 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepeat and Concatenate: 2D to 3D Image Translation with 3D to 3D Generative Modeling
Jun 26, 2024



This paper investigates a 2D to 3D image translation method with a straightforward technique, enabling correlated 2D X-ray to 3D CT-like reconstruction. We observe that existing approaches, which integrate information across multiple 2D views in the latent space, lose valuable signal information during latent encoding. Instead, we simply repeat and concatenate the 2D views into higher-channel 3D volumes and approach the 3D reconstruction challenge as a straightforward 3D to 3D generative modeling problem, sidestepping several complex modeling issues. This method enables the reconstructed 3D volume to retain valuable information from the 2D inputs, which are passed between channel states in a Swin UNETR backbone. Our approach applies neural optimal transport, which is fast and stable to train, effectively integrating signal information across multiple views without the requirement for precise alignment; it produces non-collapsed reconstructions that are highly faithful to the 2D views, even after limited training. We demonstrate correlated results, both qualitatively and quantitatively, having trained our model on a single dataset and evaluated its generalization ability across six datasets, including out-of-distribution samples.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023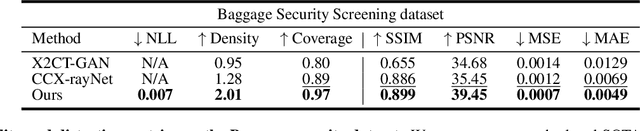
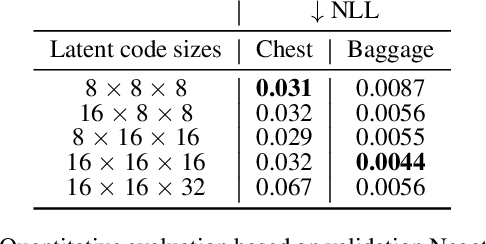

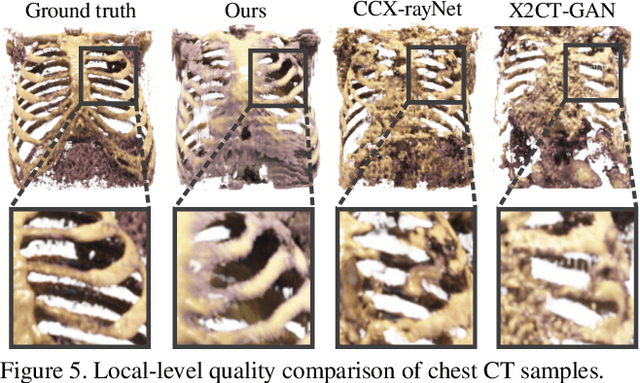
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
MedNeRF: Medical Neural Radiance Fields for Reconstructing 3D-aware CT-Projections from a Single X-ray
Feb 02, 2022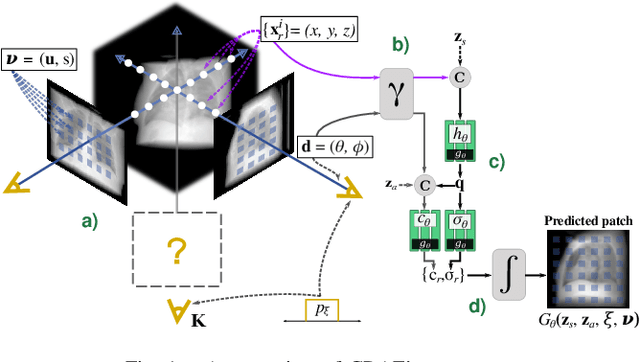
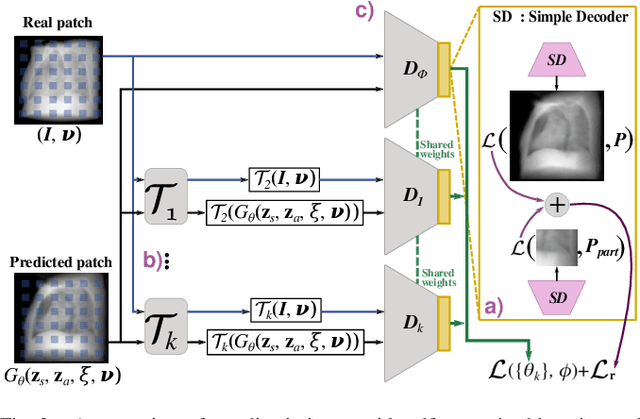
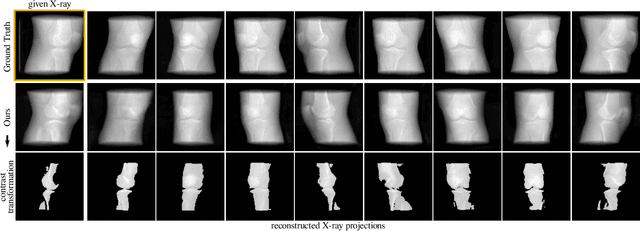
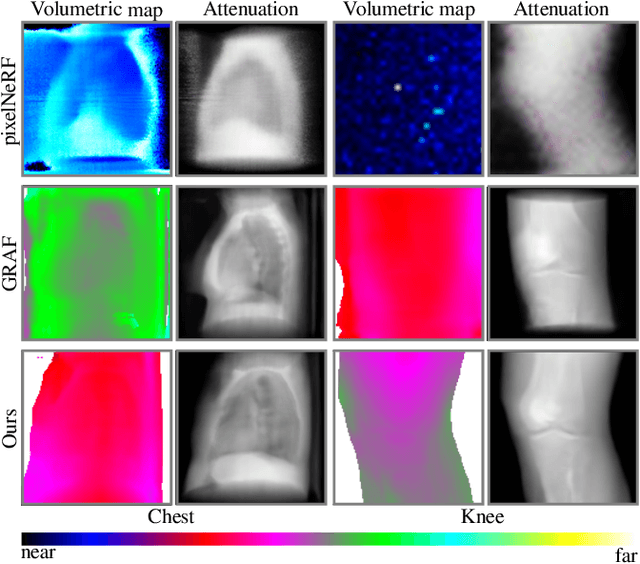
Computed tomography (CT) is an effective medical imaging modality, widely used in the field of clinical medicine for the diagnosis of various pathologies. Advances in Multidetector CT imaging technology have enabled additional functionalities, including generation of thin slice multiplanar cross-sectional body imaging and 3D reconstructions. However, this involves patients being exposed to a considerable dose of ionising radiation. Excessive ionising radiation can lead to deterministic and harmful effects on the body. This paper proposes a Deep Learning model that learns to reconstruct CT projections from a few or even a single-view X-ray. This is based on a novel architecture that builds from neural radiance fields, which learns a continuous representation of CT scans by disentangling the shape and volumetric depth of surface and internal anatomical structures from 2D images. Our model is trained on chest and knee datasets, and we demonstrate qualitative and quantitative high-fidelity renderings and compare our approach to other recent radiance field-based methods. Our code and link to our datasets will be available at our GitHub.