can be created, which is essential to make progress in affective technology and science.
Real-time Emotion and Gender Classification using Ensemble CNN
Nov 15, 2021

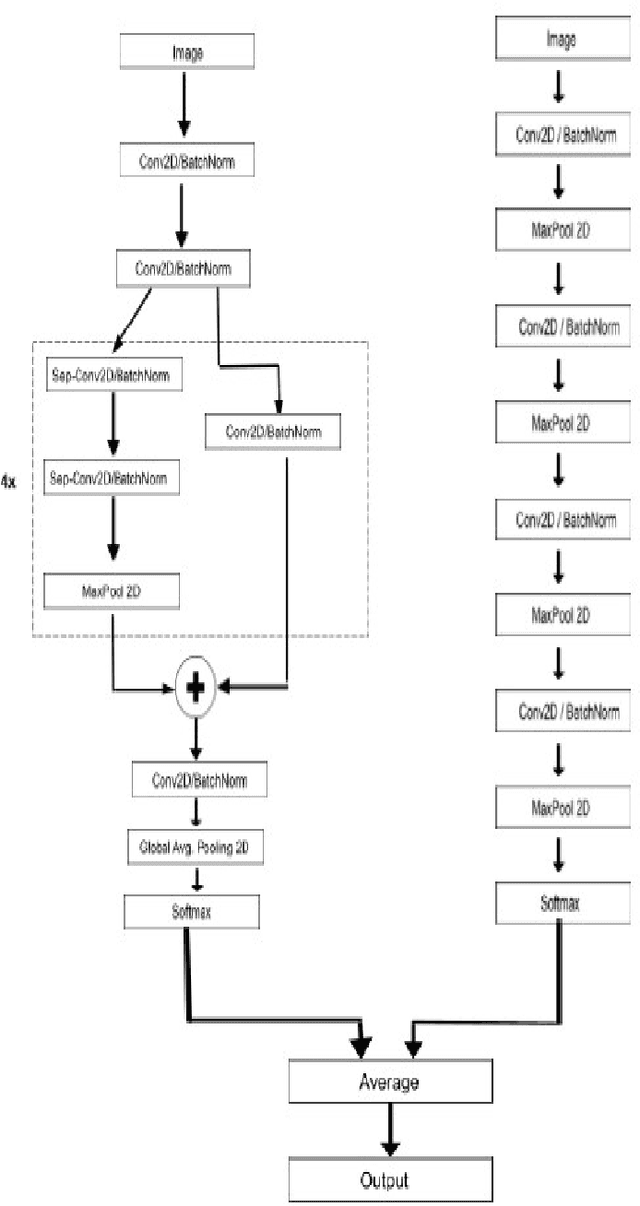
Analysing expressions on the person's face plays a very vital role in identifying emotions and behavior of a person. Recognizing these expressions automatically results in a crucial component of natural human-machine interfaces. Therefore research in this field has a wide range of applications in bio-metric authentication, surveillance systems , emotion to emoticons in various social media platforms. Another application includes conducting customer satisfaction surveys. As we know that the large corporations made huge investments to get feedback and do surveys but fail to get equitable responses. Emotion & Gender recognition through facial gestures is a technology that aims to improve product and services performance by monitoring customer behavior to specific products or service staff by their evaluation. In the past few years there have been a wide variety of advances performed in terms of feature extraction mechanisms , detection of face and also expression classification techniques. This paper is the implementation of an Ensemble CNN for building a real-time system that can detect emotion and gender of the person. The experimental results shows accuracy of 68% for Emotion classification into 7 classes (angry, fear , sad , happy , surprise , neutral , disgust) on FER-2013 dataset and 95% for Gender classification (Male or Female) on IMDB dataset. Our work can predict emotion and gender on single face images as well as multiple face images. Also when input is given through webcam our complete pipeline of this real-time system can take less than 0.5 seconds to generate results.
Analyzing Effect of Repeated Reading on Oral Fluency and Narrative Production for Computer-Assisted Language Learning
Jun 25, 2020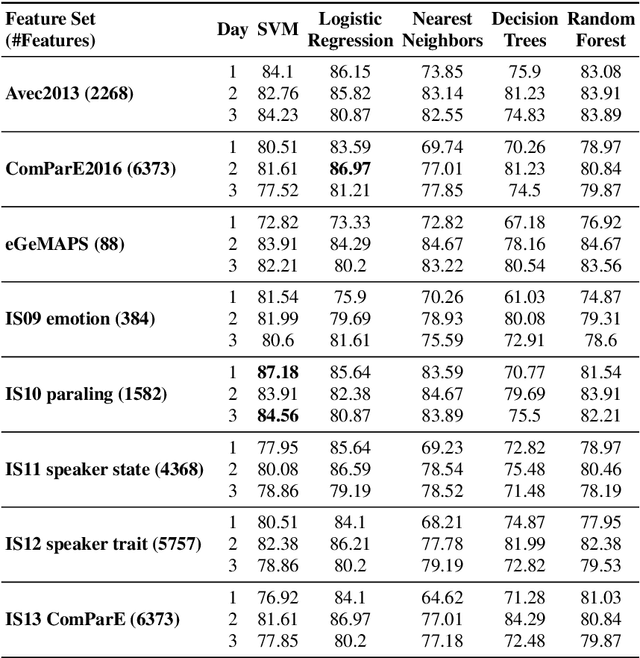
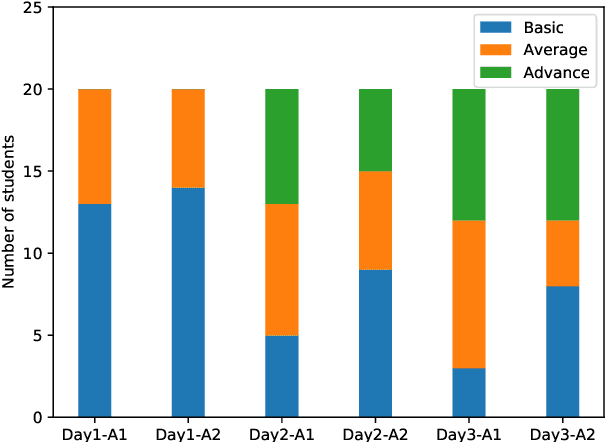
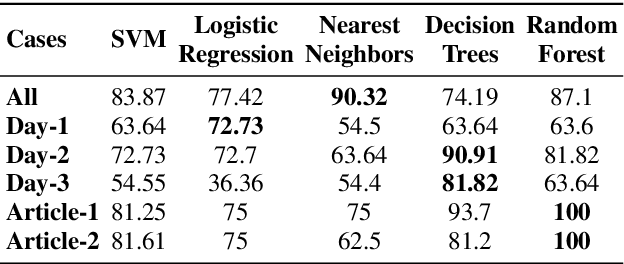
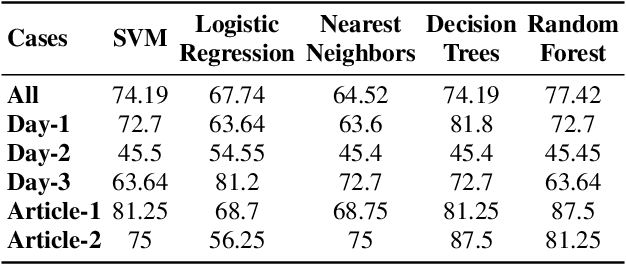
Repeated reading (RR) helps learners, who have little to no experience with reading fluently to gain confidence, speed and process words automatically. The benefits of repeated readings include helping all learners with fact recall, aiding identification of learners' main ideas and vocabulary, increasing comprehension, leading to faster reading as well as increasing word recognition accuracy, and assisting struggling learners as they transition from word-by-word reading to more meaningful phrasing. Thus, RR ultimately helps in improvements of learners' oral fluency and narrative production. However, there are no open audio datasets available on oral responses of learners based on their RR practices. Therefore, in this paper, we present our dataset, discuss its properties, and propose a method to assess oral fluency and narrative production for learners of English using acoustic, prosodic, lexical and syntactical characteristics. The results show that a CALL system can be developed for assessing the improvements in learners' oral fluency and narrative production.
Structural Analysis of Hindi Phonetics and A Method for Extraction of Phonetically Rich Sentences from a Very Large Hindi Text Corpus
Feb 07, 2017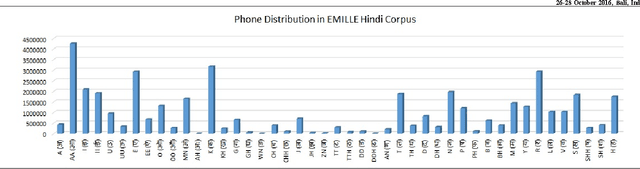



Automatic speech recognition (ASR) and Text to speech (TTS) are two prominent area of research in human computer interaction nowadays. A set of phonetically rich sentences is in a matter of importance in order to develop these two interactive modules of HCI. Essentially, the set of phonetically rich sentences has to cover all possible phone units distributed uniformly. Selecting such a set from a big corpus with maintaining phonetic characteristic based similarity is still a challenging problem. The major objective of this paper is to devise a criteria in order to select a set of sentences encompassing all phonetic aspects of a corpus with size as minimum as possible. First, this paper presents a statistical analysis of Hindi phonetics by observing the structural characteristics. Further a two stage algorithm is proposed to extract phonetically rich sentences with a high variety of triphones from the EMILLE Hindi corpus. The algorithm consists of a distance measuring criteria to select a sentence in order to improve the triphone distribution. Moreover, a special preprocessing method is proposed to score each triphone in terms of inverse probability in order to fasten the algorithm. The results show that the approach efficiently build uniformly distributed phonetically-rich corpus with optimum number of sentences.
A Hybrid Approach For Hindi-English Machine Translation
Feb 06, 2017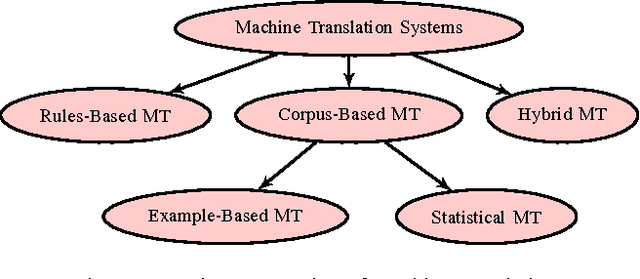
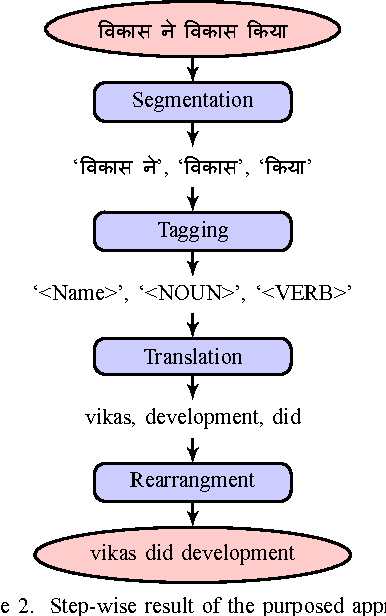
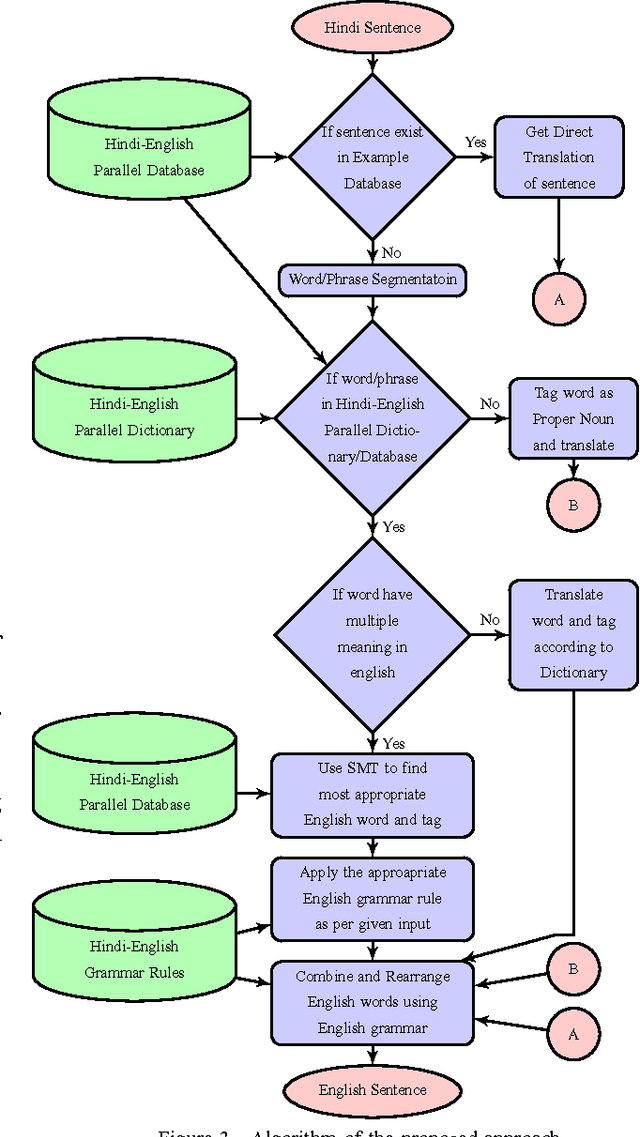

In this paper, an extended combined approach of phrase based statistical machine translation (SMT), example based MT (EBMT) and rule based MT (RBMT) is proposed to develop a novel hybrid data driven MT system capable of outperforming the baseline SMT, EBMT and RBMT systems from which it is derived. In short, the proposed hybrid MT process is guided by the rule based MT after getting a set of partial candidate translations provided by EBMT and SMT subsystems. Previous works have shown that EBMT systems are capable of outperforming the phrase-based SMT systems and RBMT approach has the strength of generating structurally and morphologically more accurate results. This hybrid approach increases the fluency, accuracy and grammatical precision which improve the quality of a machine translation system. A comparison of the proposed hybrid machine translation (HTM) model with renowned translators i.e. Google, BING and Babylonian is also presented which shows that the proposed model works better on sentences with ambiguity as well as comprised of idioms than others.