 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-World Object-based Anomaly Detection via Self-Supervised Outlier Synthesis
Jul 22, 2024Object detection is a pivotal task in computer vision that has received significant attention in previous years. Nonetheless, the capability of a detector to localise objects out of the training distribution remains unexplored. Whilst recent approaches in object-level out-of-distribution (OoD) detection heavily rely on class labels, such approaches contradict truly open-world scenarios where the class distribution is often unknown. In this context, anomaly detection focuses on detecting unseen instances rather than classifying detections as OoD. This work aims to bridge this gap by leveraging an open-world object detector and an OoD detector via virtual outlier synthesis. This is achieved by using the detector backbone features to first learn object pseudo-classes via self-supervision. These pseudo-classes serve as the basis for class-conditional virtual outlier sampling of anomalous features that are classified by an OoD head. Our approach empowers our overall object detector architecture to learn anomaly-aware feature representations without relying on class labels, hence enabling truly open-world object anomaly detection. Empirical validation of our approach demonstrates its effectiveness across diverse datasets encompassing various imaging modalities (visible, infrared, and X-ray). Moreover, our method establishes state-of-the-art performance on object-level anomaly detection, achieving an average recall score improvement of over 5.4% for natural images and 23.5% for a security X-ray dataset compared to the current approaches. In addition, our method detects anomalies in datasets where current approaches fail. Code available at https://github.com/KostadinovShalon/oln-ssos.
Performance Evaluation of Segment Anything Model with Variational Prompting for Application to Non-Visible Spectrum Imagery
Apr 18, 2024



The Segment Anything Model (SAM) is a deep neural network foundational model designed to perform instance segmentation which has gained significant popularity given its zero-shot segmentation ability. SAM operates by generating masks based on various input prompts such as text, bounding boxes, points, or masks, introducing a novel methodology to overcome the constraints posed by dataset-specific scarcity. While SAM is trained on an extensive dataset, comprising ~11M images, it mostly consists of natural photographic images with only very limited images from other modalities. Whilst the rapid progress in visual infrared surveillance and X-ray security screening imaging technologies, driven forward by advances in deep learning, has significantly enhanced the ability to detect, classify and segment objects with high accuracy, it is not evident if the SAM zero-shot capabilities can be transferred to such modalities. This work assesses SAM capabilities in segmenting objects of interest in the X-ray/infrared modalities. Our approach reuses the pre-trained SAM with three different prompts: bounding box, centroid and random points. We present quantitative/qualitative results to showcase the performance on selected datasets. Our results show that SAM can segment objects in the X-ray modality when given a box prompt, but its performance varies for point prompts. Specifically, SAM performs poorly in segmenting slender objects and organic materials, such as plastic bottles. We find that infrared objects are also challenging to segment with point prompts given the low-contrast nature of this modality. This study shows that while SAM demonstrates outstanding zero-shot capabilities with box prompts, its performance ranges from moderate to poor for point prompts, indicating that special consideration on the cross-modal generalisation of SAM is needed when considering use on X-ray/infrared imagery.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023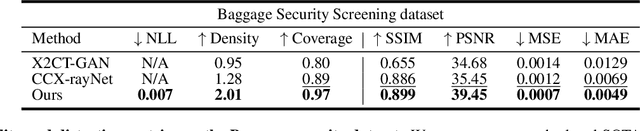
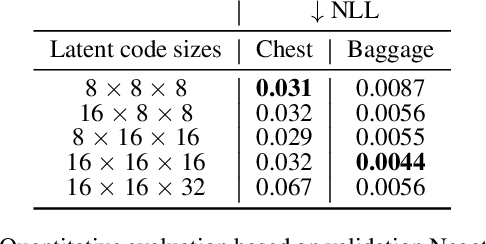

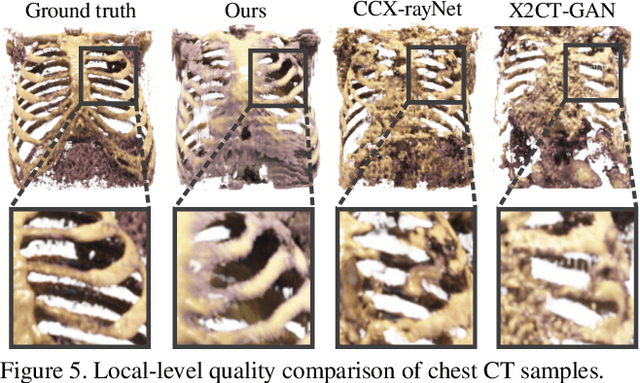
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
Lost in Compression: the Impact of Lossy Image Compression on Variable Size Object Detection within Infrared Imagery
May 16, 2022



Lossy image compression strategies allow for more efficient storage and transmission of data by encoding data to a reduced form. This is essential enable training with larger datasets on less storage-equipped environments. However, such compression can cause severe decline in performance of deep Convolution Neural Network (CNN) architectures even when mild compression is applied and the resulting compressed imagery is visually identical. In this work, we apply the lossy JPEG compression method with six discrete levels of increasing compression {95, 75, 50, 15, 10, 5} to infrared band (thermal) imagery. Our study quantitatively evaluates the affect that increasing levels of lossy compression has upon the performance of characteristically diverse object detection architectures (Cascade-RCNN, FSAF and Deformable DETR) with respect to varying sizes of objects present in the dataset. When training and evaluating on uncompressed data as a baseline, we achieve maximal mean Average Precision (mAP) of 0.823 with Cascade R-CNN across the FLIR dataset, outperforming prior work. The impact of the lossy compression is more extreme at higher compression levels (15, 10, 5) across all three CNN architectures. However, re-training models on lossy compressed imagery notably ameliorated performances for all three CNN models with an average increment of ~76% (at higher compression level 5). Additionally, we demonstrate the relative sensitivity of differing object areas {tiny, small, medium, large} with respect to the compression level. We show that tiny and small objects are more sensitive to compression than medium and large objects. Overall, Cascade R-CNN attains the maximal mAP across most of the object area categories.
Operationalizing Convolutional Neural Network Architectures for Prohibited Object Detection in X-Ray Imagery
Oct 10, 2021
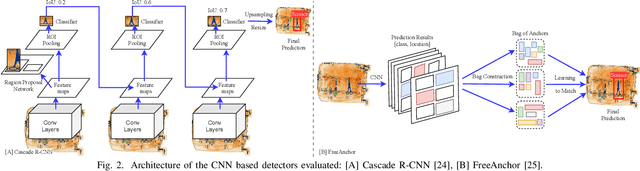


The recent advancement in deep Convolutional Neural Network (CNN) has brought insight into the automation of X-ray security screening for aviation security and beyond. Here, we explore the viability of two recent end-to-end object detection CNN architectures, Cascade R-CNN and FreeAnchor, for prohibited item detection by balancing processing time and the impact of image data compression from an operational viewpoint. Overall, we achieve maximal detection performance using a FreeAnchor architecture with a ResNet50 backbone, obtaining mean Average Precision (mAP) of 87.7 and 85.8 for using the OPIXray and SIXray benchmark datasets, showing superior performance over prior work on both. With fewer parameters and less training time, FreeAnchor achieves the highest detection inference speed of ~13 fps (3.9 ms per image). Furthermore, we evaluate the impact of lossy image compression upon detector performance. The CNN models display substantial resilience to the lossy compression, resulting in only a 1.1% decrease in mAP at the JPEG compression level of 50. Additionally, a thorough evaluation of data augmentation techniques is provided, including adaptions of MixUp and CutMix strategy as well as other standard transformations, further improving the detection accuracy.
On the impact of using X-ray energy response imagery for object detection via Convolutional Neural Networks
Aug 27, 2021



Automatic detection of prohibited items within complex and cluttered X-ray security imagery is essential to maintaining transport security, where prior work on automatic prohibited item detection focus primarily on pseudo-colour (rgb}) X-ray imagery. In this work we study the impact of variant X-ray imagery, i.e., X-ray energy response (high, low}) and effective-z compared to rgb, via the use of deep Convolutional Neural Networks (CNN) for the joint object detection and segmentation task posed within X-ray baggage security screening. We evaluate state-of-the-art CNN architectures (Mask R-CNN, YOLACT, CARAFE and Cascade Mask R-CNN) to explore the transferability of models trained with such 'raw' variant imagery between the varying X-ray security scanners that exhibits differing imaging geometries, image resolutions and material colour profiles. Overall, we observe maximal detection performance using CARAFE, attributable to training using combination of rgb, high, low, and effective-z X-ray imagery, obtaining 0.7 mean Average Precision (mAP) for a six class object detection problem. Our results also exhibit a remarkable degree of generalisation capability in terms of cross-scanner transferability (AP: 0.835/0.611) for a one class object detection problem by combining rgb, high, low, and effective-z imagery.
Evaluating the Transferability and Adversarial Discrimination of Convolutional Neural Networks for Threat Object Detection and Classification within X-Ray Security Imagery
Nov 20, 2019


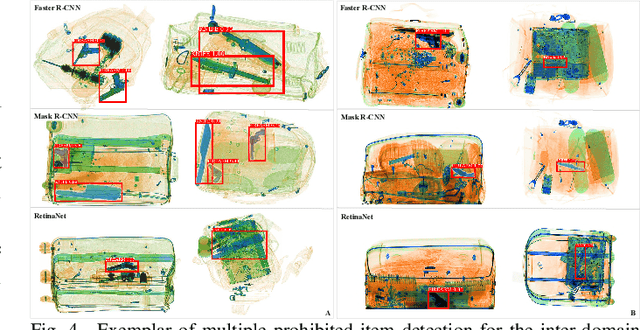
X-ray imagery security screening is essential to maintaining transport security against a varying profile of threat or prohibited items. Particular interest lies in the automatic detection and classification of weapons such as firearms and knives within complex and cluttered X-ray security imagery. Here, we address this problem by exploring various end-to-end object detection Convolutional Neural Network (CNN) architectures. We evaluate several leading variants spanning the Faster R-CNN, Mask R-CNN, and RetinaNet architectures to explore the transferability of such models between varying X-ray scanners with differing imaging geometries, image resolutions and material colour profiles. Whilst the limited availability of X-ray threat imagery can pose a challenge, we employ a transfer learning approach to evaluate whether such inter-scanner generalisation may exist over a multiple class detection problem. Overall, we achieve maximal detection performance using a Faster R-CNN architecture with a ResNet$_{101}$ classification network, obtaining 0.88 and 0.86 of mean Average Precision (mAP) for a three-class and two class item from varying X-ray imaging sources. Our results exhibit a remarkable degree of generalisability in terms of cross-scanner performance (mAP: 0.87, firearm detection: 0.94 AP). In addition, we examine the inherent adversarial discriminative capability of such networks using a specifically generated adversarial dataset for firearms detection - with a variable low false positive, as low as 5%, this shows both the challenge and promise of such threat detection within X-ray security imagery.
On the Impact of Object and Sub-component Level Segmentation Strategies for Supervised Anomaly Detection within X-ray Security Imagery
Nov 19, 2019


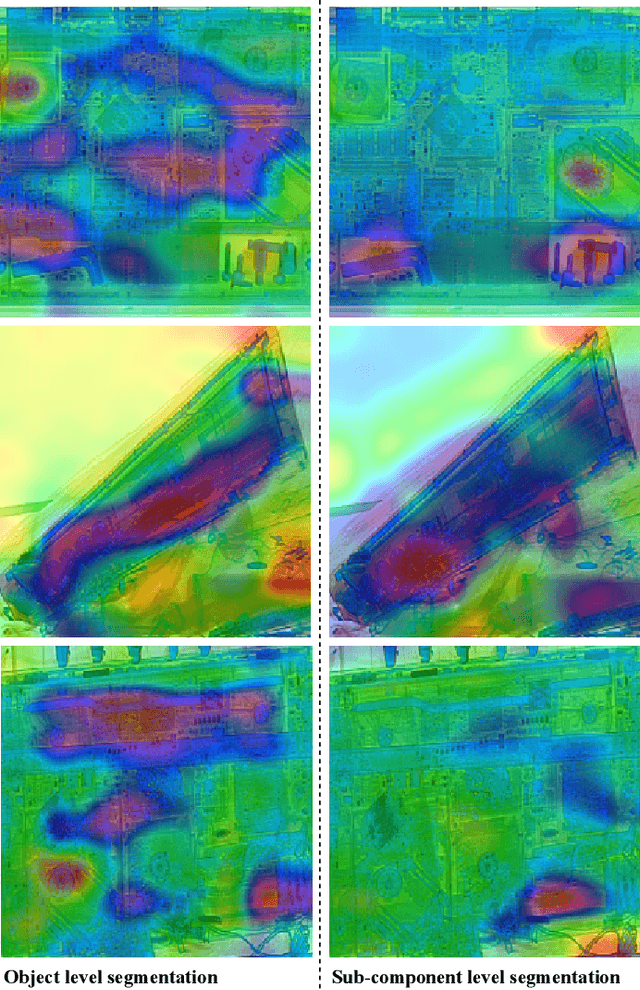
X-ray security screening is in widespread use to maintain transportation security against a wide range of potential threat profiles. Of particular interest is the recent focus on the use of automated screening approaches, including the potential anomaly detection as a methodology for concealment detection within complex electronic items. Here we address this problem considering varying segmentation strategies to enable the use of both object level and sub-component level anomaly detection via the use of secondary convolutional neural network (CNN) architectures. Relative performance is evaluated over an extensive dataset of exemplar cluttered X-ray imagery, with a focus on consumer electronics items. We find that sub-component level segmentation produces marginally superior performance in the secondary anomaly detection via classification stage, with true positive of ~98% of anomalies, with a ~3% false positive.
The Good, the Bad and the Ugly: Evaluating Convolutional Neural Networks for Prohibited Item Detection Using Real and Synthetically Composited X-ray Imagery
Sep 25, 2019
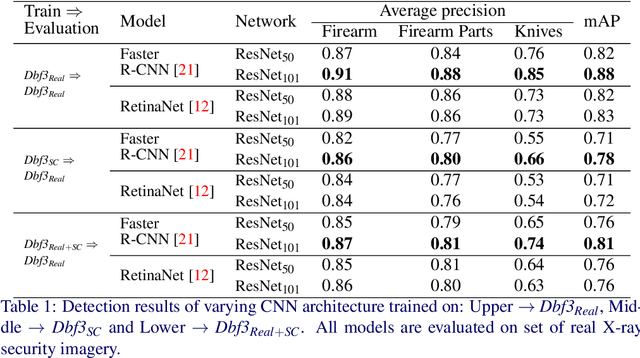


Detecting prohibited items in X-ray security imagery is pivotal in maintaining border and transport security against a wide range of threat profiles. Convolutional Neural Networks (CNN) with the support of a significant volume of data have brought advancement in such automated prohibited object detection and classification. However, collating such large volumes of X-ray security imagery remains a significant challenge. This work opens up the possibility of using synthetically composed imagery, avoiding the need to collate such large volumes of hand-annotated real-world imagery. Here we investigate the difference in detection performance achieved using real and synthetic X-ray training imagery for CNN architecture detecting three exemplar prohibited items, {Firearm, Firearm Parts, Knives}, within cluttered and complex X-ray security baggage imagery. We achieve 0.88 of mean average precision (mAP) with a Faster R-CNN and ResNet-101 CNN architecture for this 3-class object detection using real X-ray imagery. While the performance is comparable with synthetically composited X-ray imagery (0.78 mAP), our extended evaluation demonstrates both challenge and promise of using synthetically composed images to diversify the X-ray security training imagery for automated detection algorithm training.
Evaluation of a Dual Convolutional Neural Network Architecture for Object-wise Anomaly Detection in Cluttered X-ray Security Imagery
Apr 10, 2019
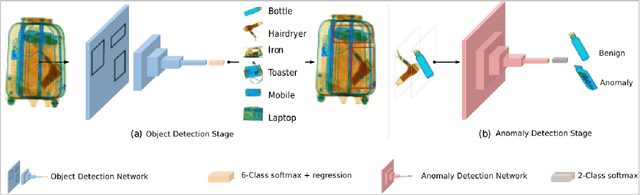
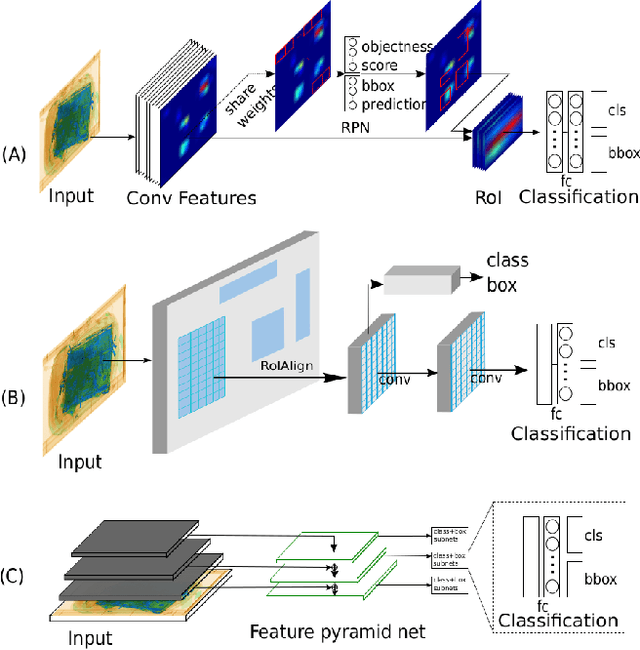
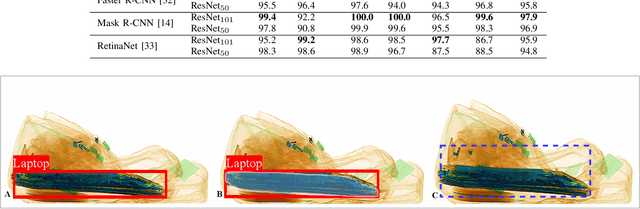
X-ray baggage security screening is widely used to maintain aviation and transport security. Of particular interest is the focus on automated security X-ray analysis for particular classes of object such as electronics, electrical items, and liquids. However, manual inspection of such items is challenging when dealing with potentially anomalous items. Here we present a dual convolutional neural network (CNN) architecture for automatic anomaly detection within complex security X-ray imagery. We leverage recent advances in region-based (R-CNN), mask-based CNN (Mask R-CNN) and detection architectures such as RetinaNet to provide object localisation variants for specific object classes of interest. Subsequently, leveraging a range of established CNN object and fine-grained category classification approaches we formulate within object anomaly detection as a two-class problem (anomalous or benign). While the best performing object localisation method is able to perform with 97.9% mean average precision (mAP) over a six-class X-ray object detection problem, subsequent two-class anomaly/benign classification is able to achieve 66% performance for within object anomaly detection. Overall, this performance illustrates both the challenge and promise of object-wise anomaly detection within the context of cluttered X-ray security imagery.