 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelector-Guided Autonomous Curriculum for One-Shot Reinforcement Learning from Verifiable Rewards
May 03, 2026Recently, Reinforcement Learning from Verifiable Rewards (RLVR) has been established as a highly effective technique for augmenting the math reasoning skills of Large Language Models (LLMs) based on a single instance. Current state-of-the-art 1-shot RLVR models adopt heuristics for selecting instances, mostly based on historical variance in rewards, which we find to be inherently misleading as a measure of transferability value. In this paper, we propose a Selector-Guided Autonomous Curriculum (SGAC) approach, which employs a learnable selector model on a multi-dimensional feature space consisting of success probability, reward variance, output disagreement (entropy), and semantic difficulty level, instead of the static reward variance heuristic. In our empirical evaluation on pools of candidate problems, we observed that output disagreement, rather than reward variance, is the strongest predictor of reasoning gains in subsequent iterations. Leveraging this finding, we develop an autonomous curriculum algorithm for dynamically siphoning candidate problems from a large pool, ranking them by the learned selector, and running micro-bursts of 1-shot GRPO. Our framework is evaluated using the Hendrycks MATH benchmark, with the Qwen2.5-Math-1.5B model serving as the baseline. Our framework obtains an accuracy of 68.0\% on the hold-out dataset, which is better than the accuracy obtained from the state-of-the-art model, 64.0\%, as well as the 1-shot RLVR checkpoint proposed by Wang et al., which achieved an accuracy of 66.0\%. The results confirm that entropy-based intelligent data curation leads to strict reasoning improvement over static training methods, particularly in severely limited data conditions.
Proactive Emotion Tracker: AI-Driven Continuous Mood and Emotion Monitoring
Jan 24, 2024This research project aims to tackle the growing mental health challenges in today's digital age. It employs a modified pre-trained BERT model to detect depressive text within social media and users' web browsing data, achieving an impressive 93% test accuracy. Simultaneously, the project aims to incorporate physiological signals from wearable devices, such as smartwatches and EEG sensors, to provide long-term tracking and prognosis of mood disorders and emotional states. This comprehensive approach holds promise for enhancing early detection of depression and advancing overall mental health outcomes.
Emotion Recognition With Temporarily Localized 'Emotional Events' in Naturalistic Context
Oct 25, 2022



Emotion recognition using EEG signals is an emerging area of research due to its broad applicability in BCI. Emotional feelings are hard to stimulate in the lab. Emotions do not last long, yet they need enough context to be perceived and felt. However, most EEG-related emotion databases either suffer from emotionally irrelevant details (due to prolonged duration stimulus) or have minimal context doubting the feeling of any emotion using the stimulus. We tried to reduce the impact of this trade-off by designing an experiment in which participants are free to report their emotional feelings simultaneously watching the emotional stimulus. We called these reported emotional feelings "Emotional Events" in our Dataset on Emotion with Naturalistic Stimuli (DENS). We used EEG signals to classify emotional events on different combinations of Valence(V) and Arousal(A) dimensions and compared the results with benchmark datasets of DEAP and SEED. STFT is used for feature extraction and used in the classification model consisting of CNN-LSTM hybrid layers. We achieved significantly higher accuracy with our data compared to DEEP and SEED data. We conclude that having precise information about emotional feelings improves the classification accuracy compared to long-duration EEG signals which might be contaminated by mind-wandering.
An Affective Video Database using Multimedia Content Analysis rated on Indian samples
Oct 18, 2022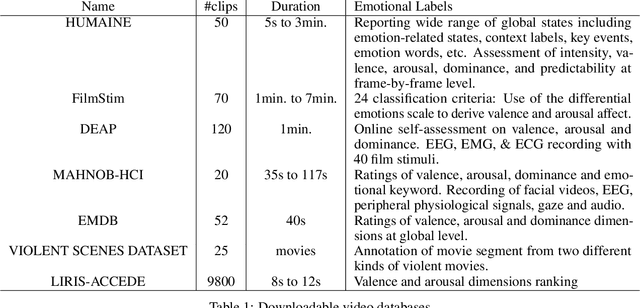
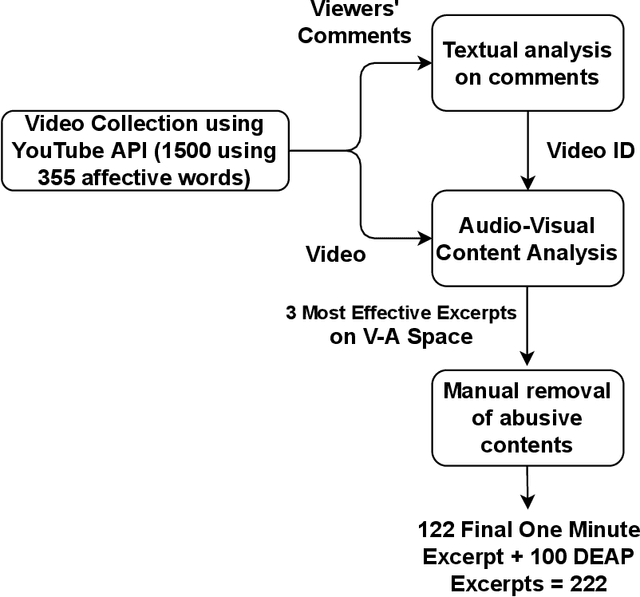
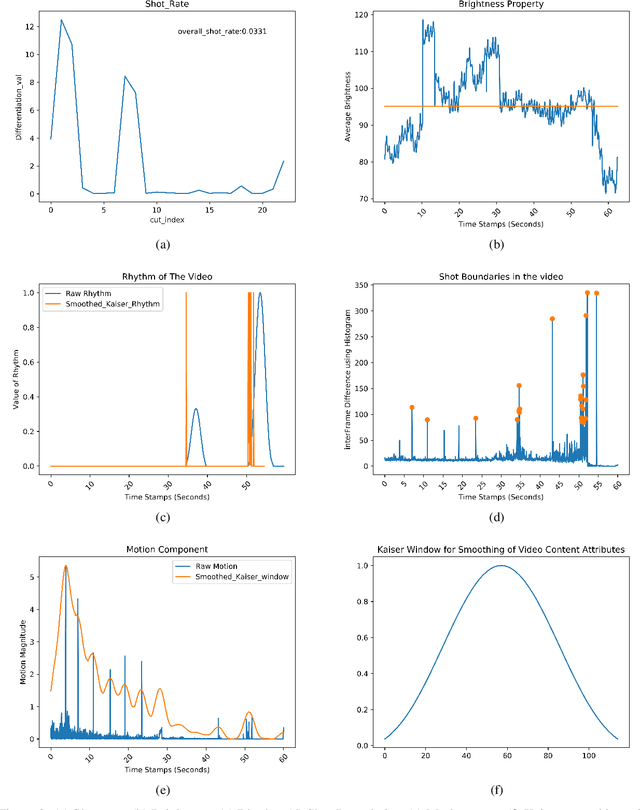
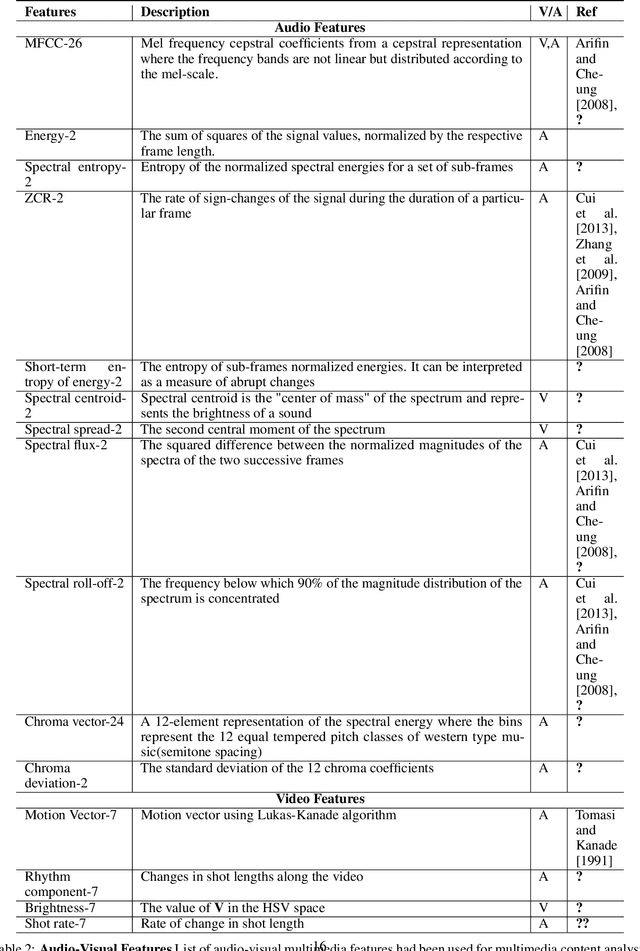
Availability of naturalistic affective stimuli is needed for creating the affective technological solution as well as making progress in affective science. Although a lot of progress in the collection of affective multimedia stimuli has been made in western countries, the technology and findings based on such monocultural datasets may not be scalable to other cultures. Moreover, the available dataset on affective multimedia content has some experimenter bias in the initial manual selection of affective multimedia content. Hence, in this work, we mainly tried to address two problems. The first problem relates to the experimenter's subjective bias, and the second relates to the non-availability of affective multimedia dataset validated on Indian population. We tried to address both problems by reducing the experimenter's bias as much as possible. We adopted the data science and multimedia content analysis techniques to perform our initial collection and a further selection of stimuli. Our method resulted in a dataset with a wide variety in content, stimuli from Western and Indian cinema, and symmetric presence of stimuli along valence, arousal and dominance dimensions. We conclude that using our method, more cross-cultural affective stimuli datasets can be created, which is essential to make progress in affective technology and science.