 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Affective Video Database using Multimedia Content Analysis rated on Indian samples
Paper and Code
Oct 18, 2022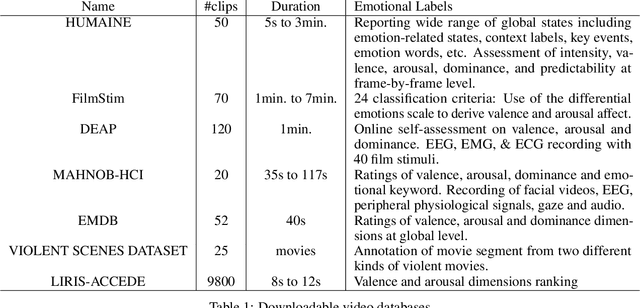
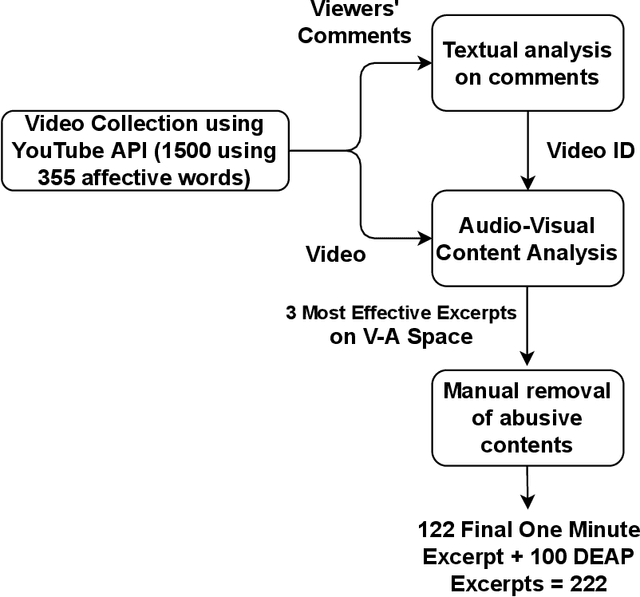
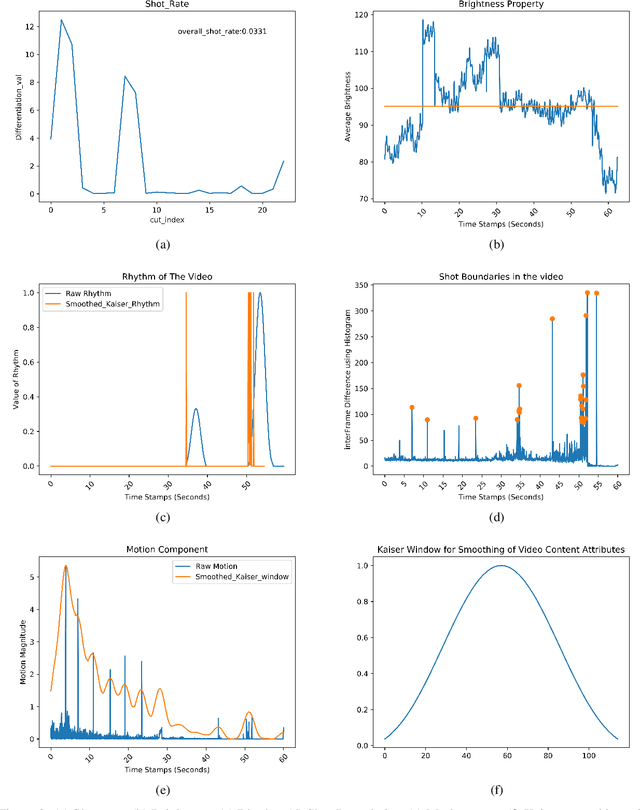
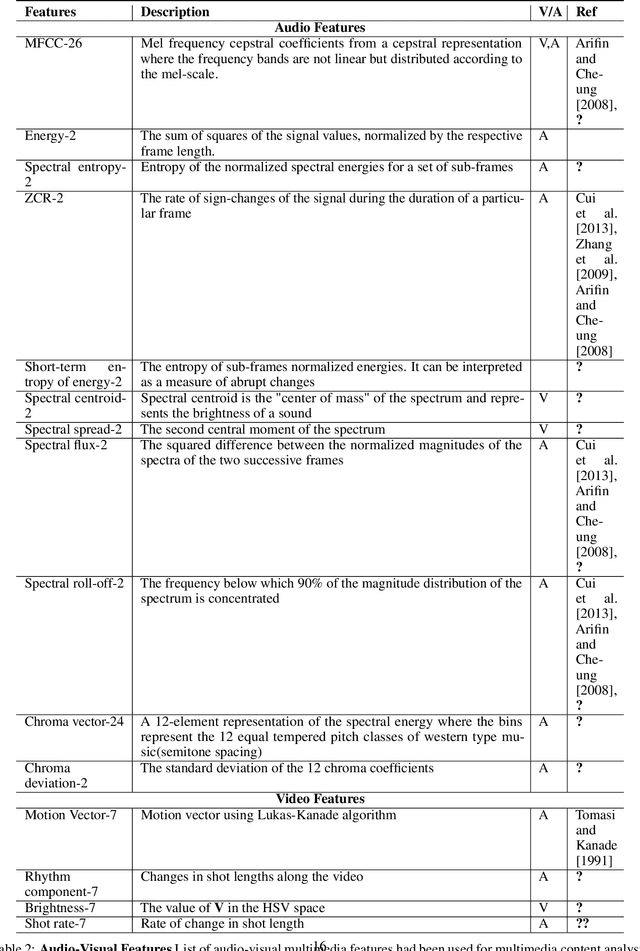
Availability of naturalistic affective stimuli is needed for creating the affective technological solution as well as making progress in affective science. Although a lot of progress in the collection of affective multimedia stimuli has been made in western countries, the technology and findings based on such monocultural datasets may not be scalable to other cultures. Moreover, the available dataset on affective multimedia content has some experimenter bias in the initial manual selection of affective multimedia content. Hence, in this work, we mainly tried to address two problems. The first problem relates to the experimenter's subjective bias, and the second relates to the non-availability of affective multimedia dataset validated on Indian population. We tried to address both problems by reducing the experimenter's bias as much as possible. We adopted the data science and multimedia content analysis techniques to perform our initial collection and a further selection of stimuli. Our method resulted in a dataset with a wide variety in content, stimuli from Western and Indian cinema, and symmetric presence of stimuli along valence, arousal and dominance dimensions. We conclude that using our method, more cross-cultural affective stimuli datasets can be created, which is essential to make progress in affective technology and science.